






目录
源码获取方式在文章末尾
一、项目背景
在当今数字化时代,美食行业蓬勃发展且竞争日益激烈。大众点评等平台积累了海量的美食相关数据,这些数据蕴含着丰富的信息,例如消费者对美食的偏好、不同餐厅的经营状况、菜品的受欢迎程度趋势等。然而,面对如此庞大且复杂的数据量,传统的数据分析方法难以高效地挖掘出其中深层次的价值和规律,无法满足美食行业商家精准营销、菜品创新优化以及消费者个性化推荐等需求。随着大数据技术的不断演进,Spark 作为一种强大的分布式计算框架,能够处理大规模数据集并提供快速的数据处理能力。而长短期记忆网络(LSTM)在处理序列数据方面表现卓越,尤其适用于分析具有时间序列特征的美食数据,如用户在不同时间段对菜品的评价变化、餐厅客流量随时间的波动等。基于此,构建 Spark + LSTM 美食数据分析预测系统,旨在整合大众点评等多源美食数据,借助 Spark 的分布式计算优势和 LSTM 的深度学习能力,深度挖掘数据背后的潜在模式与趋势,为美食行业的各方参与者提供有价值的决策支持,助力美食行业在数据驱动下实现更高效、更精准的发展与运营。
二、研究目的
本项目旨在通过整合 Spark 与 LSTM 技术,深入分析大众点评上的美食数据,以实现以下多维度研:
