







任何一次引人注目的技术变革,其背后都有众多科学研究工作的历史积淀。产业视野中的需求与挑战,能帮助研究者们更准确地识别问题,并加速技术的创新与应用落地。无问芯穹生逢这一技术变革与应用创新的节点,致力于让以大模型为代表的人工智能技术在更多软硬件上以更快速度、更佳表现、更低成本完成落地。
2024年1-3月,我们的多项科研成果获顶级学术会议接收,现将有关内容整理成文,并为感兴趣的读者们提供论文获取渠道。
论文主题一览
Skeleton-of-Thoughts:通过提示词技术让语言模型规划输出内容,从而引入数据维度的可并行性。利用此可并行性进行批次推理,我们的方法在12个主流LLM中的10个模型上取得了1.9x以上整体延时降低,且能够在部分问题类别上提升答案的全面性和相关性。
Qllm-Eval:对量化后的大语言模型进行了全面评估,分析不同量化方案对模型性能的影响,可以帮助快速确定量化方案。
A Unified Sampling Framework for Solver Searching of Diffusion Probabilistic Models:建立了一个寻找最优采样策略的求解框架,在7个数据集上实现整体1.5-2倍加速,并将极低步数下的采样性能提升70%-500%。
FlashEval:提出了一种搜索算法找到数据集的“代表性子集”,从而在保持评估质量的前提下,显著减少评估数据量约10倍。
1
引入数据维度并行 加速推理
SKELETON-OF-THOUGHT: PROMPTING LLMs FOR EFFICIENT PARALLEL GENERATION

本文的研究动机与思路是,针对LLM解码过程计算利用率低和延时大的问题,在数据层面,通过提示词引导LLM自主规划出答案提纲,并利用提纲中不同部分的可并行性,解决LLM解码过程计算单元利用率低和延时大的问题。
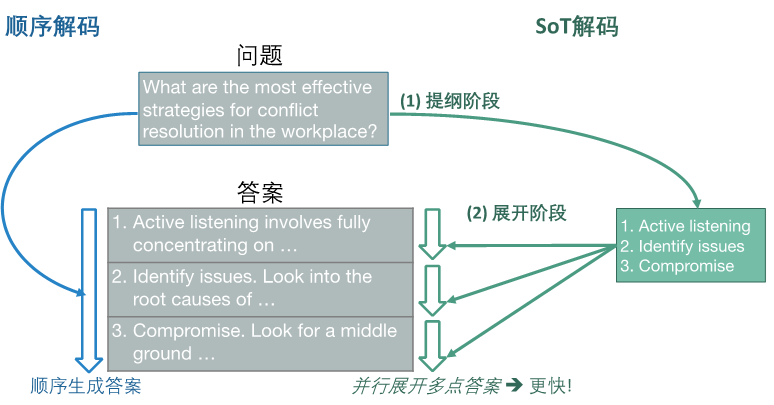
主要工作内容
SoT引入了数据维度的并行,可以和目前已有的面向吞吐的优化技术、高效推理引擎和高效服务系统相结合,进一步提升大模型推理系统的性能。最终在12个主流LLM中的10个模型上取得了1.9x以上整体延时降低,且能够在部分问题类别上提升答案的全面性和相关性。本工作已被ICLR 2024接收。随着LLM输出长度和能力的不断提升,利用其输出中的结构和可并行性来提高硬件利用率和生成速度是一个值得探索的方向。
· Arxiv地址:https://arxiv.org/abs/2307.15337
· Github地址:https://github.com/imagination-research/sot
· Website:https://sites.google.com/view/sot-llm
2
哪种量化方案能让损失更少?
Evaluating Quantized Large Language Models(Qllm-Eval)

