






背景介绍
在之前的文章详细梳理过工业界的 RAG 方案 [QAnything] 和 [RagFlow],这次主要整理下来自学术界的一系列 RAG 优化方案。
主要关注优化方案对应的设计思想以及相关的实现,希望可以对大家的 RAG 服务效果提升有所帮助。
基础介绍
在综述论文 [Retrieval-Augmented Generation for Large Language Models: A Survey]介绍了三种不同的 RAG 架构:
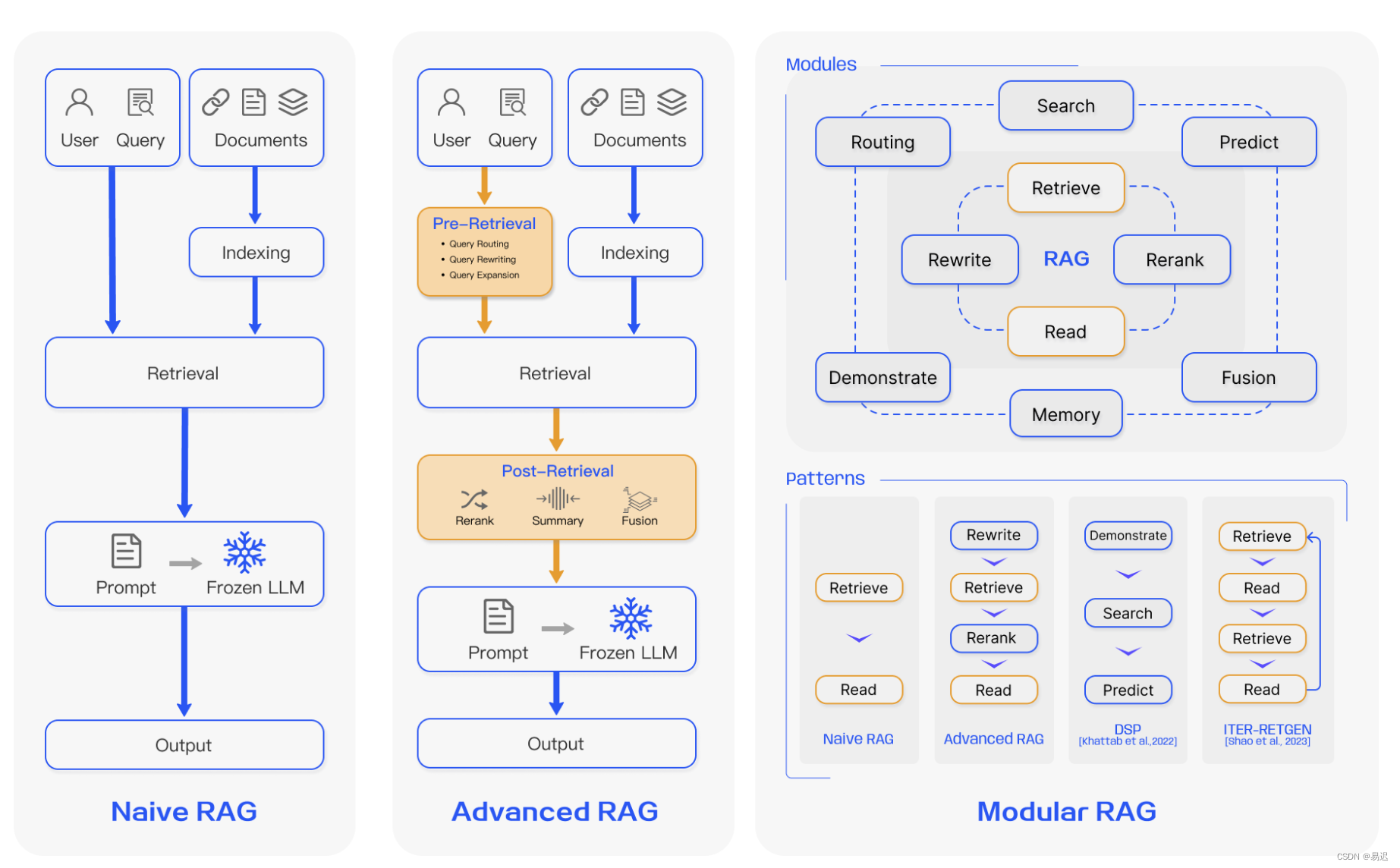
- Native RAG: 原始 RAG 架构,对应最原始的 RAG 流程,和之前 [搭建离线私有大模型知识库] 介绍的流程基本一致;
- Advanced RAG:高级 RAG 架构,在原始 RAG 上增加了一些优化手段,之前实践过的 [RAG Rerank] 优化手段就属于高级 RAG 中的 Post-Retrieval (检索后的优化);
- Modular RAG:模块化 RAG 架构,通过模块化的架构设计,可以提供灵活的功能组合,方便实现功能强大的 RAG 服务。
本篇文章主要实践的还是高级 RAG 架构中的优化手段,涉及的时是之前较少涉及的 Pre-Retrieval(检索前的优化),目前有大量相关论文的研究,目前主要选择其中几种有代表性的方案进行实践,所有的实现都是基于 langchain 完成的。
