







参考论文:Knowledge Distillation: A Survey
1.前言
近年来,深度学习在学术界和工业界取得了巨大的成功,根本原因在于其可拓展性和编码大规模数据的能力。但是,深度学习的主要挑战在于,受限制于资源容量,深度神经模型很难部署在资源受限制的设备上。如嵌入式设备和移动设备。因此,涌现出了大量的模型压缩和加速技术,知识蒸馏是其中的代表,可以有效的从大型的教师模型中学习到小型的学生模型。本文从知识类别、训练模式、师生架构、蒸馏算法、性能比较和应用等方面对知识蒸馏进行了综述。
提到了近年来深度学习在计算机视觉、强化学习和自然语言处理上的一些进展,指出主要挑战在于大模型在实际应用中的部署。为了开发高效的深度模型,近年来的研究主要集中在深度模型的开发上:(1)深度神经网络高效快的构建;(2)模型压缩和加速技术,主要包含以下:
- 参数剪枝和共享:该方法专注于去除模型中的不必要参数 低秩分解:
- 该方法利用矩阵分解和张量分解来识别深度神经网络的冗余参数;
- 转移紧凑型卷积滤波器:该方法通过转移或压缩卷积滤波器来去除不必要的参数;
- 知识蒸馏(KD):该方法将知识从一个较大的深度神经网络中提取到一个较小的网络中

为了解决大模型的线上部署问题,Bucilua et al. (2006)首先提出了模型压缩,在不显著降低精度的情况下,将大模型或模型集合中的信息转换为训练小模型。在半监督学习中,引入了完全监督的教师模型和使用无标记数据的学生模型之间的知识转移。从小模型到大模型的学习后来被正式命名为为知识蒸馏(Hinton )。知识蒸馏主要思想是:学生模型模仿教师模型,二者相互竞争,是的学生模型可以与教师模型持平甚至卓越的表现。关键问题是如何将知识从大的教师模型转移到小的学生模型。知识蒸馏系统由知识、蒸馏算法和师生架构三个关键部分组成。如上图所示。
虽然在实践中取得了巨大的成功,但无论是理论还是经验上对知识蒸馏的理解都不多。关于知识蒸馏的原理,Urner等利用无标记数据证明了从教师模型到学生模型的知识转移是PAC可学习的;Phuong & Lampert通过在深度线性分类器场景下学习蒸馏学生网络的快速收敛获得了知识蒸馏的理证明,这个论证回答了学生学习的内容和速度,并揭示了决定蒸馏成功的因素,成功的蒸馏依赖于数据的分布、蒸馏目标的优化偏差和学生分类器的强单调性;Cheng等人量化了从深度神经网络的中间层中提取视觉概念,以解释知识蒸馏;Ji和Zhu分别从风险界、数据效率和不完善教师三个方面对广义神经网络知识蒸馏进行了理论解释;Cho和Hariharan对知识蒸馏的功效进行了详细的实证分析;Mirzadeh et al.的实证结果表明,由于模型能力差距的存在,模型越大的教师未必就越优秀;Cho and Hariharan (2019)的实验也表明,蒸馏对学生的学习有不利影响。知识蒸馏的不同形式对知识、蒸馏和师生互动的经验评价不包括在内;知识蒸馏也被用于标签平滑、评估教师的准确性和获得最佳输出层参数分布先验。
知识蒸馏与人的学习过程类似,基于此,近年来的一些研究拓展了教师—学生模型,发展为mutual learning、lifelong learning和self-learning。同时受到知识蒸馏在模型压缩中的影响,知识迁移已经被用在了压缩数据上,如dataset distillation。
文章结构图

2.知识(Knowledge)
在知识蒸馏中,知识类型、蒸馏策略和师生架构对学生模型的学习起着至关重要的作用。原始知识蒸馏使用大深度模型的对数作为教师知识(Hinton 2015),中间层的激活、神经元或特征也可以作为指导学生模型学习的知识,不同的激活、神经元或成对样本之间的关系包含了教师模型所学习到的丰富信息.此外,教师模型的参数(或层与层之间的联系)也包含了另一种知识,本节主要讨论以下几种类型的知识:基于响应的知识(response-based knowledge),基于特征的知识( feature-based knowledge), 基于关系的知识(relation-based knowledge),下图为教师模型中不同知识类别的直观示例。

