







使用YOLOv8训练一个排水管道缺陷检测系统 从完成数据集准备、模型训练、优化评估以及最终部署到安卓端的过程
、排水管道缺陷检测数据集、

对管道的检测类别:共16种类别包括支管暗接、变形、沉积、错口、残墙坝根、异物插入、腐蚀、浮渣、结垢、破裂、起伏、树根、渗漏、脱节、材料脱落、障碍物。
检测等级:根据CJJ181技术规程定义,不同类别对应不同等级,见标注文件,最小为1级,最大为4级。
数据集12013张图片 均由labelme进行标注且have缺陷的类别和等级标签,
数据集训练过程
为了使用YOLOv8训练一个排水管道缺陷检测系统,以下是详细的步骤和代码示例,包括数据集准备、模型训练、优化评估等环节。
1. 数据集准备
首先确保你的LabelMe标注数据已经转换为YOLO格式。假设你已经有了这样的数据集结构:
dataset/train/images/: 训练图像dataset/train/labels/: 对应的YOLO格式标签文件dataset/val/images/: 验证图像dataset/val/labels/: 对应的YOLO格式标签文件
每个YOLO格式的标签文件中的每一行代表一个对象,格式如下:<class_index> <x_center> <y_center> <width> <height>,其中坐标和尺寸已经归一化到[0, 1]之间。
创建一个data.yaml文件来描述数据集路径和类别信息:
train: ./dataset/train/images/
val: ./dataset/val/images/
nc: 16 # 类别数量
names: ['支管暗接', '变形', '沉积', '错口', '残墙坝根', '异物插入', '腐蚀', '浮渣', '结垢', '破裂', '起伏', '树根', '渗漏', '脱节', '材料脱落', '障碍物'] # 类别名称
如果你的数据集是LabelMe格式,需要先将其转换为YOLO格式。以下是一个Python脚本用于转换:
import json
import os
from PIL import Image
def convert_labelme_to_yolo(labelme_dir, yolo_dir):
if not os.path.exists(yolo_dir):
os.makedirs(yolo_dir)
for json_file in os.listdir(labelme_dir):
if not json_file.endswith('.json'):
continue
with open(os.path.join(labelme_dir, json_file), 'r') as f:
data = json.load(f)
img_width = data['imageWidth']
img_height = data['imageHeight']
txt_filename = os.path.splitext(json_file)[0] + '.txt'
with open(os.path.join(yolo_dir, txt_filename), 'w') as f:
for shape in data['shapes']:
label = shape['label'].split('_')[0] # 假设标签格式为 "category_grade"
category_id = categories.index(label) # 使用categories列表来映射类别名称到ID
points = shape['points']
x_min, y_min = min(p[0] for p in points), min(p[1] for p in points)
x_max, y_max = max(p[0] for p in points), max(p[1] for p in points)
x_center = (x_min + x_max) / 2 / img_width
y_center = (y_min + y_max) / 2 / img_height
width = (x_max - x_min) / img_width
height = (y_max - y_min) / img_height
f.write(f"{category_id} {x_center} {y_center} {width} {height}\n")
# 类别列表
categories = ['支管暗接', '变形', '沉积', '错口', '残墙坝根', '异物插入', '腐蚀', '浮渣', '结垢', '破裂', '起伏', '树根', '渗漏', '脱节', '材料脱落', '障碍物']
# 使用方法
convert_labelme_to_yolo('path/to/labelme_annotations/', 'path/to/yolo_labels/')
2. 模型训练
安装必要的库:
pip install ultralytics opencv-python
使用YOLOv8进行模型训练:
from ultralytics import YOLO
import os
def train_yolov8_model():
# 加载预训练的YOLOv8模型
model = YOLO('yolov8n.pt') # 或者选择其他变体如'yolov8s.pt', 'yolov8m.pt'等
# 开始训练
results = model.train(
data='path/to/data.yaml', # 数据集配置文件路径
epochs=100, # 根据需要调整epoch数
imgsz=640, # 输入图像尺寸
batch=16, # 批次大小
name='drainage_defect_detection', # 实验名称
save=True, # 自动保存最佳模型
exist_ok=True, # 如果目录存在则不报错
patience=50, # 当验证损失不再改善时提前停止训练的轮数
lr0=0.01, # 初始学习率
lrf=0.1, # 最终学习率(lr0 * lrf)
optimizer='SGD', # 优化器类型
augment=True, # 启用数据增强
flipud=0.0, # 上下翻转概率
fliplr=0.5, # 左右翻转概率
mosaic=1.0, # Mosaic数据增强的概率
mixup=0.0, # MixUp数据增强的概率
degrees=0.0, # 旋转角度范围
translate=0.1, # 平移比例范围
scale=0.5, # 缩放比例范围
shear=0.0, # 剪切变换角度范围
perspective=0.0, # 透视变换比例
dropout=0.0, # Dropout比例