优化方案
HyDE
HyDE 的优化手段来自于论文 [Precise Zero-Shot Dense Retrieval without Relevance Labels],主要流程如下所示:
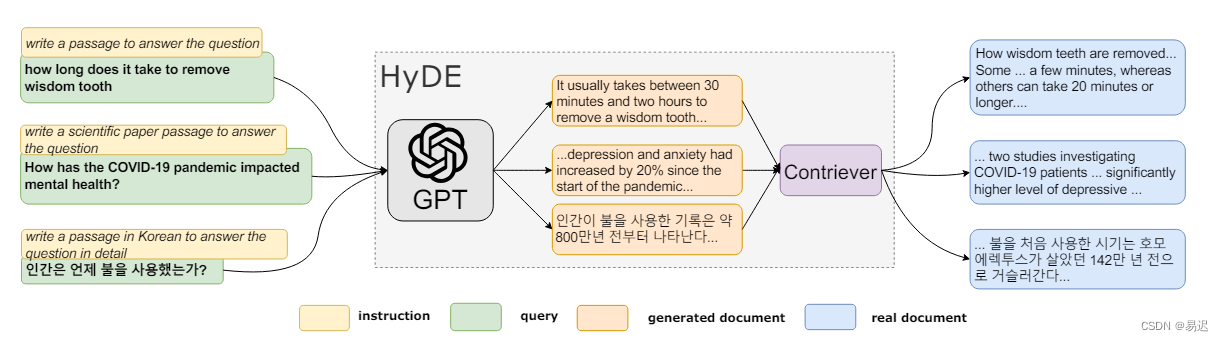
用户原始的问题与需要检索文档的向量相似度上不接近,因此向量检索效果不佳。因此 HyDE 的设计思想如下:
- 根据原始问题使用大模型生成假设文档,可以理解为使用大模型先给出答案,此答案中可能存在幻觉;
- 基于生成的假设文档进行向量检索;
为什么假设文档检索的效果会好于通过问题检索呢?我直观理解下来就是与大模型的答案语义上接近的更有可能是所需的答案,而且大模型是通过大量原始文档学习出来,因此生成的假设文档与原始文档上更接近,因此更易于检索。
实现方案
HyDE 的实现在 langchain 已经支持了,可以通过 from langchain.chains import hyde 进行使用,提供的是一个向量化查询的转换支持,可以看到其中最核心的方法如下所示:
def embed_query(self, text: str) -> List[float]:
"""Generate a hypothetical document and embedded it."""
