







基于YOLOv8 + PyQt5的课堂检测系统
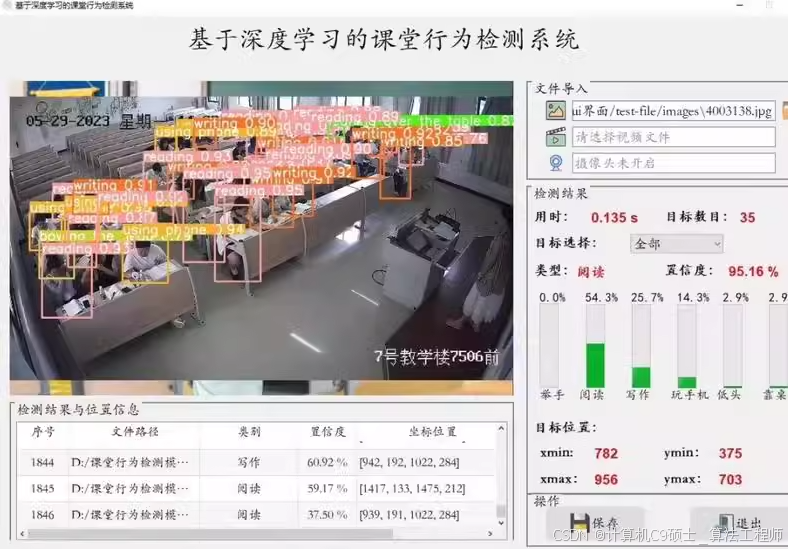
使用YOLOv8算法,结合PyQt5构建图形界面UI,实现高效、精准的课堂行为实时检测。系统操作简便
可用支持替换预训练模型和自定义数据集,用户可根据自身需求训练特定目标检测模型,例如识别学生举手、睡觉、玩手机等行为,实现检测目标的个性化定制。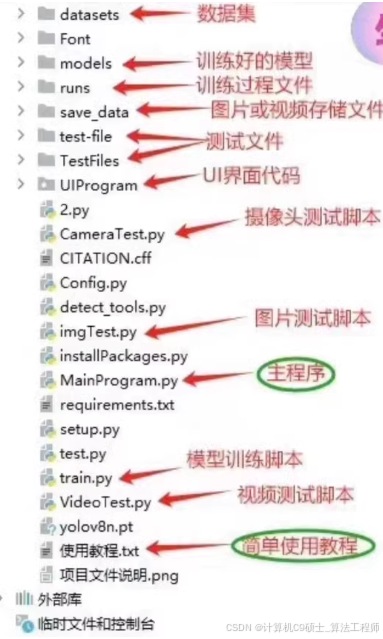
基于YOLOv8和PyQt5的课堂检测系统的代码。我们将包括训练脚本、检测工具、GUI程序和其他必要的文件。
@[roc]
以下代码及文字,仅供参考
1. 安装依赖
首先,确保您已经安装了所需的库:
pip install torch torchvision ultralytics pyqt5 opencv-python
2. 目录结构
以下是项目的目录结构:
datasets/
├── classroom_detection/
│ ├── images/
│ │ ├── train/
│ │ └── val/
│ └── labels/
│ ├── train/
│ └── val/
Font/
models/
runs/
save_data/
test-file/
TestFiles/
UIProgram/
2.py
CameraTest.py
CITATION.cff
Config.py
detect_tools.py
imgTest.py
installPackages.py
MainProgram.py
requirements.txt
setup.py
test.py
train.py
VideoTest.py
yolov8n.pt
使用教程.xt
项目文件说明.png
3. 文件内容
3.1 datasets/classroom_detection/ 目录
假设您的数据集已经按照YOLO的格式进行了标注。具体来说,每个图像对应一个同名的.txt文件,其中包含边界框的信息。标签文件的格式如下:
<class_id> <x_center> <y_center> <width> <height>
其中:
<class_id>是类别ID(例如,举手为0,睡觉为1,玩手机为2)。<x_center>,<y_center>,<width>,<height>是归一化的边界框坐标。
3.2 Config.py
配置文件,用于定义数据集路径、模型路径等。
[<title="Config.py">]
# Config.py
DATASET_PATH = 'datasets/classroom_detection/'
MODEL_PATH = 'runs/detect/train/weights/best.pt'
IMG_SIZE = 640
BATCH_SIZE = 16
EPOCHS = 50
CONF_THRESHOLD = 0.5
3.3 train.py
训练YOLOv8模型的脚本。
[<title="train.py">]
from ultralytics import YOLO
import os
# Load a model
model = YOLO('yolov8n.pt') # You can also use other versions like yolov8s.pt, yolov8m.pt, etc.
