






LSTM+Transformer是非常热门且好发顶会的方向!
目前,其在CV、NLP、时间序列等领域,都取得了令人瞩目的成果。比如模型LTARM,直接登顶Nature子刊,在多任务预测中,性能和计算效率都远超SOTA;ICCV上的SwinLSTM模型,则误差狂降584%倍……
主要在于,这种结合,既能处理长期依赖,又能并行处理整个序列,大大提高了计算效率。同时,LSTM与Transformer的互补性,也使得混合模型在处理长序列和短序列时都能取得更好的效果,具有更好的泛化能力和鲁棒性。
为了让伙伴们能够掌握这种结合的精髓,落地到自己的顶会中,我特地给大家整理了13种前沿创新思路,还配上了开源代码!
论文原文+开源代码需要的同学看文末
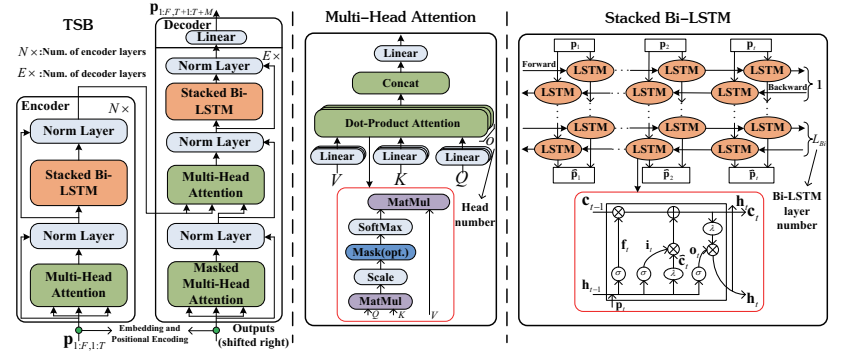
论文:Multi-Channel Multi-Step Spectrum Prediction Using Transformer and Stacked Bi-LSTM
内容
该论文提出了一种基于Transformer和堆叠双向长短期记忆网络(Bi-LSTM)的多通道多步谱预测方法,名为TSB。该方法利用多头注意力机制和堆叠Bi-LSTM来构建基于编码器-解码器架构的新Transformer,以深度捕捉多通道谱数据的长期依赖性。通过在真实模拟平台上生成的数据集进行广泛实验,表明TSB算法的性能优于基线算法。
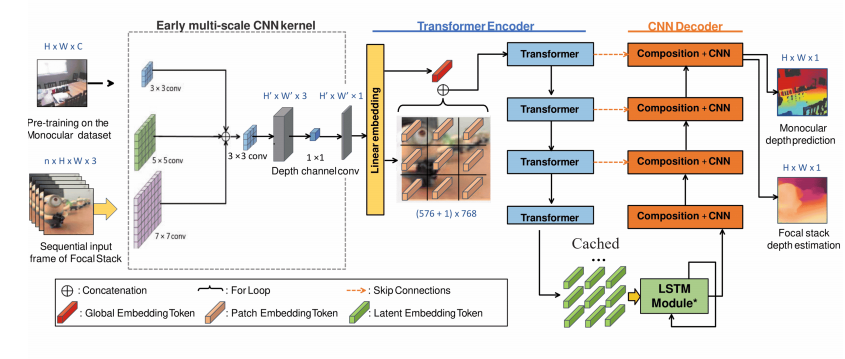
论文:FocDepthFormer: Transformer with LSTM for Depth Estimation from Focus
内容
该论文提出的FocDepthFormer是一种基于Transformer的深度估计网络,它通过整合Transformer编码器、LSTM模块和CNN解码器来处理焦点堆叠图像。该模型利用自注意力机制捕捉非局部空间特征,并使用LSTM处理不同长度的图像堆叠,从而提高对任意长度焦点堆叠的泛化能力。
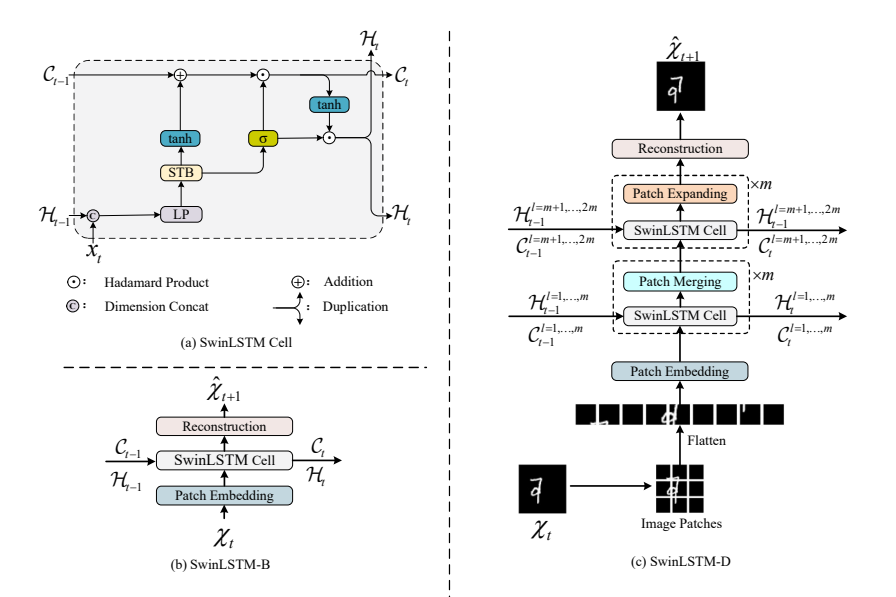
论文:SwinLSTM:Improving Spatiotemporal Prediction Accuracy using Swin Transformer and LSTM
内容
该论文提出的SwinLSTM是一种新型的循环单元,它结合了Swin Transformer模块和简化的LSTM,用于提高时空预测任务的准确性。该模型通过自注意力机制捕捉全局空间依赖,从而更有效地捕获时空依赖关系,在多个评估指标上优于现有的ConvLSTM等方法,展现了显著的预测性能提升。
论文:Deep Analysis of Time Series Data for Smart Grid Startup Strategies: A Transformer-LSTM-PSO Model Approach
内容
该论文提出了一种基于Transformer-LSTM-PSO模型的智能电网启动策略深度分析方法。该模型结合了Transformer的自注意力机制、LSTM的时间序列建模能力和粒子群优化算法的参数调整功能,旨在更有效地捕捉电网启动方案中的复杂时间关系,通过在多个数据集上的实验,该模型在预测准确性和效率上显示出显著的改进。
关注下方《AI科研圈圈》
回复“LMTS”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









