








本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大力量,本文是第三篇:分词(Tokenizer);在上一篇文章Embedding中,我们介绍了Transformer架构中的Embedding,它将输入的文本转换为模型可以理解的数字向量,而分词是Embedding之前非常重要的一个步骤。
在接下来的文章中,将详细讲解分词的流程,算法以及Transformer,GPT中用到的分词算法。
01 分词介绍
分词是Transformer架构中Embedding之前非常重要的一步。
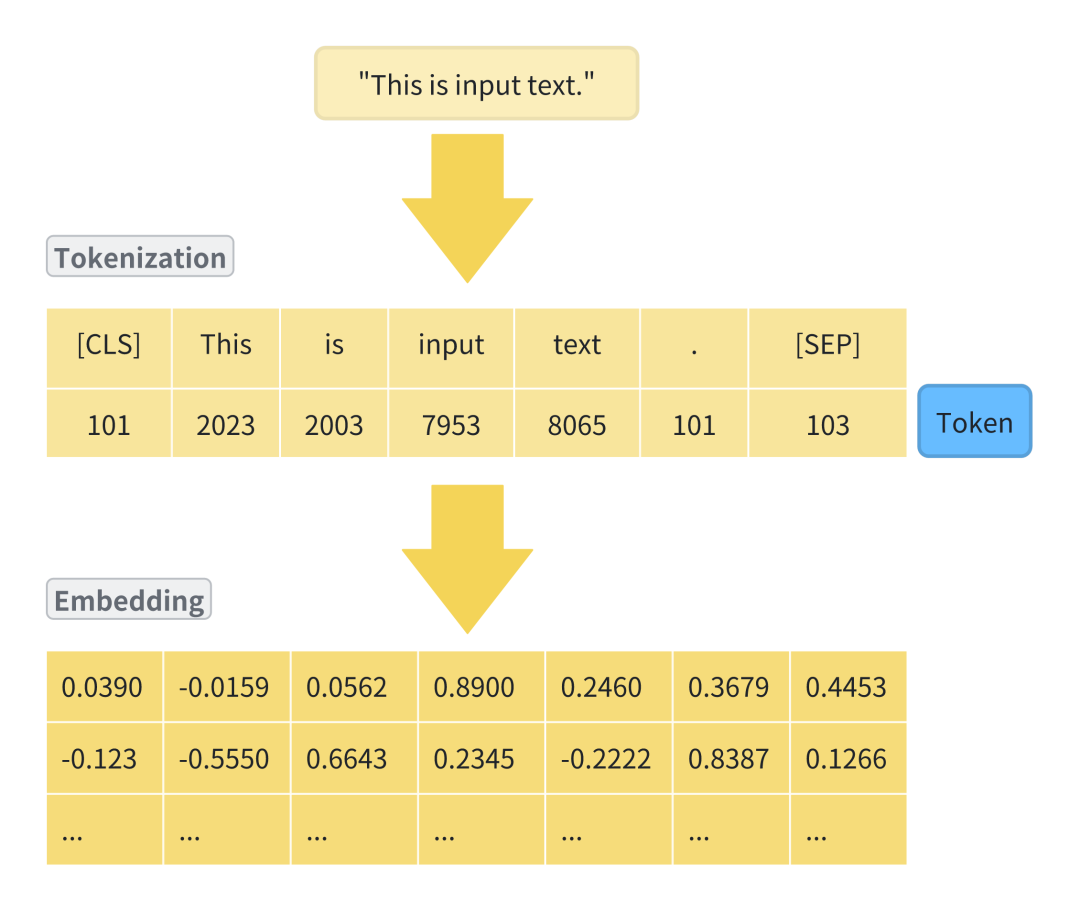
它将文本拆分为模型或机器可以处理的小单位,并分配一个唯一的标识符(Token);就像我们学习外语时,首先要学习字母和单词一样,分词是模型或机器学习语言的第一步。


分词可视化工具,请访问https://tiktokenizer.vercel.app/
02 分词流程
分词的流程通常包括Normalization, Pre-tokenization, Model和Post-tokenization。
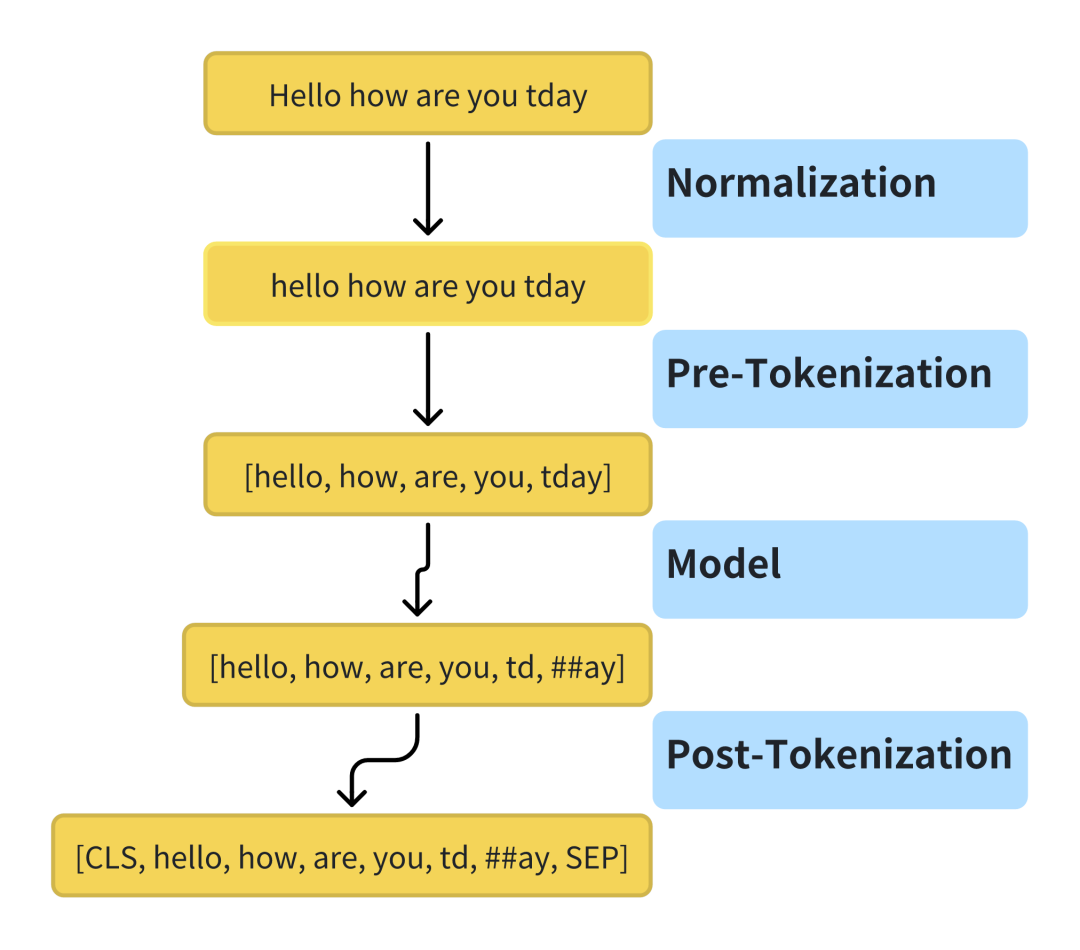
Normalization
Normalization主要包括以下几个方面:
-
文本清洗
-
去除无用字符:移除文本中的特殊字符、非打印字符等,只保留对分词和模型训练有意义的内容。
-
去除额外空白:消除文本中多余的空格、制表符、换行符等,统一文本格式。
-
-
标准化写法
-
统一大小写:将所有文本转换为小写或大写,减少大小写变体带来的影响。
-
数字标准化:将数字统一格式化,有时候会将所有数字替换为一个占位符或特定的标记,以减少模型需要处理的变量数量。
