







 塔吊识别数据集 yolo格式 共5076张图片 已划分好训练验证 txt格式 yolo可直接使用。 类别:塔吊(Tower-crane) 一种 训练数据已划分,配置文件稍做路径改动即可训练。 训练集: 4724 (正面3224 + 负面1500) 验证集: 1352 (正面902 + 负面450) 另外:含内含模型 识别精度:90%+(内含模型 识别精度:90%+)
塔吊识别数据集 yolo格式 共5076张图片 已划分好训练验证 txt格式 yolo可直接使用。 类别:塔吊(Tower-crane) 一种 训练数据已划分,配置文件稍做路径改动即可训练。 训练集: 4724 (正面3224 + 负面1500) 验证集: 1352 (正面902 + 负面450) 另外:含内含模型 识别精度:90%+(内含模型 识别精度:90%+)
吊塔识别数据集 yolo格式共5076张图片 已划分好训练验证 txt格式 yolo练. 塔吊数据集 txt格式 yolo可直接使用 内含模型 识别精度:90%+


数据集概述
该数据集专注于塔吊(Tower-crane)的识别,包含5076张图片,并已按照Yolo格式标注好。数据集已按照训练集和验证集进行了划分,其中训练集包含4724张图片(正面3224张 + 负面1500张),验证集包含1352张图片(正面902张 + 负面450张)。所有标注文件均为.txt格式,可以直接用于Yolo框架下的模型训练。
数据集特点
- 单一类别:数据集中只包含塔吊这一类别的目标。
- 明确的数据划分:数据集按照标准的比例划分为训练集和验证集,便于模型训练和性能评估。
- 适用性强:YOLO格式的标注文件方便使用YOLO框架进行训练,减少了数据预处理的工作量。
数据集内容
- 图像文件:共有5076张JPG/PNG格式的图像文件。
- 标注文件:每张图像都配有YOLO格式的
.txt标注文件。
数据集结构示例
假设数据集的根目录为 tower_crane_dataset,其结构可能如下所示:
tower_crane_dataset/
├── images/
│ ├── train/
│ │ ├── positive/
│ │ │ ├── train_positive_0001.jpg
│ │ │ ├── train_positive_0002.jpg
│ │ │ └── ...
│ │ ├── negative/
│ │ │ ├── train_negative_0001.jpg
│ │ │ ├── train_negative_0002.jpg
│ │ │ └── ...
│ ├── val/
│ │ ├── positive/
│ │ │ ├── val_positive_0001.jpg
│ │ │ ├── val_positive_0002.jpg
│ │ │ └── ...
│ │ ├── negative/
│ │ │ ├── val_negative_0001.jpg
│ │ │ ├── val_negative_0002.jpg
│ │ │ └── ...
└── labels_yolo/
├── train/
│ ├── train_positive_0001.txt
│ ├── train_positive_0002.txt
│ └── ...
├── val/
│ ├── val_positive_0001.txt
│ ├── val_positive_0002.txt
│ └── ...数据集配置文件 data.yaml
创建一个data.yaml文件来描述您的数据集。这里假设数据集被放置在一个名为tower_crane_dataset的目录中,且包含images和labels子目录。
# data.yaml 文件
train: ../tower_crane_dataset/images/train/
val: ../tower_crane_dataset/images/val/
nc: 1 # number of classes
names: ['Tower-crane'] # class names关键训练代码
安装YOLOv5和YOLOv8
如果您还没有安装YOLOv5和YOLOv8,请按照官方文档执行以下命令:
# 安装YOLOv5
git clone https://github.com/ultralytics/yolov5.git # clone repo
cd yolov5
pip install -r requirements.txt # install dependencies