# 通过大模型生成文本对应的响应
var_name = self.llm_chain.input_keys[0]
result = self.llm_chain.generate([{var_name: text}])
documents = [generation.text for generation in result.generations[0]]
# 文档向量化
embeddings = self.embed_documents(documents)
return self.combine_embeddings(embeddings)
熟悉 langchain 的研发同学应该都了解这个方法的用途,主要是用于将原始文本向量化,方便进行后续的向量检索。
常规的文本向量化是直接调用下面的 self.embed_documents() 将原始查询 text 向量化。但是在 HyDE 中会增加一个大模型生成回答的流程 self.llm_chain.generate([{var_name: text}]),接下来将大模型的回答向量化,并使用此向量进行检索。
接下来可以看看 HyDE 中使用 prompt,这部分可以在 from langchain.chains.hyde import prompts 中看到,看起来是根据不同场景设计了不同的 prompt。我们以 web_search 为例,对应的应该是文本搜索的场景,prompt 如下所示:
from langchain_core.prompts.prompt import PromptTemplate
web_search_template = """Please write a passage to answer the question
Question: {QUESTION}
Passage:"""
web_search = PromptTemplate(template=web_search_template, input_variables=["QUESTION"])
可以看到 prompt 也相对简单容易理解。
实践效果
理想很丰满,实践下来发现 HyDE 实际效果不佳,实际测试中大模型给出的响应与原始知识库中的文档表达形式并不接近,导致最终测试时原始 query 可以检索到部分相关文档,使用大模型给出的回答进行检索则完全检索不到任何内容。
目前来看,HyDE 在大模型可以给出与文档类似的表达形式的内容时可能会有一些效果。预期对大模型的选型和使用场景上都有明显要求,使用不当可能会导致效果更差。
Rewrite-Retrieve-Read
Rewrite-Retrieve-Read 的想法来自于 [Query Rewriting for Retrieval-Augmented Large Language Models
],对应的流程如下所示:
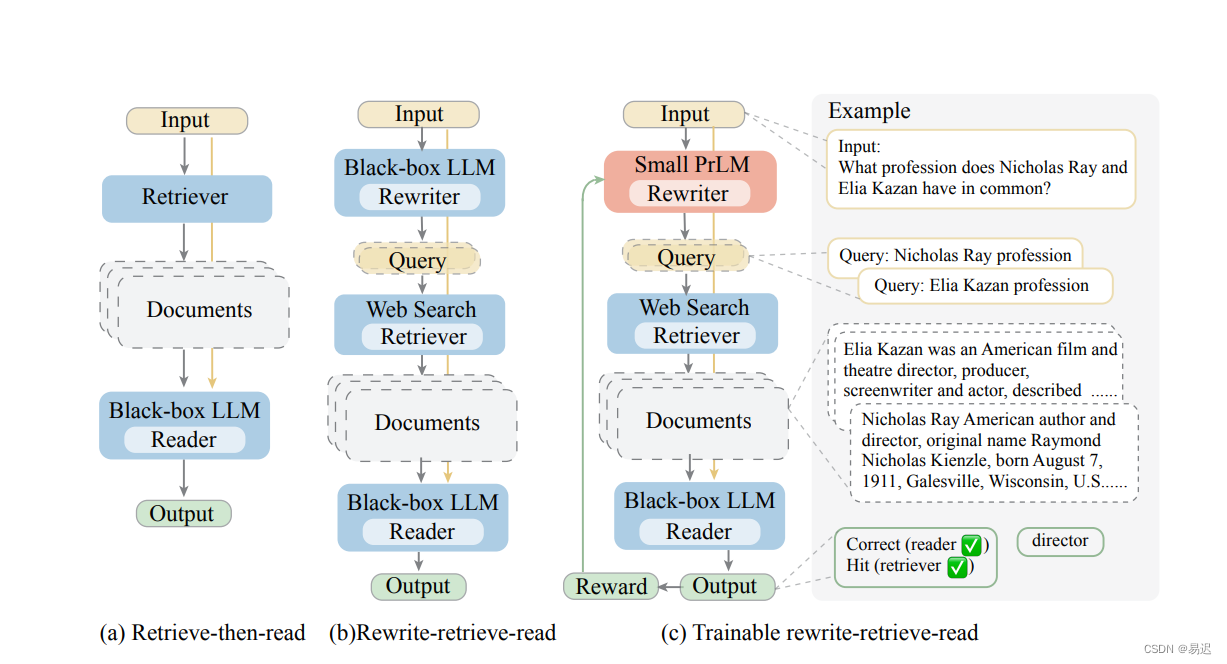
此方法的主要思想是用户的原始问题检索效果不佳,通过大模型进行重写提升问题对应的检索能力。
有实际上线 RAG 服务的应该有类似的遭遇,用户的问题都是千奇百怪的,确实存在原始问题检索效果不佳的情况,Rewrite-Retrieve-Read 就是基于大模型提供的能力进行了重写。
实现方案
Rewrite-Retrieve-Read 的实现方案相对简单,使用大模型直接重写问题,对应的实现可以参考 [langchain template]
核心的功能如下所示:
template = """Provide a better search query for \
web search engine to answer the given question, end \
the queries with ’**’. Question: \
{x} Answer:"""
rewrite_prompt = ChatPromptTemplate.from_template(template)
def _parse(text):
return text.strip("**")
rewriter = rewrite_prompt | ChatOpenAI(temperature=0) | StrOutputParser() | _parse
可以看到 langchain 中设计了一个特殊的 prompt 进行了原始问题的转换,思路相对简单。
实践效果
最终实际测试下来,效果不是特别问题,部分问题转换后的效果更好,部分效果更差,从目前来看,与大模型本身的能力存在较大关系。
Query2Doc
Query2Doc 的想法来自于 [Query2doc: Query Expansion with Large Language Models],是在 HyDE 的想法上进行了一些提升。
原始的 HyDE 是使用大模型生成的答案(Hypothetical Document)进行检索,而 Query2Doc 则会将生成的答案与原始问题进行拼接,之后使用拼接得到的内容进行检索。
针对不同的检索方案拼接方案有所差异,其中稀疏检索的中的拼接方案如下所示:
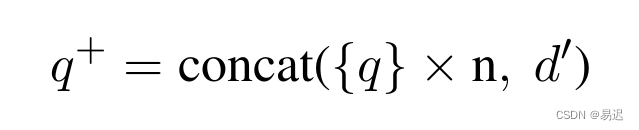
其中的 q 为原始问题,d 为生成的回答,可以看到 q 会被重复 n 次,并与 d 拼接起来。
而密集检索的拼接方案如下所示:
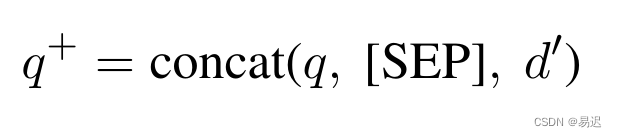
可以看到是直接将原始问题 q 与大模型生成的回答 d 进行了拼接,中间使用分隔符 [SEP] 进行了分隔。
实现方案
可以参考 HyDE 进行简单调整即可实现 Query2Doc,简单的示例如下所示:
def embed_query(self, text: str) -> List[float]:
"""Generate a hypothetical document and embedded it."""
# 通过大模型生成文本对应的响应
var_name = self.llm_chain.input_keys[0]
result = self.llm_chain.generate([{var_name: text}])
documents = [generation.text for generation in result.generations[0]]
# 拼接原始查询与生成的响应,使用空格作为分隔符 SEP
documents = [f"{text} {doc}" for doc in documents]
# 文档向量化
embeddings = self.embed_documents(documents)
return self.combine_embeddings(embeddings)
实践效果
实际测试下来,相对原始的 HyDE 方案效果更好,但是实际效果改善不明显。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