精准销售预测:利用 LSTM 对餐厅历史销售数据(如订单量、营业额等时间序列信息)进行建模与分析,结合 Spark 的分布式数据处理能力处理大规模数据,准确预测餐厅未来不同时间段的销售情况。这有助于餐厅提前做好食材采购、人员调配等运营准备,降低成本并提高服务质量。
菜品推荐优化:基于对用户历史消费行为数据(包括菜品评价、点餐记录等)的挖掘,运用 Spark 进行数据预处理与特征提取,再通过 LSTM 分析用户消费序列模式,构建更为精准的个性化菜品推荐系统。不仅能提高用户点餐满意度,还能助力餐厅提高高利润菜品的销售占比。
市场趋势洞察:分析大众点评上美食数据的整体趋势,如不同菜系的流行度变化、消费者口味偏好的地域差异与时间演变等。借助 Spark 的大数据处理功能整合多地区、长时间跨度的数据,利用 LSTM 捕捉数据中的长期依赖关系,为美食行业从业者提供市场动态信息,以便及时调整菜品研发方向与营销策略。基于对用户历史消费行为数据(包括菜品评价、点餐记录等)的挖掘,运用 Spark 进行数据预处理与特征提取,再通过 LSTM 分析用户消费序列模式,构建更为精准的个性化菜品推荐系统。不仅能提高用户点餐满意度,还能助力餐厅提高高利润菜品的销售占比。
三、项目创新点
在本项目中,我们构建了一个基于Spark和LSTM的美食数据分析预测系统,针对大众点评数据进行深度挖掘和分析。项目创新点主要体现在以下几个方面:
