







采用时间序列分析和机器学习方法——处理 电动汽车充电站充电运营数据集_ 利用电动汽车充电站的多维度脱敏数据集来预测站点未来一周每日的充电量(以小时为单位)——
电动汽车充电站充电运营数据集应该怎么处理呢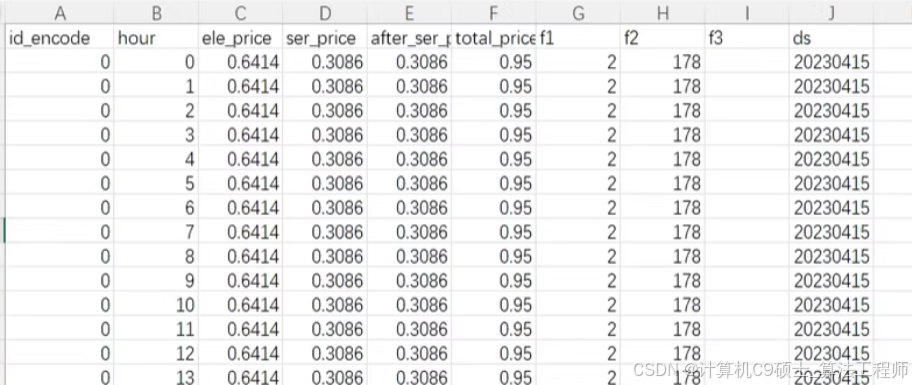
假设你有以下数据集 ,应该怎么处理呢
数据集-电动汽车充电站的场站编号、位置信息、历史电量等基本信息。根据所提供的电动汽车充电站多维度脱敏数据,构造合理特征及算法模型,预估站点未来一周每日的充电量(以小时为单位),并在已有数据的基础上补充或构造额外的特征,以获得更好的预测性能。
包含的数据表如下:
power _forecast_history.csv
power.csv
stub_info.csv
共3个csv数据表
power_forecast_history.csv 为站点运营数据
power.csv为站点充电量数据
stub_info.csv为站点静态数据
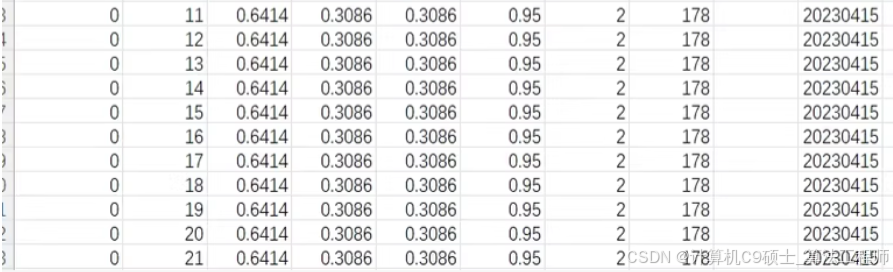
训练集为历史一年的数据,测试集为未来一周的数据。数据字段的具体情况如下所示: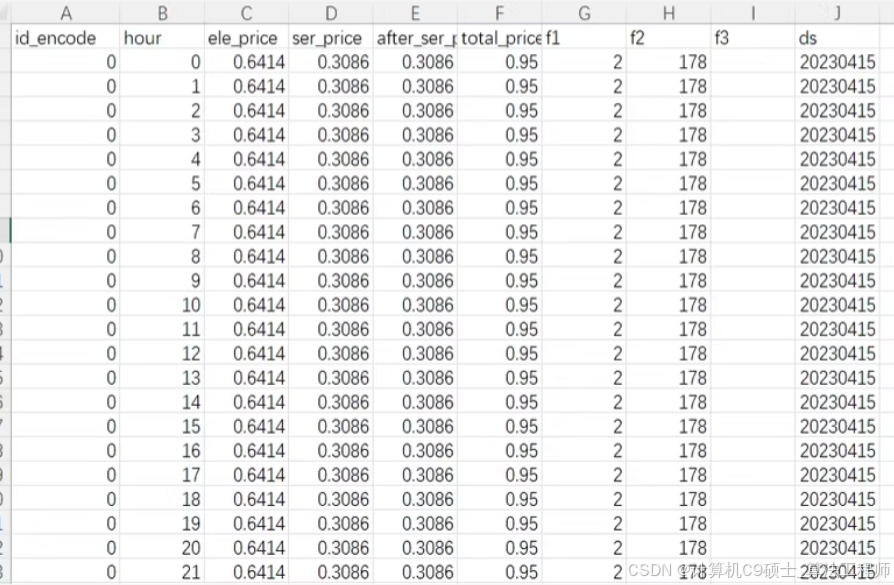
power_forecast_history.csv
1.id_encode:场站编码
2.hour:小时
3.ele_price:电费
4.ser_price:服务费
5. after _ser_price:折后服务费
6.total_price:总费用
7.f1:业务指标1
8.f2: 业务指标2
9.f3: 业务指标3
10.ds:日期
以下文字及代码仅供参考
利用电动汽车充电站的多维度脱敏数据集来预测站点未来一周每日的充电量(以小时为单位),我们将采用时间序列分析和机器学习方法。下面是一个详细的流程指南,包括数据理解与准备、特征工程、模型选择与训练、评估和部署。
1. 数据加载与理解
首先,我们需要加载并理解提供的三个CSV文件的内容。
import pandas as pd
# 加载数据表
power_forecast_history = pd.read_csv('path/to/power_forecast_history.csv')
power = pd.read_csv('path/to/power.csv')
stub_info = pd.read_csv('path/to/stub_info.csv')
# 查看数据结构
print(power_forecast_history.head())
print(power.head())
print(stub_info.head())
# 检查数据的基本信息
print(power_forecast_history.info())
print(power.info())
print(stub_info.info())
2. 数据预处理
合并数据表
我们需要将这些数据表合并到一个包含所有相关信息的数据集中。
# 将日期时间字段转换为datetime类型
power['ds'] = pd.to_datetime(power['ds'])
power_forecast_history['ds'] = pd.to_datetime(power_forecast_history['ds'])
# 合并power和power_forecast_history基于场站编码和日期
merged_data = pd.merge(power, power_forecast_history, on=['id_encode', 'hour', 'ds'], how='left')
# 合并静态站点信息
merged_data = pd.merge(merged_data, stub_info, left_on='id_encode', right_on='桩ID', how='left')
处理缺失值
检查并处理任何缺失值。
# 检查缺失值
print(merged_data.isnull().sum())
# 根据具体情况填充或删除缺失值
merged_data.fillna(method='ffill', inplace=True) # 前向填充
3. 特征工程
构造额外的特征可以帮助提高模型的表现。
- 时间特性:从日期中提取年、月、日、周几等。
- 循环特性:对周期性变量如小时进行sin/cos变换。
- 滞后特征:创建过去几个时间段的充电量作为新特征。
- 滚动窗口统计:计算滚动平均、标准差等统计量。
- 外部因素:如果可用,引入天气数据、节假日信息等。
# 提取时间特性
merged_data['year'] = merged_data['ds'].dt.year
merged_data['month'] = merged_data['ds'].dt.month
merged_data['day'] = merged_data['ds'].dt.day
merged_data['day_of_week'] = merged_data['ds'].dt.dayofweek