-
-
编码一致性
-
字符标准化:确保文本采用统一的字符编码(如UTF-8),处理或转换特殊字符和符号。
-
-
语言规范化
-
词形还原(Lemmatization):将单词还原为基本形式(lemma),例如将动词的过去式还原为一般现在时。
-
词干提取(Stemming):去除单词的词缀,提取词干,这是一种更粗糙的词形还原方式。
-
Pre-tokenization
Pre-tokenization是基于一些简单的规则(如空格和标点)进行初步的文本分割,这一步骤是为了将文本初步拆解为更小的单元,如句子和词语;对于英文等使用空格分隔的语言来说,这一步相对直接,但对于中文等无空格分隔的语言,则可能直接进入下一步。
Model
Model是分词的核心部分,在Pre-tokenization的基础上,根据选定的模型或算法(BPE,WordPiece,Unigram语言模型(LM)或SentencePiece等)进行更细致的处理,包括通过大量文本数据,根据算法规则生成词汇表(Vocabulary), 然后依据词汇表,将文本拆分为Token。
在自然语言处理模型中,确定合适的词汇表大小是一个关键步骤,它直接影响模型的性能、效率以及适应性;理想的词汇表应该在保证模型性能和效率的同时,满足特定任务和数据集的需求。
较大的词汇表意味着模型需要更多的计算资源来处理和存储分词嵌入,在资源有限的环境下,过大的词汇表可能导致训练和推理过程变得低效。
词汇表的大小也会影响模型的处理速度,较大的词汇表可能增加模型在进行词嵌入查找和生成输出时的计算负担,从而减慢处理速度。
较大的词汇表可以提高模型覆盖不同词汇和表达的能力,有助于模型更好地理解和生成文本;然而,过大的词汇表也可能导致模型在某些Token上的训练不足,影响其泛化能力。
