







背景介绍
在之前的文章详细梳理过工业界的 RAG 方案 QAnything 和 RagFlow,这次主要整理下来自学术界的一系列 RAG 优化方案。
主要关注优化方案对应的设计思想以及相关的实现,希望可以对大家的 RAG 服务效果提升有所帮助。
基础介绍
在综述论文 Retrieval-Augmented Generation for Large Language Models: A Survey 介绍了三种不同的 RAG 架构:
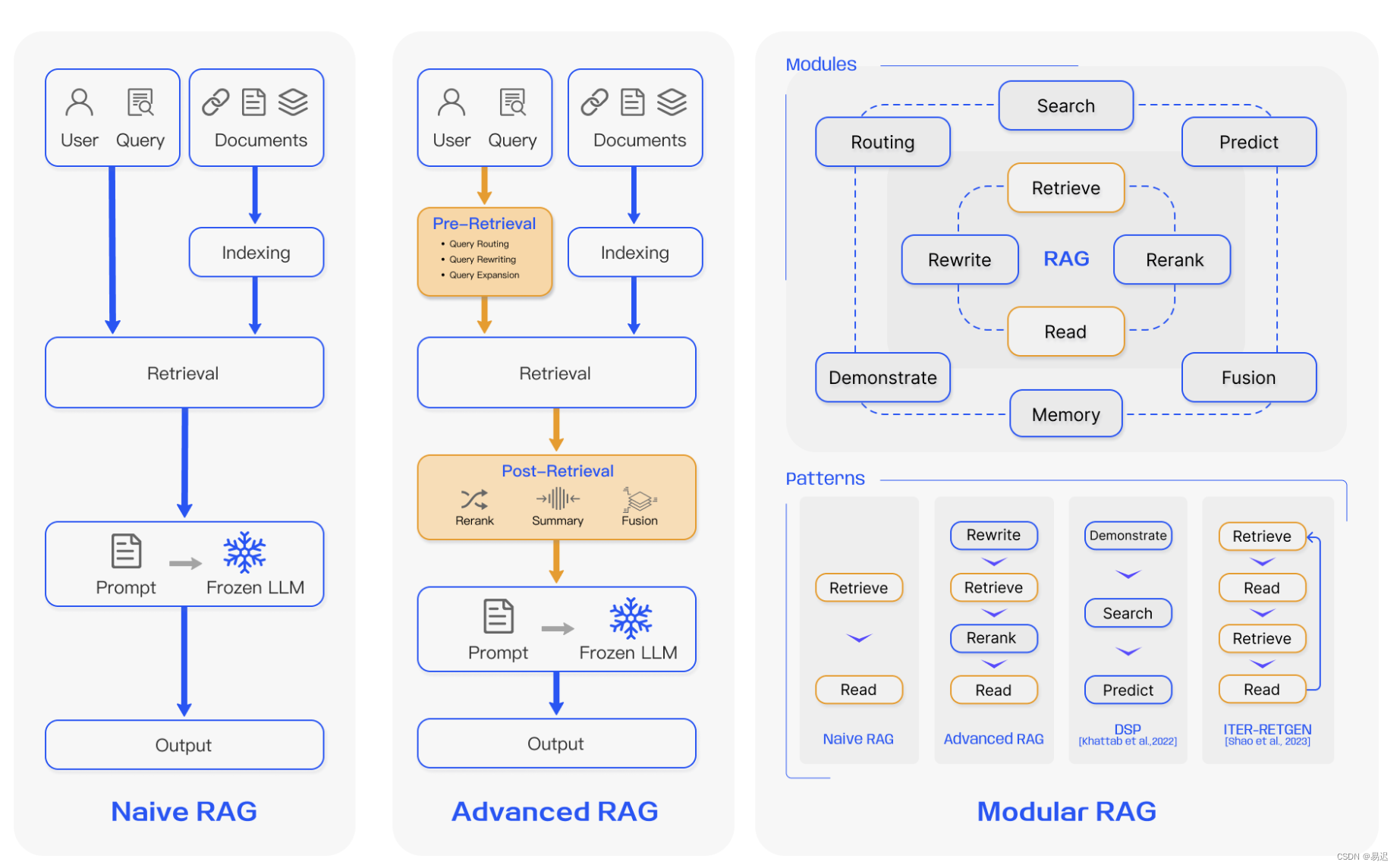
- Native RAG: 原始 RAG 架构,对应最原始的 RAG 流程,和之前 搭建离线私有大模型知识库 介绍的流程基本一致;
- Advanced RAG:高级 RAG 架构,在原始 RAG 上增加了一些优化手段,之前实践过的 RAG Rerank 优化手段就属于高级 RAG 中的 Post-Retrieval (检索后的优化);
- Modular RAG:模块化 RAG 架构,通过模块化的架构设计,可以提供灵活的功能组合,方便实现功能强大的 RAG 服务。
本篇文章主要实践的还是高级 RAG 架构中的优化手段,涉及的时是之前较少涉及的 Pre-Retrieval(检索前的优化),目前有大量相关论文的研究,目前主要选择其中几种有代表性的方案进行实践,所有的实现都是基于 langchain 完成的。
优化方案
HyDE
HyDE 的优化手段来自于论文 Precise Zero-Shot Dense Retrieval without Relevance Labels,主要流程如下所示:
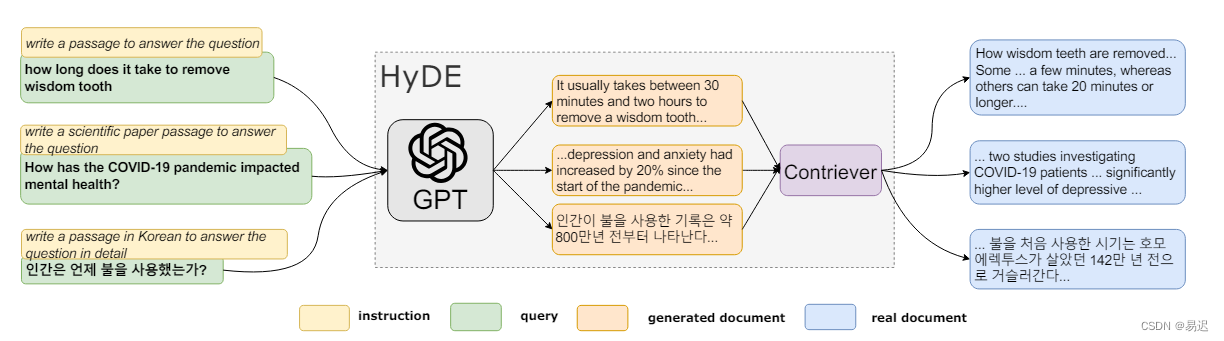
用户原始的问题与需要检索文档的向量相似度上不接近,因此向量检索效果不佳。因此 HyDE 的设计思想如下:
- 根据原始问题使用大模型生成假设文档,可以理解为使用大模型先给出答案,此答案中可能存在幻觉;
- 基于生成的假设文档进行向量检索;
为什么假设文档检索的效果会好于通过问题检索呢?我直观理解下来就是与大模型的答案语义上接近的更有可能是所需的答案,而且大模型是通过大量原始文档学习出来,因此生成的假设文档与原始文档上更接近,因此更易于检索。
实现方案
HyDE 的实现在 langchain 已经支持了,可以通过 from langchain.chains import hyde 进行使用,提供的是一个向量化查询的转换支持,可以看到其中最核心的方法如下所示:
def embed_query(self, text: str) -> List[float 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