# 循环特性
merged_data['hour_sin'] = np.sin(2 * np.pi * merged_data['hour'] / 24)
merged_data['hour_cos'] = np.cos(2 * np.pi * merged_data['hour'] / 24)
# 滞后特征
for lag in [1, 7, 30]:
merged_data[f'lag_{lag}'] = merged_data.groupby(['id_encode'])['充电电量'].shift(lag)
# 滚动窗口统计
merged_data['rolling_mean_7d'] = merged_data.groupby(['id_encode'])['充电电量'].transform(lambda x: x.rolling(window=7).mean())
merged_data['rolling_std_7d'] = merged_data.groupby(['id_encode'])['充电电量'].transform(lambda x: x.rolling(window=7).std())
4. 模型选择与训练
我们可以使用时间序列预测模型如ARIMA、Prophet,或者更复杂的机器学习模型如随机森林、梯度提升树(GBDT)、LSTM等。这里我们选择使用XGBoost作为示例。
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor
from sklearn.metrics import mean_squared_error
# 准备训练数据
features = ['ele_price', 'ser_price', 'after_ser_price', 'total_price', 'f1', 'f2', 'f3',
'year', 'month', 'day', 'day_of_week', 'hour_sin', 'hour_cos',
'lag_1', 'lag_7', 'lag_30', 'rolling_mean_7d', 'rolling_std_7d']
target = '充电电量'
X = merged_data[features]
y = merged_data[target]
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = XGBRegressor(n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)
model.fit(X_train, y_train)
# 预测并评估模型
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
5. 模型评估与优化
评估模型性能,并尝试调整超参数或引入更多特征来提高模型的表现。
from sklearn.model_selection import GridSearchCV
# 超参数调优
param_grid = {
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 5, 7]
}
grid_search = GridSearchCV(estimator=XGBRegressor(random_state=42), param_grid=param_grid, cv=3, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
best_model = grid_search.best_estimator_
print("Best parameters found: ", grid_search.best_params_)
6. 测试与推理
在测试集上评估模型表现,并保存最佳模型用于后续的推理任务。
# 使用最佳模型进行预测
final_predictions = best_model.predict(X_test)
# 保存预测结果
pd.DataFrame({'ds': merged_data.loc[X_test.index, 'ds'], '预测充电电量': final_predictions}).to_csv('predictions.csv', index=False)
7. 部署与监控
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用环境中。这可能涉及到将模型导出为ONNX格式或其他适合部署的格式,以及编写相应的API接口来接收实时数据输入并返回预测结果。
注意事项
- 持续改进:随着新数据的积累,模型可能需要不断更新和优化。
- 解释性:为了提高模型的信任度,可以使用SHAP值或其他解释性工具来解释模型决策过程。
- 外部数据源:考虑引入更多的外部数据源,例如天气预报、节假日信息等,以提高预测准确性。
那么,这个就是 ——针对电动汽车充电站充电运营数据集的一个完整解决方案。


















 3242
3242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