hsv_h=0.015, # HSV色调变化比例
hsv_s=0.7, # HSV饱和度变化比例
hsv_v=0.4, # HSV亮度变化比例
copy_paste=0.0, # Copy-Paste数据增强的概率
cache=True, # 使用缓存加速训练
device='', # 使用GPU或CPU ('cuda' or 'cpu')
workers=8, # 数据加载的工作线程数
project='runs/detect', # 保存结果的项目目录
entity=None, # WandB实体名
upload_dataset=False, # 是否上传数据集到WandB
bbox_interval=-1, # Bbox日志间隔
artifact_alias="latest", # 版本控制别名
multi_scale=False, # 多尺度训练
sync_bn=False, # 同步BN
cos_lr=False, # 使用余弦退火学习率调度
single_cls=False, # 单类模式
rect=False, # 矩形训练
resume=False, # 恢复训练
freeze=[0], # 冻结层的数量
verbose=True, # 显示详细输出
seed=0, # 随机种子
linear_lr=False, # 线性学习率
overlap_mask=True, # 掩码重叠
mask_ratio=4, # 掩码比例
v5_metric=False # 使用YOLOv5的评估指标
)
if __name__ == "__main__":
train_yolov8_model()
3. 优化与评估
训练完成后,可以使用验证集评估模型性能:
from ultralytics import YOLO
def validate_model():
model = YOLO('runs/detect/drainage_defect_detection/weights/best.pt') # 加载最佳模型
metrics = model.val() # 进行验证
print(metrics.box.map) # 输出mAP值作为性能指标之一
if __name__ == "__main__":
validate_model()
4. 导出模型以便在安卓端使用
导出模型为ONNX格式以适应移动端部署:
from ultralytics import YOLO
model = YOLO('runs/detect/drainage_defect_detection/weights/best.pt')
model.export(format='onnx') # 导出为ONNX格式
以下文字及代码仅供参考,
@
为了使用YOLOv8训练一个排水管道缺陷检测系统,并根据给定的数据集(12013张图片,每张图片有16种可能的缺陷类别和对应的等级),我们需要完成数据集准备、模型训练、优化评估以及最终部署到安卓端的过程。以下是详细的步骤和代码示例。
1. 数据集准备
数据集结构
假设你的数据集由LabelMe标注,首先需要将这些标注转换为YOLO格式。LabelMe生成的是JSON文件,每个文件包含图像中对象的详细信息。以下是一个Python脚本用于将LabelMe JSON格式转换为YOLO格式:
import json
import os
from PIL import Image
def convert_labelme_to_yolo(labelme_dir, yolo_dir):
if not os.path.exists(yolo_dir):
os.makedirs(yolo_dir)
for json_file in os.listdir(labelme_dir):
if not json_file.endswith('.json'):
continue
with open(os.path.join(labelme_dir, json_file), 'r') as f:
data = json.load(f)
img_width = data['imageWidth']
img_height = data['imageHeight']
txt_filename = os.path.splitext(json_file)[0] + '.txt'
with open(os.path.join(yolo_dir, txt_filename), 'w') as f:
for shape in data['shapes']:
label = shape['label'].split('_')[0] # 假设标签格式为 "category_grade"
category_id = categories.index(label) # 使用categories列表来映射类别名称到ID
points = shape['points']
x_center = (points[0][0] + points[1][0]) / 2 / img_width
y_center = (points[0][1] + points[1][1]) / 2 / img_height
width = abs(points[1][0] - points[0][0]) / img_width
height = abs(points[1][1] - points[0][1]) / img_height
f.write(f"{category_id} {x_center} {y_center} {width} {height}\n")
# 类别列表
categories = ['支管暗接', '变形', '沉积', '错口', '残墙坝根', '异物插入', '腐蚀', '浮渣', '结垢', '破裂', '起伏', '树根', '渗漏', '脱节', '材料脱落', '障碍物']
# 使用方法
convert_labelme_to_yolo('path/to/labelme_annotations/', 'path/to/yolo_labels/')
创建一个data.yaml文件来描述数据集路径和类别信息:
train: ./dataset/train/images/
val: ./dataset/val/images/
nc: 16 # 类别数量
names: ['支管暗接', '变形', '沉积', '错口', '残墙坝根', '异物插入', '腐蚀', '浮渣', '结垢', '破裂', '起伏', '树根', '渗漏', '脱节', '材料脱落', '障碍物'] # 类别名称
2. 模型训练
安装必要的库:
pip install ultralytics opencv-python
使用YOLOv8进行模型训练:
from ultralytics import YOLO