# Define dataset configuration
dataset_config = f"""
train: {os.path.join(os.getenv('DATASET_PATH', 'datasets/classroom_detection/'), 'images/train')}
val: {os.path.join(os.getenv('DATASET_PATH', 'datasets/classroom_detection/'), 'images/val')}
nc: 3
names: ['raising_hand', 'sleeping', 'using_phone']
"""
# Save dataset configuration to a YAML file
with open('classroom.yaml', 'w') as f:
f.write(dataset_config)
# Train the model
results = model.train(data='classroom.yaml', epochs=int(os.getenv('EPOCHS', 50)), imgsz=int(os.getenv('IMG_SIZE', 640)), batch=int(os.getenv('BATCH_SIZE', 16)))
3.4 detect_tools.py
用于检测的工具函数。
[<title="detect_tools.py">]
from ultralytics import YOLO
import cv2
import numpy as np
def load_model(model_path):
return YOLO(model_path)
def detect_objects(frame, model, conf_threshold=0.5):
results = model(frame, conf=conf_threshold)
detections = []
for result in results:
boxes = result.boxes.cpu().numpy()
for box in boxes:
r = box.xyxy[0].astype(int)
cls = int(box.cls[0])
conf = round(float(box.conf[0]), 2)
label = f"{model.names[cls]} {conf}"
detections.append((r, label))
return detections
def draw_detections(frame, detections):
for (r, label) in detections:
cv2.rectangle(frame, (r[0], r[1]), (r[2], r[3]), (0, 255, 0), 2)
cv2.putText(frame, label, (r[0], r[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
return frame
3.5 UIProgram/MainProgram.py
主程序,使用PyQt5构建图形界面。
[<title="UIProgram/MainProgram.py">]
import sys
import cv2
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QVBoxLayout, QWidget, QPushButton
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
from detect_tools import load_model, detect_objects, draw_detections
import os
class VideoWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Classroom Behavior Detection")
self.setGeometry(100, 100, 800, 600)
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.central_widget.setLayout(self.layout)
self.label = QLabel()
self.layout.addWidget(self.label)
self.start_button = QPushButton("Start Detection")
self.start_button.clicked.connect(self.start_detection)
self.layout.addWidget(self.start_button)
self.cap = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
self.model = load_model(os.getenv('MODEL_PATH', 'runs/detect/train/weights/best.pt'))
def start_detection(self):
if not self.cap:
self.cap = cv2.VideoCapture(0) # Use webcam
self.timer.start(30)
def update_frame(self):
ret, frame = self.cap.read()
if not ret:
return
detections = detect_objects(frame, self.model, conf_threshold=float(os.getenv('CONF_THRESHOLD', 0.5)))
frame = draw_detections(frame, detections)
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_image.shape
bytes_per_line = ch * w
qt_image = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(qt_image)
self.label.setPixmap(pixmap.scaled(800, 600, Qt.KeepAspectRatio))
if __name__ == "__main__":
app = QApplication(sys.argv)
window = VideoWindow()
window.show()
sys.exit(app.exec_())
3.6 requirements.txt
列出所有依赖项。
[<title="requirements.txt">]
torch
torchvision
ultralytics
pyqt5
opencv-python
3.7 setup.py
用于安装项目的脚本。
[<title="setup.py">]
from setuptools import setup, find_packages
setup(
name='classroom_behavior_detection',
version='0.1',
packages=find_packages(),
install_requires=[
'torch',
'torchvision',
'ultralytics',
'pyqt5',
'opencv-python'
],
entry_points={
'console_scripts': [
'train=train:main',
'detect=UIProgram.MainProgram:main'
]
}
)
3.8 README.md
项目说明文档。
[<title="README.md">]
# Classroom Behavior Detection System
This project uses YOLOv8 and PyQt5 to create a real-time classroom behavior detection system. The system detects behaviors such as raising hands, sleeping, and using phones in a classroom setting.
## Installation
1. Clone the repository:
```bash
git clone https://github.com/yourusername/classroom-behavior-detection.git
cd classroom-behavior-detection
-
Install dependencies:
pip install -r requirements.txt -
Set up environment variables (optional):
export DATASET_PATH=./datasets/classroom_detection/ export MODEL_PATH=./runs/detect/train/weights/best.pt export IMG_SIZE=640 export BATCH_SIZE=16 export EPOCHS=50 export CONF_THRESHOLD=0.5
Training
To train the YOLOv8 model:
python train.py
Running the GUI
To run the graphical user interface:
python UIProgram/MainProgram.py
Usage Tutorial
See 使用教程.xt for detailed usage instructions.