2.1. 基于响应的知识(Response-Based Knowledge)
Response-Based Knowledge通常是指教师模型的最后一输出层的神经反应。其主要思想是让学生模型直接模仿教师模式的最终预测(logits),假定对数向量Z为全连接层的最后输出,response-based knowledge蒸馏形式可以被描述为:
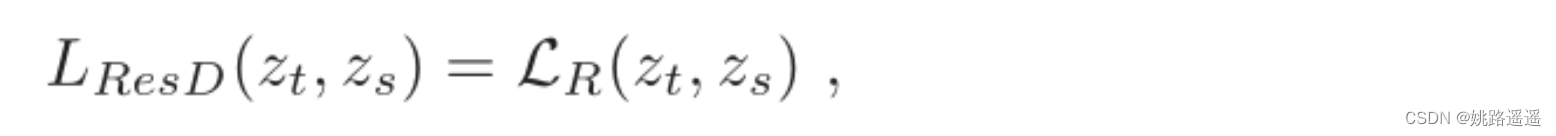
LR(.) 表示散度损失(这里也可以是用交叉熵损失),如下图所示为Response-Based 知识蒸馏模型图。
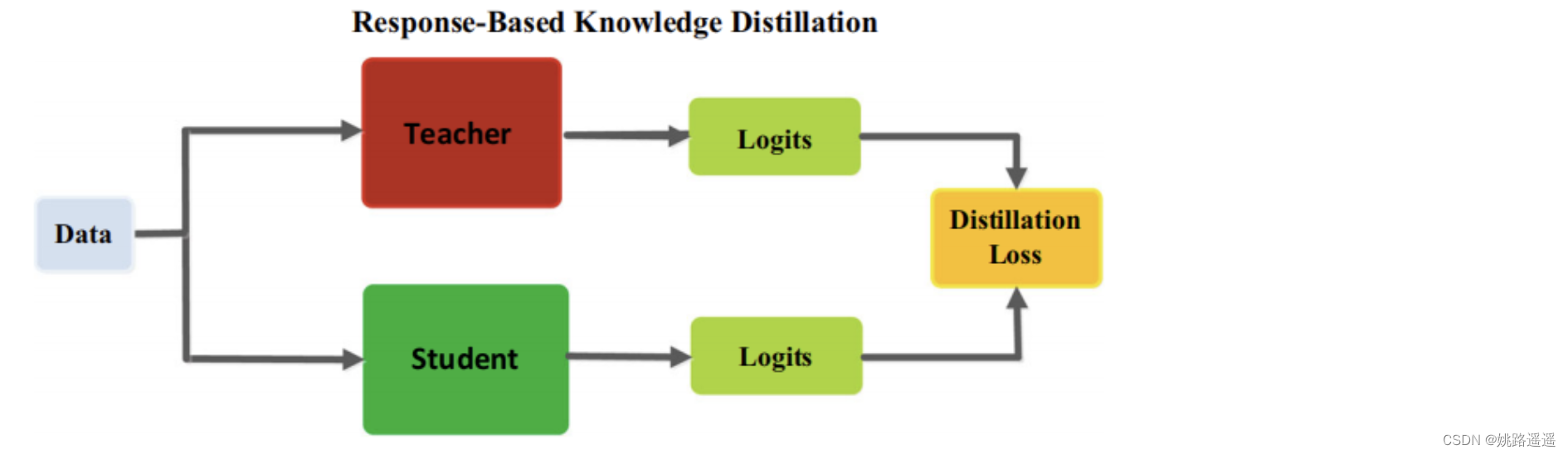
基于响应的知识可以用于不同类型的模型预测。例如,在目标检测任务中的响应可能包含bounding box的偏移量的logits;在人类姿态估计任务中,教师模型的响应可能包括每个地标的热力图。最流行的基于响应的图像分类知识被称为软目标(soft target)。软目标是输入的类别的概率,可以通过softmax函数估计为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









