






强!Transformer再突破!MIT提出L-Mul乘法算法,通过整数加法来近似浮点数乘法,具有线性复杂度,让Transformer能耗直降95%
实际上,对Transformer的改进一直是大热门!除了前文所提,清华最新的研究Differential Transformer,也格外惹眼!作者从物理学视角革新了注意力机制,实现了精度暴涨30%的效果。主要在于Transformer可以说是AI领域最重要的模型之一,应用广泛,但是其也面临诸多局限,比如计算量大、数据要求高、长距离依赖关系处理能力差、可解释性差等,对其的改进需求迫切!
为让伙伴们能够获得更多idea启发,早点发出自己的顶会,我给大家梳理了13种最新的魔改思路,原文和源码都有!
论文原文+开源代码需要的同学看文末
论文:DIFFERENTIAL TRANSFORMER
内容
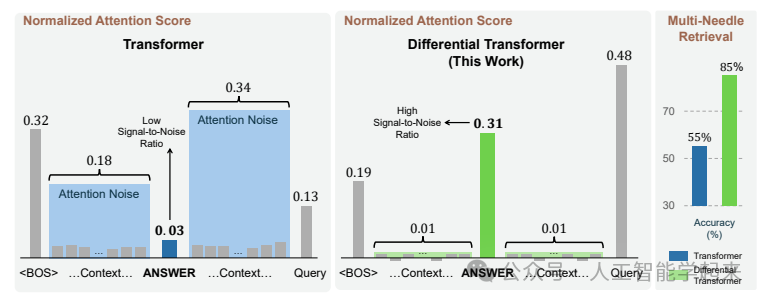
该论文介绍了一种名为DIFF Transformer的新型神经网络架构,它通过一种新颖的差分注意力机制来增强对相关上下文的关注并减少噪声。这种机制通过计算两个独立的softmax注意力图之间的差异来计算注意力分数,从而促进稀疏注意力模式的出现。
论文:ADDITION IS ALL YOU NEED FOR ENERGY-EFFICIENT LANGUAGE MODEL
内容
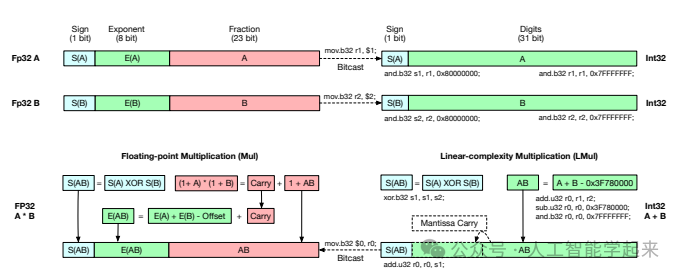
该论文介绍了一种名为L-Mul的算法,它通过整数加法来近似浮点数乘法,具有线性复杂度,能够在保持高精度的同时显著减少计算资源和能源消耗。作者提出,L-Mul算法可以用在大型语言模型中,替代传统的浮点数乘法,从而在保持模型性能的同时,大幅降低能源成本和提高计算效率。
论文:Contextual Position Encoding: Learning to Count What’s Important