一个庞大的词汇表可能导致词嵌入空间的稀疏性问题,使得模型难以有效学习某些较少见的Token的表示。
不同的自然语言处理任务可能需要不同大小的词汇表。例如,精细的文本生成任务可能需要较大的词汇量以覆盖更多细节,而一些分类任务则可能只需较小的词汇表即可达到较高性能。
特定任务可能需要引入特殊Token(如控制代码,隐私标记等,这些在LLM如何通过监督学习使用Tools中有应用到),这也需要在设置词汇表时考虑。
不同语言的结构差异意味着对词汇表的需求也不同。例如,拼接语(如德语)可能需要更大的词汇量来覆盖其丰富的复合词形态。
数据集中文本的复杂性和多样性也影响词汇表的设置,丰富多变的数据集可能需要更大的词汇量来捕获文本的多样性。
如上所述,在实际应用中,可能需要通过实验和调整来找到最适合特定模型和任务的词汇表大小,下面是各大LLM词汇表的大小和性能对比:
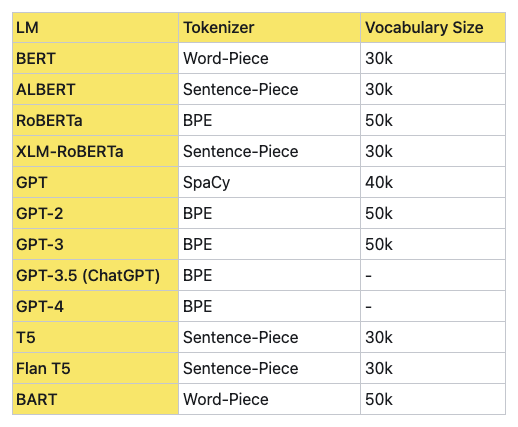
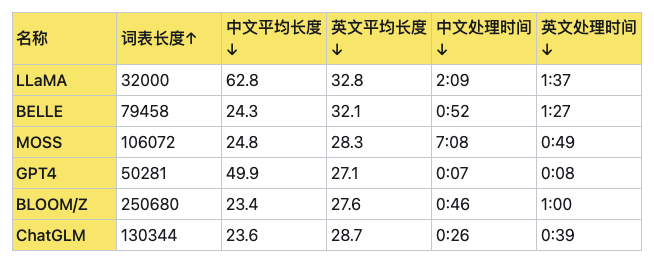
Post-tokenization
Post-tokenization主要包括:
-
序列填充与截断:为保证输入序列的长度一致,对过长的序列进行截断,对过短的序列进行填充。
-
特殊Token添加:根据模型需求,在序列的适当位置添加特殊Token(如[CLS], [SEP])。
-
构建注意力掩码:对于需要的模型,构建注意力掩码以区分实际Token和填充Token。
03 分词算法
Tokenizer按粒度分,常见的有:
-
按单词划分(word base): 按照词进行分词, 如英文Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .]
