







智东西2月3日报道,2月2日晚间,来自清华、交大、复旦等高校的五位高校教授夜话DeepSeek,从模型方法、框架、系统、基础设施等角度,阐述DeepSeek的技术原理与未来方向,揭秘其优化方法如何提升算力能效。
如何复现o1大推理模型?DeepSeek R1技术路线和训练流程有哪些亮点?为什么DeepSeek能做到轰动全球?DeepSeek通过哪些优化策略有效降低成本?DeepSeek的写作能力为何飞跃?MoE架构会是最优解吗?PTX是否真正做到了绕开CUDA的垄断?这些业界关注焦点话题被一一解答。
北京交通大学教授、CCF YOCSEF AC副主席金一主持了这场线上分享。复旦大学教授邱锡鹏,清华大学长聘副教授刘知远,清华大学教授翟季冬,上海交通大学副教授戴国浩,分别从不同专业角度分享了对DeepSeek的思考,并延伸到对中国大模型高质量发展路径的启发。
以下是戴国浩夜话实录整理(由智东西精编,无问芯穹精选,关注无问芯穹官方视频号可观看直播回放)
戴国浩:
PTX是否做到绕过CUDA垄断?如何极致优化大模型性能?
我关注DeepSeek团队和他们的工作有很长一段时间了。他们论文发布时,我非常喜欢这份技术报告。把它的目录做个拆解,可以看到它基本上在文章中说了四件事,分别是模型架构、系统架构、预训练方法、后训练方法。相对于模型架构、预训练和后训练,团队对于系统架构做了非常充分的介绍。

我在思考的事情是:为什么这样一个大模型的工作,大家会花更多的时间和精力去介绍系统层的架构?
DeepSeek团队有大量的工程师是聚焦在系统架构的优化上。过年期间我刷到了很多(DeepSeek绕开CUDA)的推送和新闻。我相信它最早的来源是来自于DeepSeek论文中这样一句话:
"we employ customized PTX(Parallel Thread Execution)instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs."
“我们采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存的使用和对其他SM的干扰。”
可以看到通过这样的一个定制的PTX优化,使DeepSeek的系统和模型可以更好释放底层硬件的性能。无论是在通过去做一些auto-tuning,或者说去做一些communication chunk size的调整。它对于L2 cache的使用,以及不同SM之间的streaming multiprocessor之间的干扰,都会做到最小。但是这些被媒体们解读成,国外可能叫“breakthrough by pass CUDA”,一些国内媒体会解读成是“绕开CUDA垄断”。
我们具体看一下,到底什么是CUDA,什么是PTX?为什么绕开CUDA的垄断这件事在我们看来具有很重要的价值,以及它是否真的做到了绕开CUDA的垄断?
稍微给大家介绍一下,大家平时在使用GPU或者英伟达硬件时,编程时到底是怎么一步一步来调用到底层硬件的?为了做深度学习,为了训练一个大模型,首先你需要有一张或很多GPU卡。但在上面做编程时,一般大家更多接触到的是像PyTorch或者Python这样的高层语言。一个很高层的语言最终是怎么调用到底层硬件的?它实际上经过了很多语言转换和编译的过程。
这是我上课时会用到的一页PPT。一般上层的应用会通过一些高层次的语言,或者说硬件的一些接口,从而进行编程,于是大家并不需要关注到底层硬件长得是什么样子。这些接口包括了像CUDA,也就是英伟达所提供的硬件接口,也有一些其他的,大家如果做一些图形和图像显示,会用到像DriectX或者并行计算会用到OpenCL等接口。
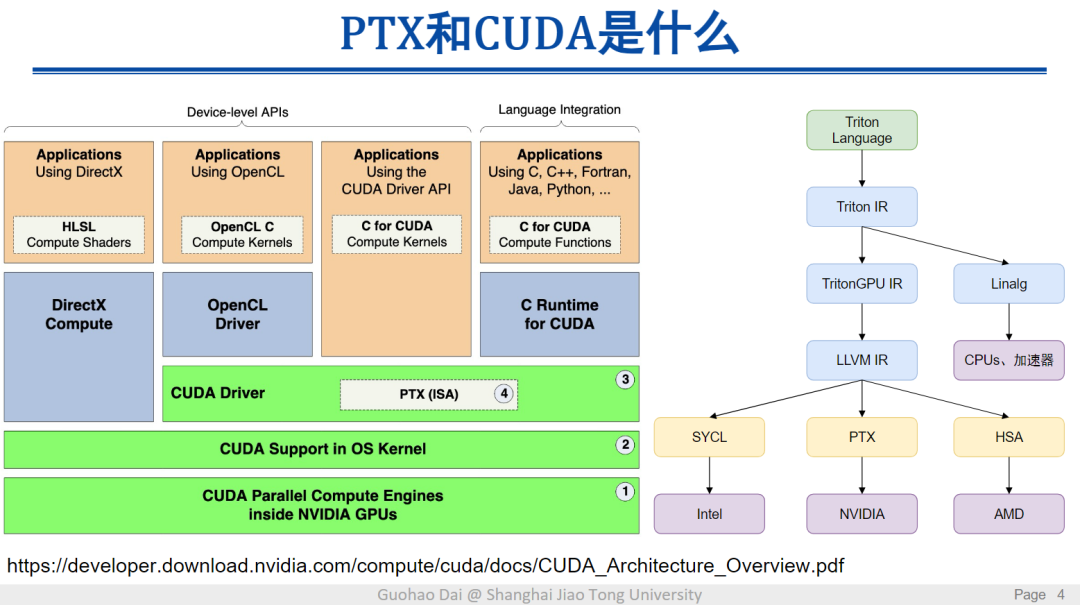
有底层CUDA的driver(驱动),通过驱动最终来调用到底层硬件。可以看到CUDA是一个相对更上层的接口,提供了面向用户的一系列编程接口。而PTX一般被隐藏在了CUDA的驱动中,所以几乎所有的深度学习或大模型算法工程师是不会接触到这一层。
那为什么这一层会很重要呢?原因是在于可以看到从这个身位上,PTX是直接和底层的硬件去发生交互的,能够实现对底层硬件更好的编程和调用。右边我们举了一个Triton的例子,也是OpenAI在主推的一个跨平台编程语言。它也是通过不断地编译和语言的转化,最终在调用底层英伟达硬件的时候,通过PTX code来调用的。所以简单来说,PTX的这一层是通过和硬件的直接交互,使得可以控制硬件更多的细节。
这件事为什么重要呢?我认为它一共有两大类优化。第一大类优化是底层优化。给定某一个确定性的算法、模型以及底层硬件,通过优化软件,比如做一些通信优化或者内存优化,这些是不改变任何程序执行的正确结果的。另一大类优化是协同优化。像混合精度的量化、MLA这些,同时优化算法、模型、软件甚至是底层硬件。这就使得整体系统的优化空间变得更大。
首先来看一下,为什么在底层做PTX优化?举一个冒泡排序算法的例子,我们分别用C代码和Python代码来做实现。一个小的彩蛋是这里的代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