内容
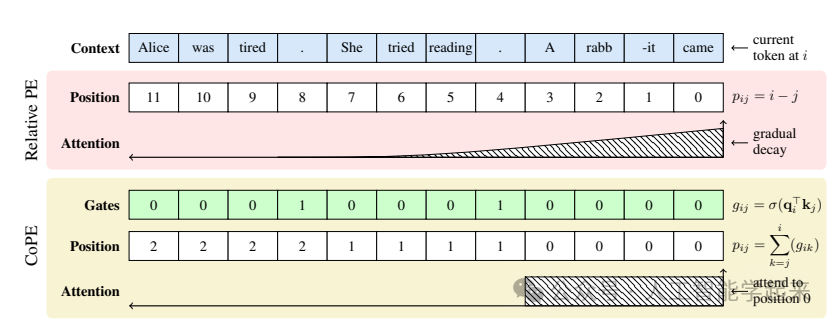
该论文介绍了一种新的位置编码方法,名为Contextual Position Encoding(CoPE),它通过考虑上下文信息来确定序列中各个标记的位置,通过计算上下文向量来确定哪些标记在确定位置时应被计数,并使用累积和来为每个标记分配相对位置。
论文:Improving Transformers with Dynamically Composable Multi-Head Attention
内容
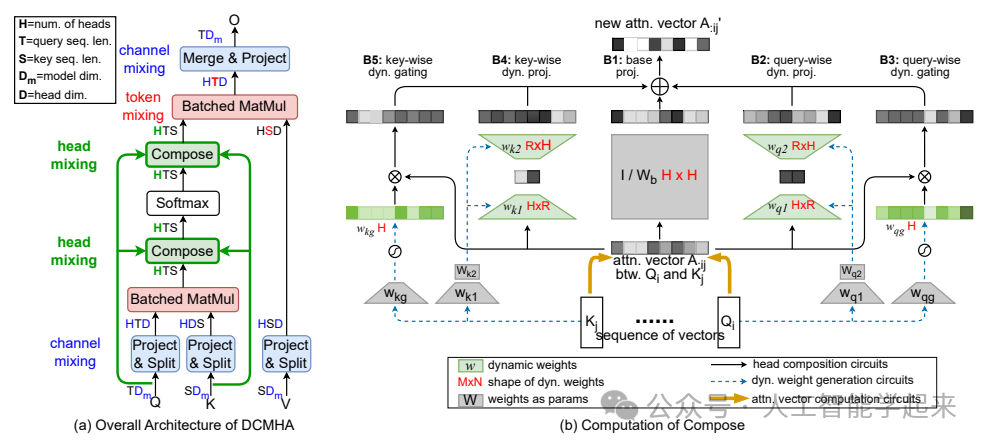
该论文提出了一种名为动态可组合多头注意力(Dynamically Composable Multi-Head Attention,简称DCMHA)的新型注意力机制,旨在解决传统多头注意力(MHA)中存在的问题,DCMHA通过一个可学习的“Compose”函数动态地组合注意力头,从而提高了模型的表达能力。
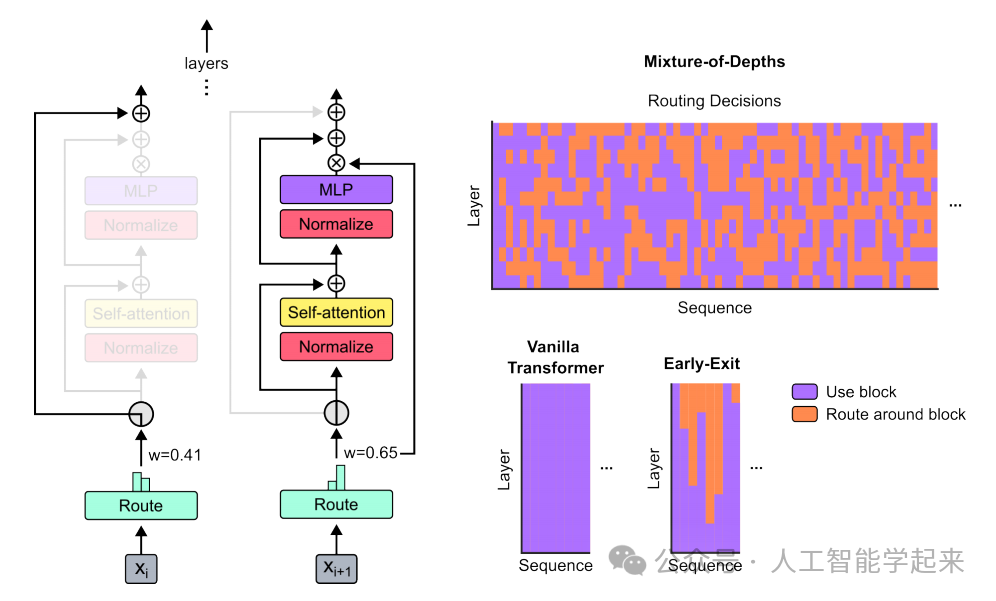
论文:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
内容
该论文介绍了一种名为Mixture-of-Depths(MoD)的Transformer模型,该模型能够根据序列中特定位置的需要动态分配计算资源,它通过限制每层中参与自注意力和多层感知机(MLP)计算的标记数量来实现这一点,利用一个顶部路由机制来决定哪些标记被处理,在保持静态计算图的同时,在不同层和模型深度上优化计算分配。
关注下方《人工智能学起来》
回复“TR魔改”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