-
按字符划分(character base):按照单字符进行分词,就是以char为最小粒度, 如英文Today is sunday. 则会分割成[t, o, d,a,y,i, s, s,u,n,d,a,y,.]
-
按子单词划分(subword tokenization):按照词的subword进行分词,如英文Today is sunday. 则会分割成[to, day,is , s,un,day, .]
按单词划分简单易理解,每个word都分配一个ID,所需的词汇表会根据语料库大小而不同,而且这种分词方式,会将两个本身意思一致的词分成两个毫不同的ID,在英文中尤为明显,如cat,cats。
按字符划分,此种现象会有所减缓,而且词汇表相对小的多,但分词后的每个char字符是毫无意义的,而且输入的长度变长不少,只有合并后才有意义,这种分词在模型的初始character embedding是无意义的,英文中尤为明显,但中文是较为合理的,在中文中用得比较多。
最后,为了平衡以上两种方法, 提出了subword tokenization,典型的有Byte Pair Encoding (BPE),Wordpiece,Unigram和SentencePiece。
BPE
BPE最初是作为一种数据压缩技术提出的,后来被应用于自然语言处理领域,特别是在LLM的Tokenizer过程中;BPE的核心思想是通过迭代合并文本数据中最频繁出现的字符或字符序列来动态构建词汇表;这个过程从字符级别开始,逐渐构建出更长的词汇或短语表示,直到达到预设的词汇表大小或合并次数为止。
BPE标记化的主要步骤如下:
-
初始化:以单个字符初始化词汇表的元素。
-
统计共现频率:计算所有相邻字符对的共现频率。
-
合并操作:选择最频繁出现的字符对,将它们合并为新的词汇表项。
-
重复:重复上述过程,直到达到预设的合并次数或词汇表大小。
OpenAI从GPT2开始就是使用的这种分词方式。
WordPiece
WordPiece在选择要合并的字符或词对时采取了更为复杂的策略;它不仅计算这些组合的频率,还考虑了合并后带来的概率增益。
这意味着WordPiece在构建词汇表时,会更倾向于选择那些能够显著提高文本表示准确性的单元。Google的BERT模型就是采用了WordPiece作为其分词器,这也是BERT在多种语言任务上表现出色的原因之一。
Unigram
Unigram方法采用的是一种概率统计的方式,它会预测每个单词作为独立单元出现的概率(基于朴素贝叶斯统计),并基于这个概率来进行分词。这个过程中,某些词可能会被拆分成更小的单元,以便模型可以更灵活地处理语言中的变化和新词。