- 高效数据处理与分布式架构:利用Spark的强大分布式计算能力,能够快速处理海量的大众点评数据。Spark的弹性分布式数据集(RDD)和数据帧(DataFrame)等数据抽象,使得数据的加载、清洗、转换等预处理操作高效且易于实现。同时,Spark的内存计算特性大大提高了数据处理的速度,为后续的深度学习模型训练提供了坚实的基础。此外,通过与Hive的无缝集成,能够方便地从Hive中读取和存储数据,充分利用了Hive在数据仓库方面的优势,实现了大规模数据的高效管理和分析。
- 深度学习模型的应用与优化:引入长短期记忆网络(LSTM)作为核心预测模型,充分发挥了其在处理时间序列数据方面的优势。通过对大众点评数据中用户的行为序列、商家的评分变化等时间相关特征的建模,LSTM能够有效捕捉数据中的长期依赖关系,从而更准确地预测用户的消费偏好、商家的未来评分趋势等。在模型训练过程中,我们对LSTM模型的结构和参数进行了精细的调整和优化,采用了诸如批量归一化、学习率衰减等技术,进一步提高了模型的性能和预测精度。
- 特征工程与多维度数据融合:在特征工程方面,我们不仅考虑了传统的用户和商家的基本属性特征,还深入挖掘了用户的行为特征、商家的口碑特征以及时间和空间维度上的特征。例如,用户的消费频率、消费金额分布、不同时间段的消费偏好等,商家的评分变化趋势、评论情感倾向、周边竞争环境等。通过将这些多维度的特征进行融合和转换,为LSTM模型提供了更丰富、更具代表性的输入,从而提高了模型对复杂数据模式的学习能力和预测效果。