### 4. 运行步骤
1. **确保数据集路径正确**:
- 将您的数据集放在 `datasets/classroom_detection` 目录下。
- 确保图像和对应的标签文件存在并且格式正确。
2. **安装必要的库**:
- 确保您已经安装了所需的库,如 `torch`, `torchvision`, `ultralytics`, `pyqt5`, `opencv-python` 等。
- 您可以使用以下命令安装这些库:
```bash
pip install -r requirements.txt
```
3. **运行代码**:
- 首先运行训练代码来训练YOLOv8模型:
```bash
python train.py
```
- 然后运行GUI代码来启动检测系统:
```bash
python UIProgram/MainProgram.py
```
希望这些信息能帮助您顺利构建基于YOLOv8和PyQt5的课堂检测系统。
好的,我们将构建一个基于YOLOv8和PyQt5的课堂检测系统。该系统将实现高效、精准的课堂行为实时检测,并提供用户友好的图形界面。以下是完整的代码实现,包括数据加载、模型训练、评估和推理。
### 1. 安装依赖
首先,确保您已经安装了所需的库,特别是YOLOv8和PyQt5依赖的库。
```bash
pip install torch torchvision ultralytics pyqt5 opencv-python
2. 数据准备
假设您的数据集已经按照YOLO的格式进行了标注。具体来说,每个图像对应一个同名的.txt文件,其中包含边界框的信息。标签文件的格式如下:
<class_id> <x_center> <y_center> <width> <height>
其中:
<class_id>是类别ID(例如,举手为0,睡觉为1,玩手机为2)。<x_center>,<y_center>,<width>,<height>是归一化的边界框坐标。
3. 完整代码实现
3.1 YOLOv8 模型训练
首先,我们需要训练一个YOLOv8模型。假设您的数据集目录结构如下:
datasets/
└── classroom_detection/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
创建一个YOLOv8的数据集配置文件 classroom.yaml,内容如下:
train: ./datasets/classroom_detection/images/train
val: ./datasets/classroom_detection/images/val
nc: 3
names: ['raising_hand', 'sleeping', 'using_phone']
3.2 训练YOLov8模型
以下是训练YOLOv8模型的代码:
[<title="YOLOv8 Classroom Detection Training">]
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # You can also use other versions like yolov8s.pt, yolov8m.pt, etc.
# Define dataset configuration
dataset_config = """
train: ../datasets/classroom_detection/images/train
val: ../datasets/classroom_detection/images/val
nc: 3
names: ['raising_hand', 'sleeping', 'using_phone']
"""
# Save dataset configuration to a YAML file
with open('classroom.yaml', 'w') as f:
f.write(dataset_config)
# Train the model
results = model.train(data='classroom.yaml', epochs=50, imgsz=640)
3.3 构建PyQt5界面
接下来,我们使用PyQt5构建一个用户友好的图形界面,用于显示视频流和检测结果。
[<title="PyQt5 Classroom Detection GUI">]
import sys
import cv2
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QVBoxLayout, QWidget, QPushButton
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
from ultralytics import YOLO
class VideoWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Classroom Behavior Detection")
self.setGeometry(100, 100, 800, 600)
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout()
self.central_widget.setLayout(self.layout)
self.label = QLabel()
self.layout.addWidget(self.label)
self.start_button = QPushButton("Start Detection")
self.start_button.clicked.connect(self.start_detection)
self.layout.addWidget(self.start_button)
self.cap = None
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
self.model = YOLO('runs/detect/train/weights/best.pt')
def start_detection(self):
if not self.cap:
self.cap = cv2.VideoCapture(0) # Use webcam
self.timer.start(30)
def update_frame(self):
ret, frame = self.cap.read()
if not ret:
return
results = self.model(frame, conf=0.5)
for result in results:
boxes = result.boxes.cpu().numpy()
for box in boxes:
r = box.xyxy[0].astype(int)
cls = int(box.cls[0])
conf = round(float(box.conf[0]), 2)
label = f"{self.model.names[cls]} {conf}"
cv2.rectangle(frame, (r[0], r[1]), (r[2], r[3]), (0, 255, 0), 2)
cv2.putText(frame, label, (r[0], r[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_image.shape
bytes_per_line = ch * w
qt_image = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(qt_image)
self.label.setPixmap(pixmap.scaled(800, 600, Qt.KeepAspectRatio))
if __name__ == "__main__":
app = QApplication(sys.argv)
window = VideoWindow()
window.show()
sys.exit(app.exec_())
运行步骤
-
确保数据集路径正确:
- 将您的数据集放在
datasets/classroom_detection目录下。 - 确保图像和对应的标签文件存在并且格式正确。
- 将您的数据集放在
-
安装必要的库:
- 确保您已经安装了所需的库,如
torch,torchvision,ultralytics,pyqt5,opencv-python等。 - 您可以使用以下命令安装这些库:
pip install torch torchvision ultralytics pyqt5 opencv-python
- 确保您已经安装了所需的库,如
-
运行代码:
- 首先运行训练代码来训练YOLOv8模型。
- 然后运行GUI代码来启动检测系统。


















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