Unigram的一个关键优势是其能够自动适应不同语言的特性,使得模型在处理多语言文本时更加高效,它在GPT-1中被使用。
总结一下:
-
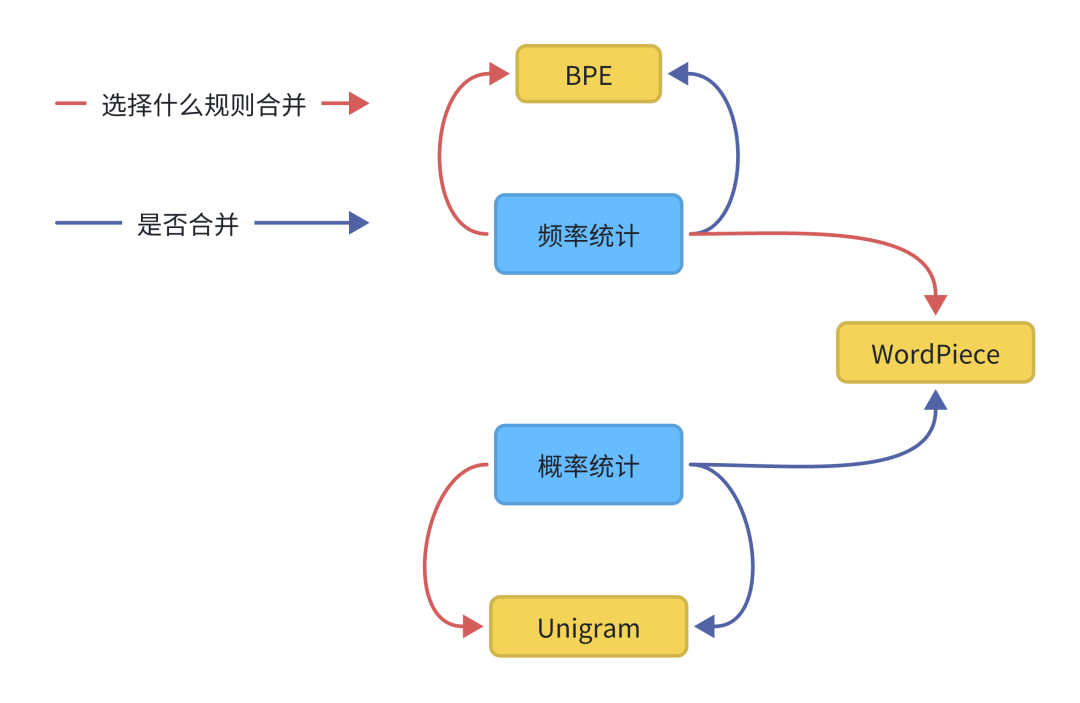
BPE是在每次迭代中只使用出现频率来识别最佳匹配,直到达到预定义的词汇量大小。
-
WordPiece类似于BPE,使用频率出现来识别潜在的合并,但根据合并词前后分别出现的可能性概率大小,进行是否合并。
-
Unigram没有频率出现的概率模型进行直接分词,相反,它使用概率模型训练语言模型(LM),移除使得最大似然概率减小最小的子词,然后进行反复计算,达到最大似然概率。
SentencePiece
SentencePiece是Google推出的subword开源工具包,集成了BPE和Unigram;除此之外,SentencePiece还能支持字符和词级别的分词。
SentencePiece主要解决了以下三点问题:
-
以unicode方式编码字符,将所有的输入(英文、中文等不同语言)都转化为unicode字符,解决了多语言编码方式不同的问题。
-
将空格编码为‘_’, 如'New York' 会转化为['_', 'New', '_York'],这也是为了能够处理多语言问题,比如英文解码时有空格,而中文没有, 这种语言区别。
-
优化了速度,如果您实时处理输入并对原始输入执行标记化,则速度会太慢。SentencePiece通过使用BPE算法的优先级队列来加速它来解决这个问题,以便您可以将它用作端到端解决方案的一部分。
如果任务涉及到多语言处理,特别是包含无空格分隔的语言,SentencePiece可能是一个好的选择。对于希望在词汇丰富度和处理未知词上取得平衡的项目,BPE或WordPiece可能更加合适。而如果项目特别注重于统计特性和语言模型的精确性,Unigram或许能提供更好的支持。
04 总结
分词是Transformer架构或者NLP中非常重要的一步,选择合适的分词方法对于模型非常重要。
随着NLP技术的不断进步,Tokenizer技术也在持续发展中,未来可能将不仅仅是要将文本转换为模型可理解格式,而是要扩展到语音和图像特征级别的数据,将更加智能化,包括细粒度,跨模态,自适应和可学习的Tokenizer技术。
同时,随着对AI伦理和隐私保护的重视,未来的Tokenizer技术将更加注重安全性和隐私保护;这可能包括开发新的技术来匿名化敏感信息、防止数据泄露,并确保在模型训练和推理过程中保护用户隐私。















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