- 预测与动态更新:系统具备实时预测的能力,能够根据最新的大众点评数据实时更新预测结果。通过设置合理的数据更新机制和模型重新训练策略,系统可以及时反映市场动态和用户行为的变化,为商家提供及时准确的市场趋势预测和用户画像,帮助商家更好地制定经营策略和营销方案。这种实时性和动态性是传统数据分析方法所难以实现的,也是本项目的一大创新亮点。
- 可视化展示与交互性:为了使数据分析和预测结果更加直观易懂,我们设计了友好的可视化界面。通过图表、地图等多种可视化方式,将用户的行为分析、商家的评分预测、市场趋势等信息直观地展示出来。同时,系统还提供了交互式功能,用户可以根据自己的需求选择不同的分析维度和时间范围,进行自定义的数据查询和可视化展示,极大地提高了系统的用户体验和实用性。
四、项目功能/数据流程分析
本项目旨在构建一个基于Spark和LSTM的美食数据分析预测系统,通过对大众点评数据的深度挖掘和分析,为用户提供精准的美食推荐和商家经营趋势预测。以下是项目功能与数据流程的详细分析:
数据流程
-
数据采集与存储
-
从大众点评平台获取原始数据,包括用户信息、商家信息、用户评论、评分、消费记录等。
-
将采集到的数据存储到Hive数据仓库中,利用Hive的分区和索引功能,实现高效的数据管理和查询。
-
-
数据预处理
-
数据清洗:使用Spark对数据进行清洗,去除重复数据、缺失值填充、异常值处理等。
-
特征提取:从用户行为、商家属性、评论情感等多个维度提取特征,生成用户画像和商家画像。
-
数据转换:将清洗后的数据转换为适合LSTM模型输入的格式,如时间序列数据。
-
-
模型训练与预测
-
模型选择与训练:选择LSTM作为核心预测模型,利用Spark的分布式计算能力加速模型训练过程。
-
预测任务:通过训练好的LSTM模型,对用户的消费偏好、商家的评分趋势等进行实时预测。
-
模型评估与优化:通过交叉验证、A/B测试等方式评估模型性能,根据评估结果调整模型参数和结构。
-
-
结果存储与应用
-
将预测结果存储到Hive中,便于后续的查询和分析。
-
将预测结果通过可视化界面展示给用户,提供实时的美食推荐和商家经营趋势分析。
-
项目功能
-
用户画像与个性化推荐
-
根据用户的历史行为和偏好,生成详细的用户画像。
-
利用LSTM模型预测用户的未来消费偏好,为用户提供个性化的美食推荐。
-
-
商家经营趋势预测
-
分析商家的评分变化、评论情感倾向等数据,预测商家的未来经营趋势。
-
为商家提供市场趋势分析和经营策略建议。