本文的研究动机与思路是,对量化后的大语言模型进行全面评估。量化是提升LLMs推理效率的有效手段之一,但它是一种有损压缩技术,不同的量化方案对任务性能会产生不同的影响。本工作旨在总结量化在不同任务、不同模型上的任务性能经验。
主要工作内容
量化对不同张量类型的影响:模型参数量越大对Weight和KV Cache量化的容忍度越高。相反,模型参数量越大对Activation量化的容忍度越低。因为越大的模型Weight中的Outlier越少,Activation中的Outlier越多。
量化对不同层的影响:Attention里Output投影层的Weight Outlier略多,FFN里的下采样MLP的Activation中Outlier显著更多。
量化对MoE模型的影响:使用MoE提升参数量可以显著提升模型性能,但是无法提升对Weight和KV Cache量化的容忍度。
量化对不同任务的影响:对于大多数任务,推荐将模型量化至W4,W4A8,KV4,以保证精度几乎无损(损失2%以内)。在给定存储预算的条件下,推荐使用更大参数量模型的W3量化版本以获得更优的性能。
考虑到当前的LLM是一类能够解决多种不同任务的通用模型,了解不同量化方案对任务性能的影响是将量化应用于实际场景中的重要问题。本文给出了许多的量化参数推荐,在面向某些实际任务时,能够帮助用户快速确定量化方案。
· Arxiv地址:https://arxiv.org/abs/2402.18158
· Github地址:https://github.com/thu-nics/qllm-eval
3
无训练的极低步数Diffusion采样
A Unified Sampling Framework for Solver Searching of Diffusion Probabilistic Models

现有diffusion sampler在极低采样步数下表现较差,制约了diffusion model的生成速度,其原因在于对求解策略的不合理选择。为解决这一问题,本工作建立了一个求解框架,统一了所有可选的采样策略,并通过搜索的方式寻找最优策略,使得无需训练UNet便能加速diffusion采样。
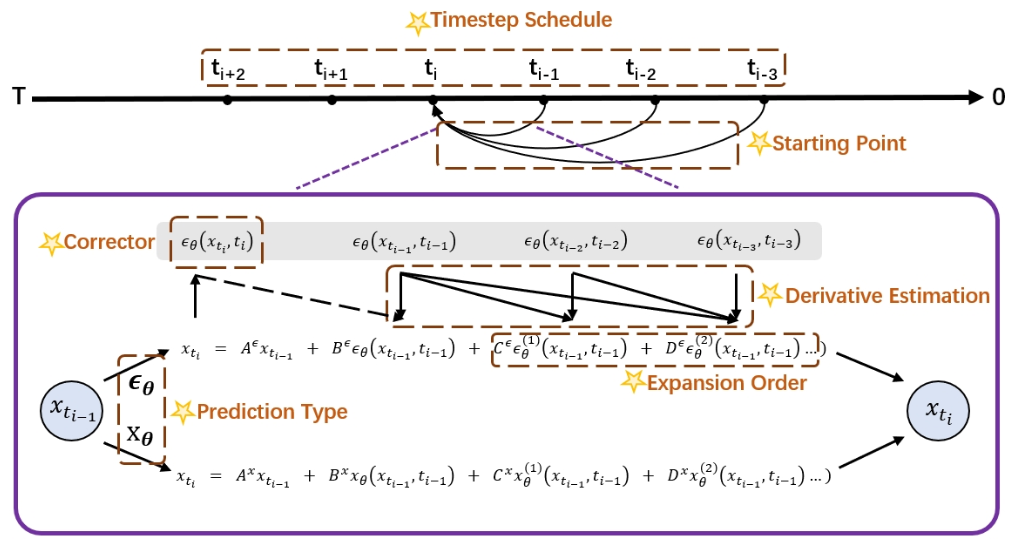
核心思路
该技术能够在不训练UNet的情况下用少量搜索开销实现极低步数采样,极大提升现有diffusion model的生成速度。最终我们的求解框架在7个数据集(CIFAR10、CelebA、ImageNet-64(uncond)、LSUN-Bedroom、ImageNet-128(cond)、ImageNet-256(cond)、MS-COCO文生图)上实现整体1.5-2倍加速,并将极低步数下的采样性能提升70%-500%,本工作已被ICLR 2024接收。
· Arxiv地址:https://arxiv.org/abs/2312.07243
4
选型、微调…
模型评估更高效
FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models