def train_yolov8_model():
# 加载预训练的YOLOv8模型
model = YOLO('yolov8n.pt') # 或者选择其他变体如'yolov8s.pt', 'yolov8m.pt'等
# 开始训练
results = model.train(
data='path/to/data.yaml', # 数据集配置文件路径
epochs=100, # 根据需要调整epoch数
imgsz=640, # 输入图像尺寸
batch=16, # 批次大小
name='drainage_defect_detection', # 实验名称
save=True, # 自动保存最佳模型
exist_ok=True, # 如果目录存在则不报错
patience=50, # 当验证损失不再改善时提前停止训练的轮数
lr0=0.01, # 初始学习率
lrf=0.1, # 最终学习率(lr0 * lrf)
optimizer='SGD', # 优化器类型
augment=True, # 启用数据增强
flipud=0.0, # 上下翻转概率
fliplr=0.5, # 左右翻转概率
mosaic=1.0, # Mosaic数据增强的概率
mixup=0.0, # MixUp数据增强的概率
degrees=0.0, # 旋转角度范围
translate=0.1, # 平移比例范围
scale=0.5, # 缩放比例范围
shear=0.0, # 剪切变换角度范围
perspective=0.0, # 透视变换比例
dropout=0.0, # Dropout比例
hsv_h=0.015, # HSV色调变化比例
hsv_s=0.7, # HSV饱和度变化比例
hsv_v=0.4, # HSV亮度变化比例
copy_paste=0.0, # Copy-Paste数据增强的概率
cache=True, # 使用缓存加速训练
device='', # 使用GPU或CPU ('cuda' or 'cpu')
workers=8, # 数据加载的工作线程数
project='runs/detect', # 保存结果的项目目录
entity=None, # WandB实体名
upload_dataset=False, # 是否上传数据集到WandB
bbox_interval=-1, # Bbox日志间隔
artifact_alias="latest", # 版本控制别名
multi_scale=False, # 多尺度训练
sync_bn=False, # 同步BN
cos_lr=False, # 使用余弦退火学习率调度
single_cls=False, # 单类模式
rect=False, # 矩形训练
resume=False, # 恢复训练
freeze=[0], # 冻结层的数量
verbose=True, # 显示详细输出
seed=0, # 随机种子
linear_lr=False, # 线性学习率
overlap_mask=True, # 掩码重叠
mask_ratio=4, # 掩码比例
v5_metric=False # 使用YOLOv5的评估指标
)
if __name__ == "__main__":
train_yolov8_model()
3. 优化与评估
训练完成后,可以使用验证集评估模型性能:
from ultralytics import YOLO
def validate_model():
model = YOLO('runs/detect/drainage_defect_detection/weights/best.pt') # 加载最佳模型
metrics = model.val() # 进行验证
print(metrics.box.map) # 输出mAP值作为性能指标之一
if __name__ == "__main__":
validate_model()
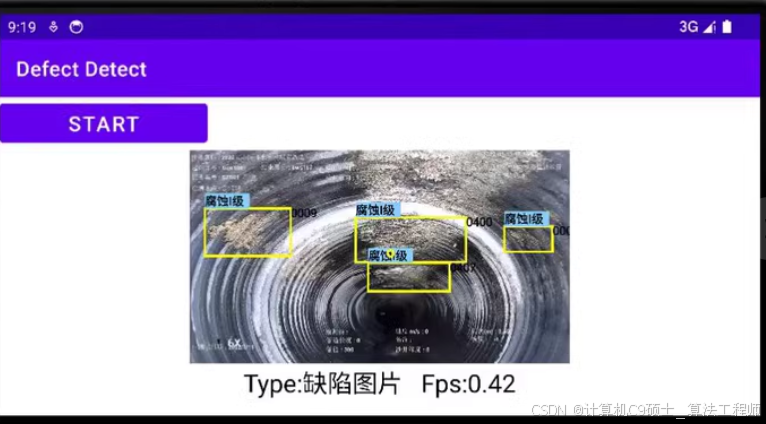
4. 安卓端部署
对于安卓端部署,可以使用PyTorch Mobile或ONNX Runtime来导出和运行模型。以下是简单的步骤指南:
导出模型
from ultralytics import YOLO
model = YOLO('runs/detect/drainage_defect_detection/weights/best.pt')
model.export(format='onnx') # 导出为ONNX格式
安卓端集成
在安卓端,你可以使用ONNX Runtime Android来进行推理。你需要在安卓项目中添加ONNX Runtime依赖,并编写相应的代码来加载和运行模型。
build.gradle
dependencies {
implementation 'com.microsoft.onnxruntime:onnxruntime-mobile:1.11.0'
}
Java代码示例
import com.microsoft.onnxruntime.OnnxTensor;
import com.microsoft.onnxruntime.OrtEnvironment;
import com.microsoft.onnxruntime.OrtSession;
// 加载模型并进行推理
try (OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession session = env.createSession("path/to/model.onnx")) {
// 准备输入数据
float[] inputData = ...; // 准备输入数据
long[] inputShape = ...; // 设置输入形状
OnnxTensor tensor = OnnxTensor.createTensor(env, inputData, inputShape);
// 运行模型
Map<String, OnnxTensor> inputs = new HashMap<>();
inputs.put(session.getInputNames().iterator().next(), tensor);
try (OrtSession.Result output = session.run(inputs)) {
// 获取输出
float[] outputData = ((float[][]) output.get(0).getValue())[0];
System.out.println(Arrays.toString(outputData));
}
}


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