# 安装YOLOv8
git clone https://github.com/ultralytics/ultralytics.git # clone repo
cd ultralytics
pip install -r requirements.txt # install dependencies使用YOLOv5训练
使用以下命令开始训练模型:
cd yolov5
python train.py --img 640 --batch 16 --epochs 300 --data ../tower_crane_dataset/data.yaml --weights yolov5s.pt --cache使用YOLOv8训练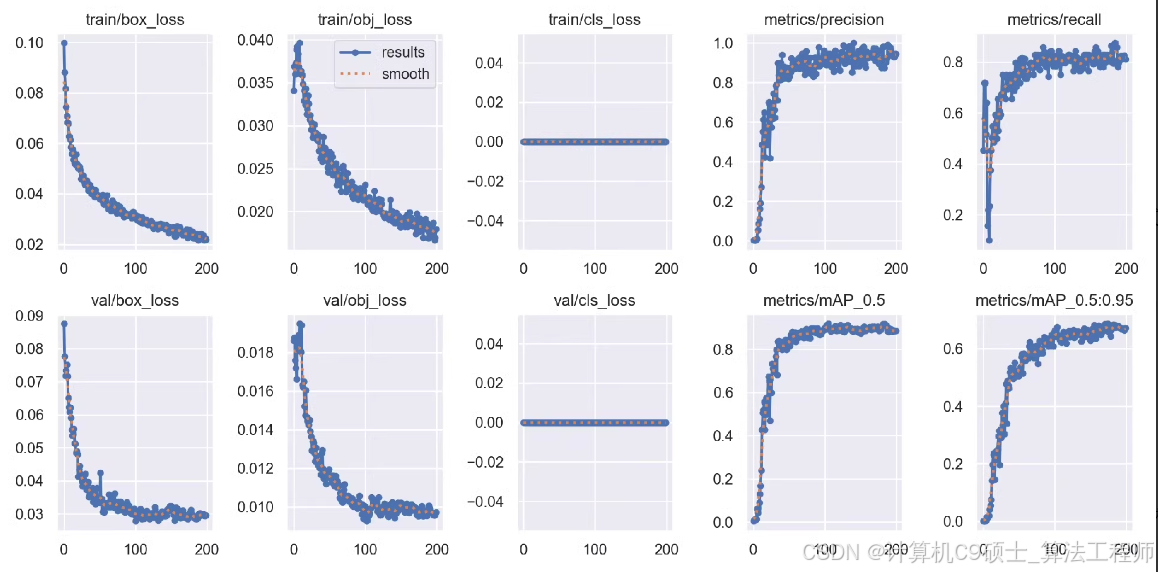
使用以下命令开始训练模型:
cd ultralytics
python train.py --img 640 --batch 16 --epochs 300 --data ../tower_crane_dataset/data.yaml --weights yolov8n.pt --cache自定义训练脚本
如果需要更详细的控制,可以编写一个Python脚本来执行训练过程。以下是一个简单的脚本示例:
import torch
from ultralytics import YOLO # 使用YOLOv8的API
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data_yaml = '../tower_crane_dataset/data.yaml'
# 加载预训练模型
model = YOLO('yolov8n.pt').to(device) # 使用YOLOv8n作为基础模型
# 设置训练参数
epochs = 300
batch_size = 16
img_size = 640
# 开始训练
model.train(data=data_yaml, epochs=epochs, batch=batch_size, imgsz=img_size, device=device)
# 保存模型
model.save('trained_model.pt')
print('Training complete.')
if __name__ == '__main__':
main()注意事项
- 确保
data.yaml文件中的路径是正确的,并且数据集的结构与上面描述的一致。 - 调整批量大小、学习率、迭代次数等超参数以适应您的计算资源和任务需求。
- 如果数据集很大,您可能需要更多的计算资源和时间来完成训练。
- 这个脚本仅作为一个起点,您可能需要根据实际情况做进一步的修改。
测试模型
在训练完成后,您可以使用以下命令测试模型的性能:
# 使用YOLOv5测试
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.4 --source ../tower_crane_dataset/images/val/positive/
# 使用YOLOv8测试
python detect.py --weights trained_model.pt --img 640 --conf 0.4 --source ../tower_crane_dataset/images/val/positive/使用预训练模型进行测试
如果您已经有了训练好的模型权重文件,可以直接使用它来进行测试。假设权重文件名为best.pt,可以使用以下命令:
# 使用YOLOv5测试
python detect.py --weights best.pt --img 640 --conf 0.4 --source ../tower_crane_dataset/images/val/positive/
# 使用YOLOv8测试
python detect.py --weights best.pt --img 640 --conf 0.4 --source ../tower_crane_dataset/images/val/positive/总结
这个示例展示了如何使用YOLOv5和YOLOv8框架训练一个基于塔吊识别的数据集。您可以根据自己的需求调整脚本中的参数和逻辑。通过使用这个数据集和相应的训练代码,您可以有效地训练出一个能够在多种条件下识别塔吊的模型。

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









