








添加图片注释,不超过 140 字(可选)
本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大,本文是第五篇:Transformer输入详解。
接下来,我们将逐层剖析Transformer如何接收并处理输入数据,从定义数据集到计算位置编码,每一步都至关重要;通过本文,朋友们将深刻理解Transformer输入处理流程,并学会如何准备数据以供模型学习;我们将使用一个简化的数据集来直观展示数值计算过程,帮助朋友们更好地理解这一复杂但强大的架构。
01 定义数据集
ChatGPT创建时使用的数据集大小大概是570GB的资料,为了能简单直观地讲解,今天我们将使用一个非常小的数据集来进行数值计算的可视化。

添加图片注释,不超过 140 字(可选)
02 定义词汇表
词汇量指的是数据集中唯一分词(Token)的总数,它可以使用以下公式计算,其中N表示数据集中的Token总数。
本文之后都把这里的唯一分词表述为Token。
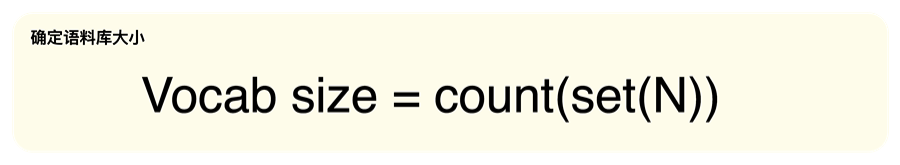
添加图片注释,不超过 140 字(可选)
为了能找到N,我们需要将数据集拆分为Token,也就是我们本系列文章第三篇Tokenization。

添加图片注释,不超过 140 字(可选)
在获取到N后,我们进行一个集合操作来去除重复的单词,然后就可以统计唯一Token的数量,确定词汇量的大小。

添加图片注释,不超过 140 字(可选)
因此,词汇量大小为16,即数据集中有16个唯一Token。
03 分词编码
现在,我们需要为每个唯一的Token分配一个唯一的数字。

添加图片注释,不超过 140 字(可选)
简单来说,我们将一个Token视为一个单词,并为其分配一个数字,而ChatGPT不一定是一个单词一个Token,有可能单词的一部分视为一个Token,比如,本文数据集中的讲,神,架三个字都是被分成了2个Token;在ChatGPT中,平均大概1Token = 0.75个单词。
代码实现
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
input_str ="用简单语言讲解Transformer神经网络架构"
print(f"input_str: {input_str}")
# input_str: 用简单语言讲解Transformer神经网络架构
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
tokens = encoding.encode(input_str)
print(f"tokens: {tokens}")
# tokens: [11883, 99337, 24946, 73981, 78244, 10414, 110, 50338, 47458, 55228, 252, 54493, 72456, 20119, 114, 78935]
num_tokens = num_tokens_from_string("用简单语言讲解Transformer神经网络架构", "cl100k_base")
print(f"num_tokens: {num_tokens}")
# num_tokens: 16
decode_input_str = encoding.decode(tokens)
print(f"decode_input_str: {decode_input_str}")
# decode_input_str: 用简单语言讲解Trans 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