本文的研究动机与思路是,目前Diffusion模型文生图任务的评估速度慢,FlashEval提出了一种搜索算法,解决目前Diffusion模型文生图任务评估速度慢的问题。通过搜索文生图评估数据集中“代表性子集合”,减少待评估的数据量,以加速模型的评估。最终能够在保持评估质量的前提下,显著减少评估数据量约10倍。

主要工作内容
许多实际的应用场景需要涉及多次的Diffusion模型的评估,如选择合适的模型、微调模型权重、算法方案的设计等。FlashEval基于数据出现频次进行迭代式搜索的核心思路,能够逐步减小数据量。
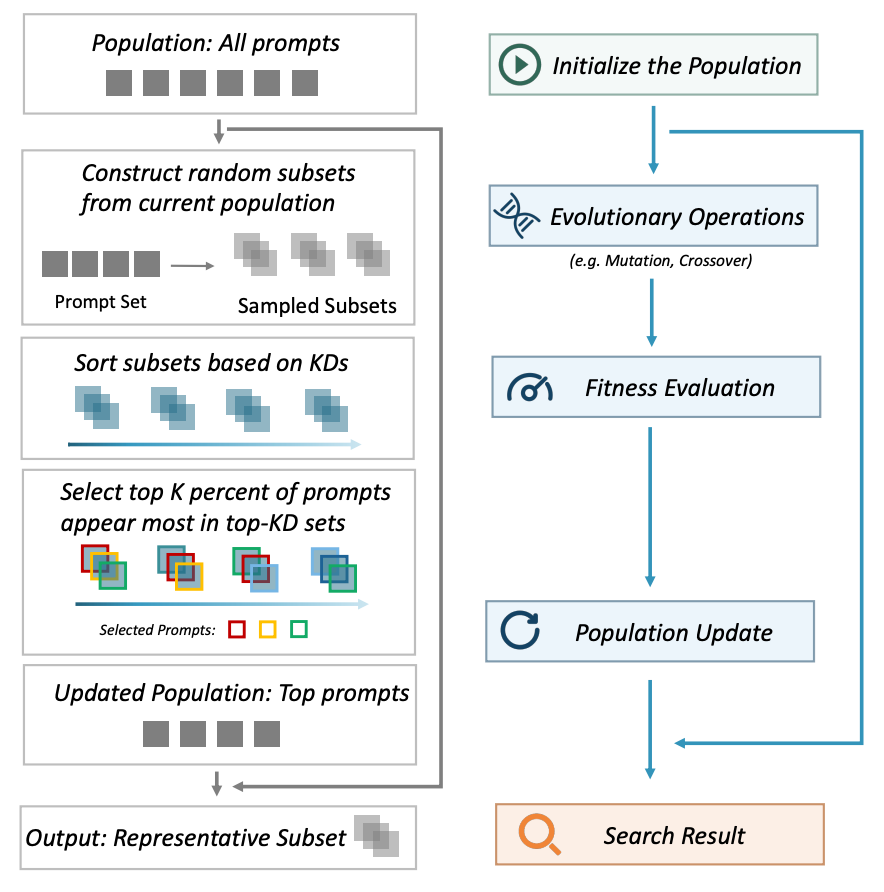
迭代式搜索核心思路
FlashEval能够通过显著减少评估代价,缩短算法方案设计迭代优化周期,以加速模型的设计、开发与改进。本工作已被CVPR 2024接收。
· Github地址:https://github.com/thu-nics/flasheval *代码上传中
后续我们还将对其中部分工作展开进一步解读并持续建设相关代码仓库,欢迎您关注。















 2718
2718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