-
-
实时数据分析与可视化
-
提供实时的数据分析功能,支持用户自定义查询和可视化展示。
-
通过图表、地图等多种方式直观展示分析结果,帮助用户快速理解数据背后的含义。
-
-
系统交互与反馈
-
提供用户交互界面,用户可以根据自己的需求选择不同的分析维度和时间范围。
-
收集用户反馈,根据用户需求不断优化系统功能和用户体验。
-
通过上述数据流程和功能设计,本项目能够高效地处理和分析海量的大众点评数据,为用户提供精准的美食推荐和商家经营趋势预测,具有较高的实用性和创新性。
五、开发技术介绍
后端:Django
大数据处理框架:Spark /Hadoop
数据存储:MySQL /Hive
编程语言:Python
回归算法:LSTM回归预测算法
数据可视化:Echarts
数据采集:Selenium爬虫
六、项目展示
登录注册 
首页 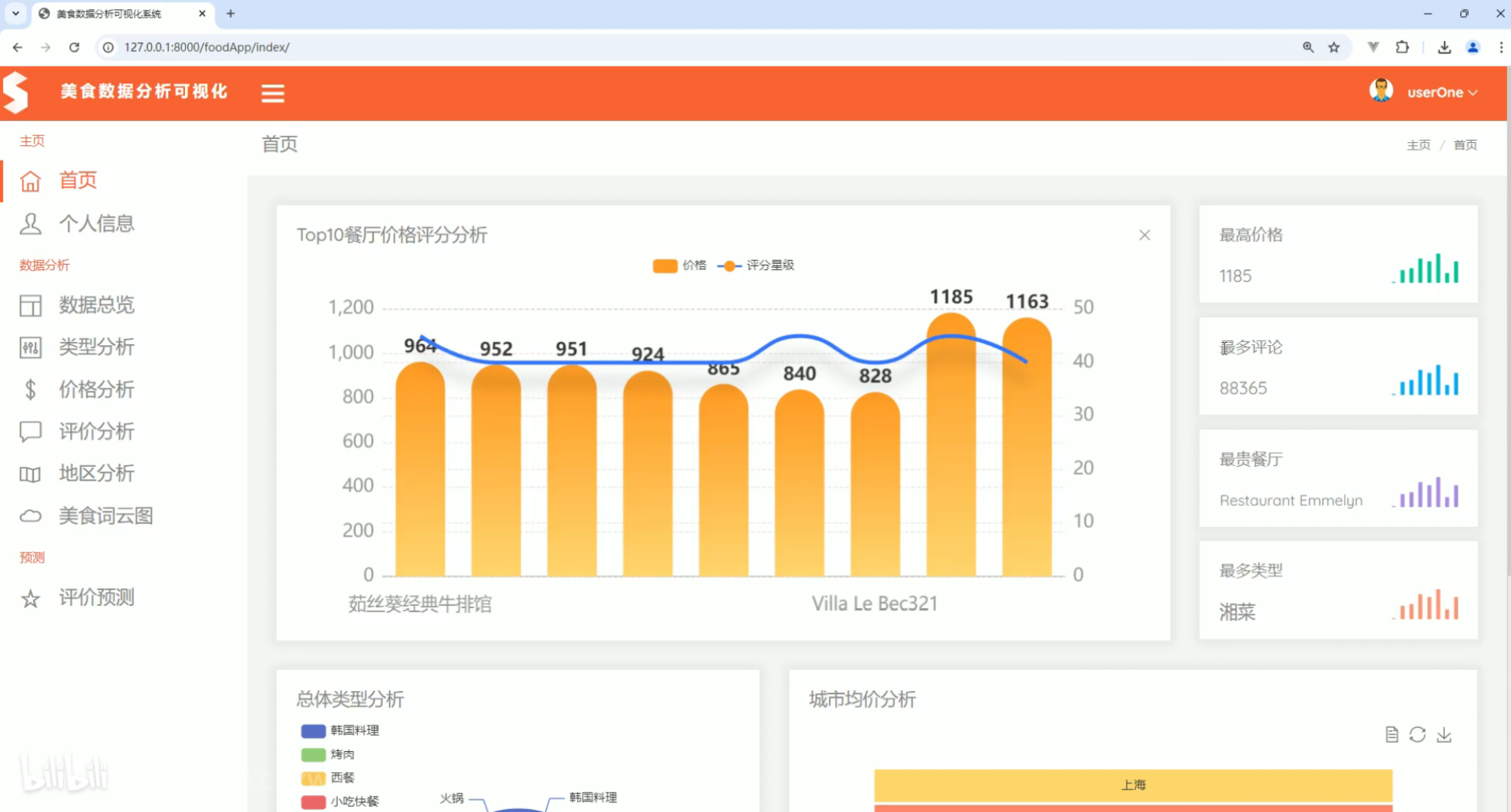
 个人信息修改
个人信息修改
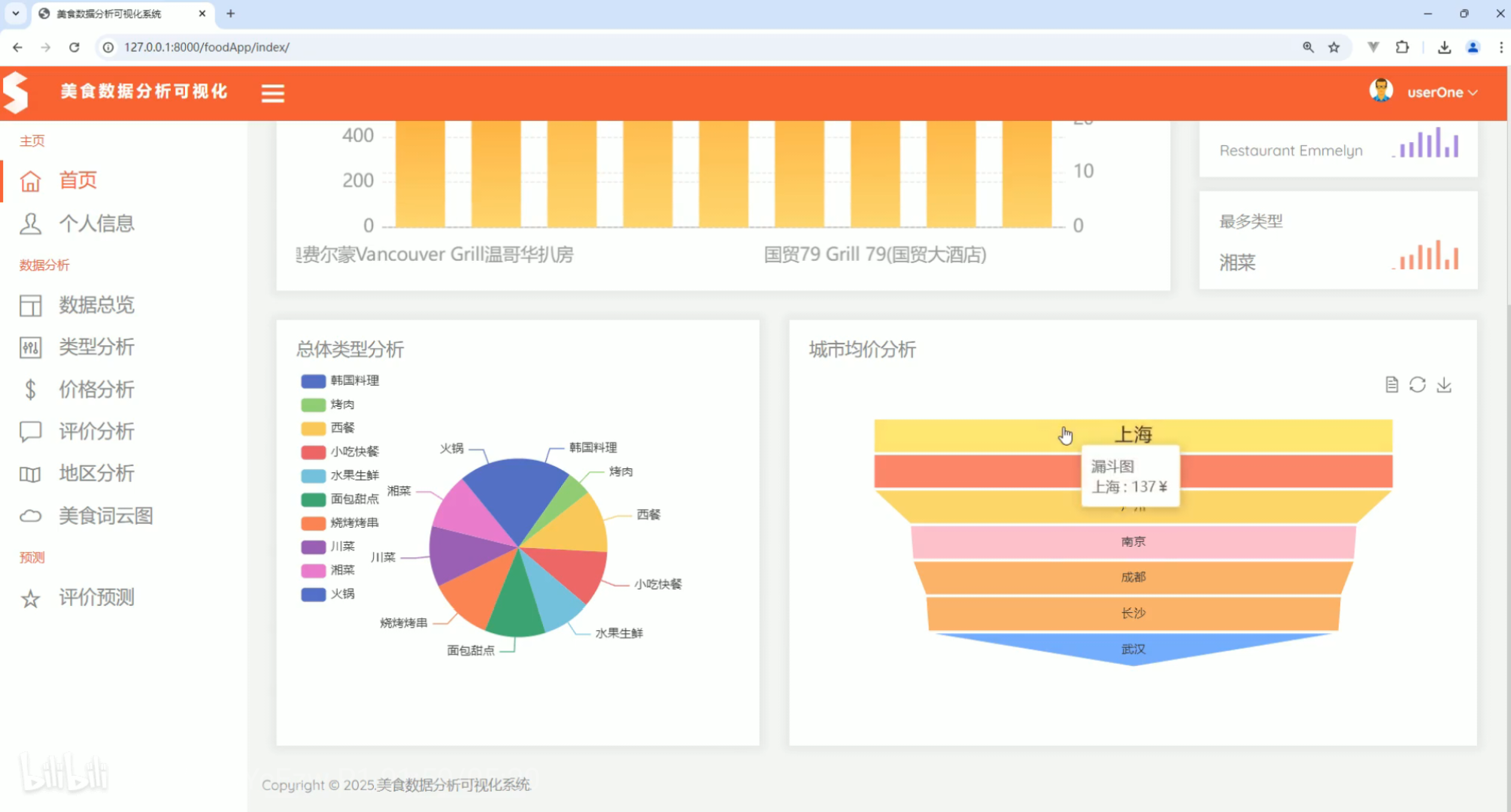
数据总览 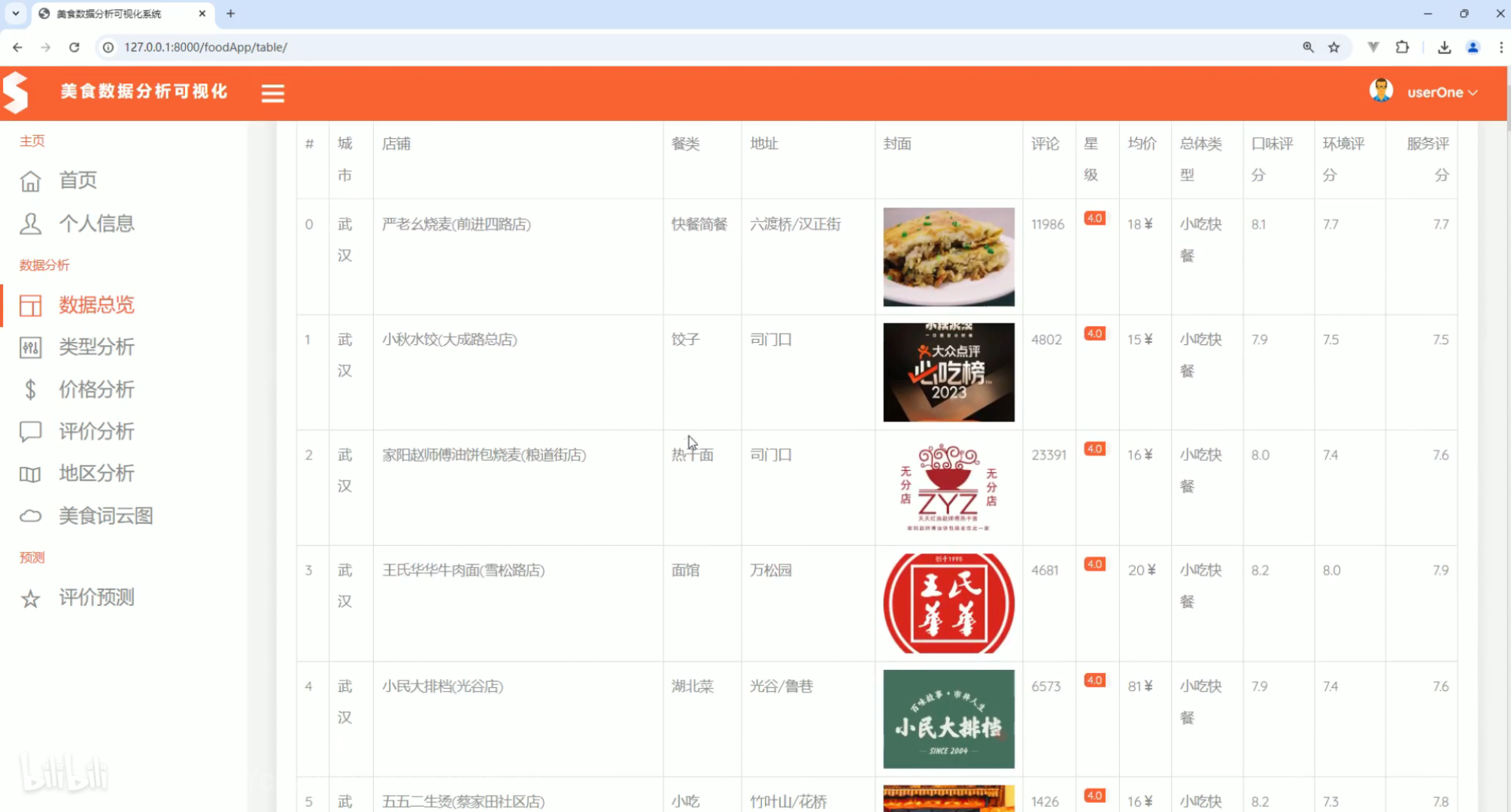 类型分析
类型分析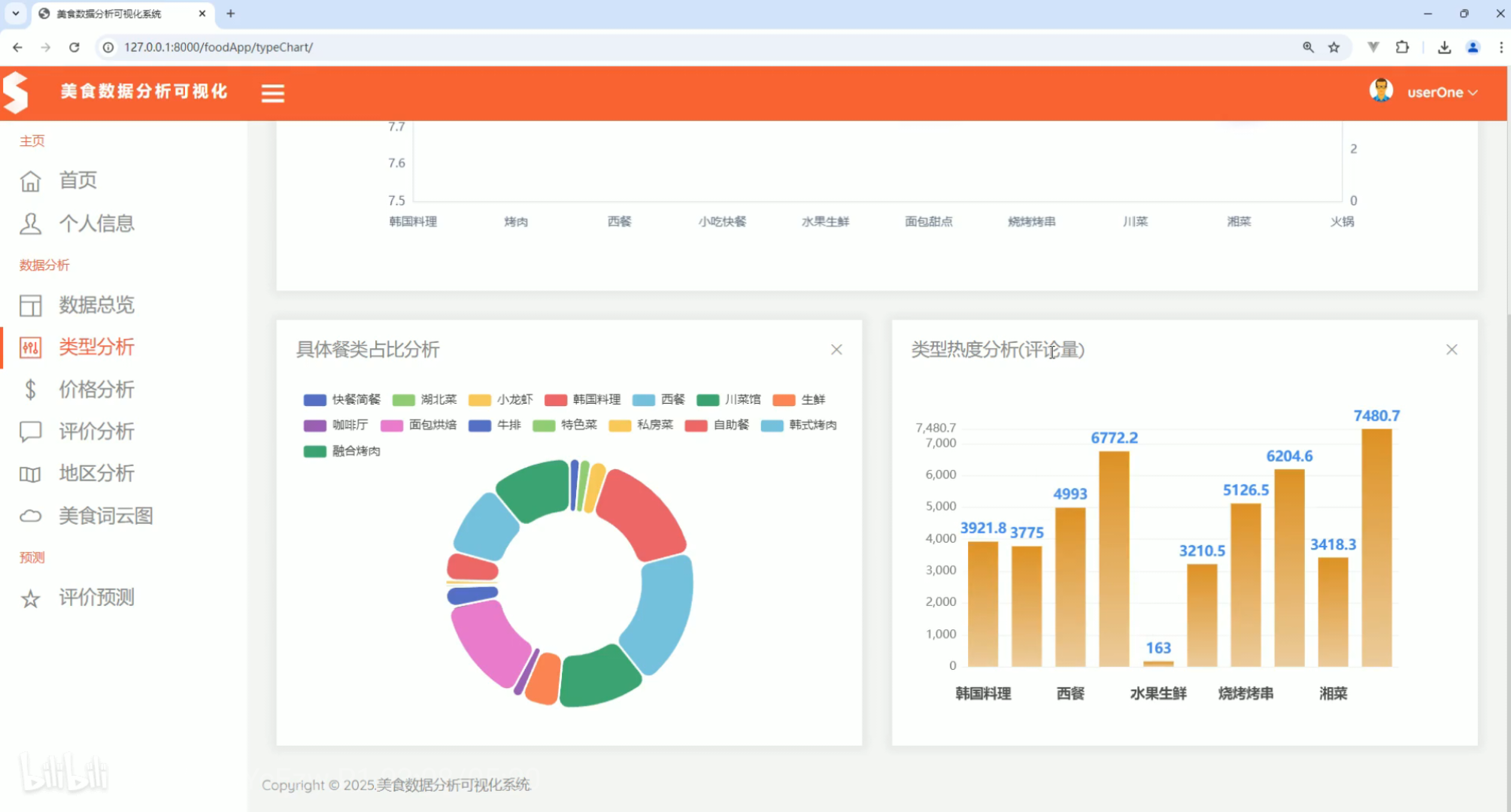 价格分析
价格分析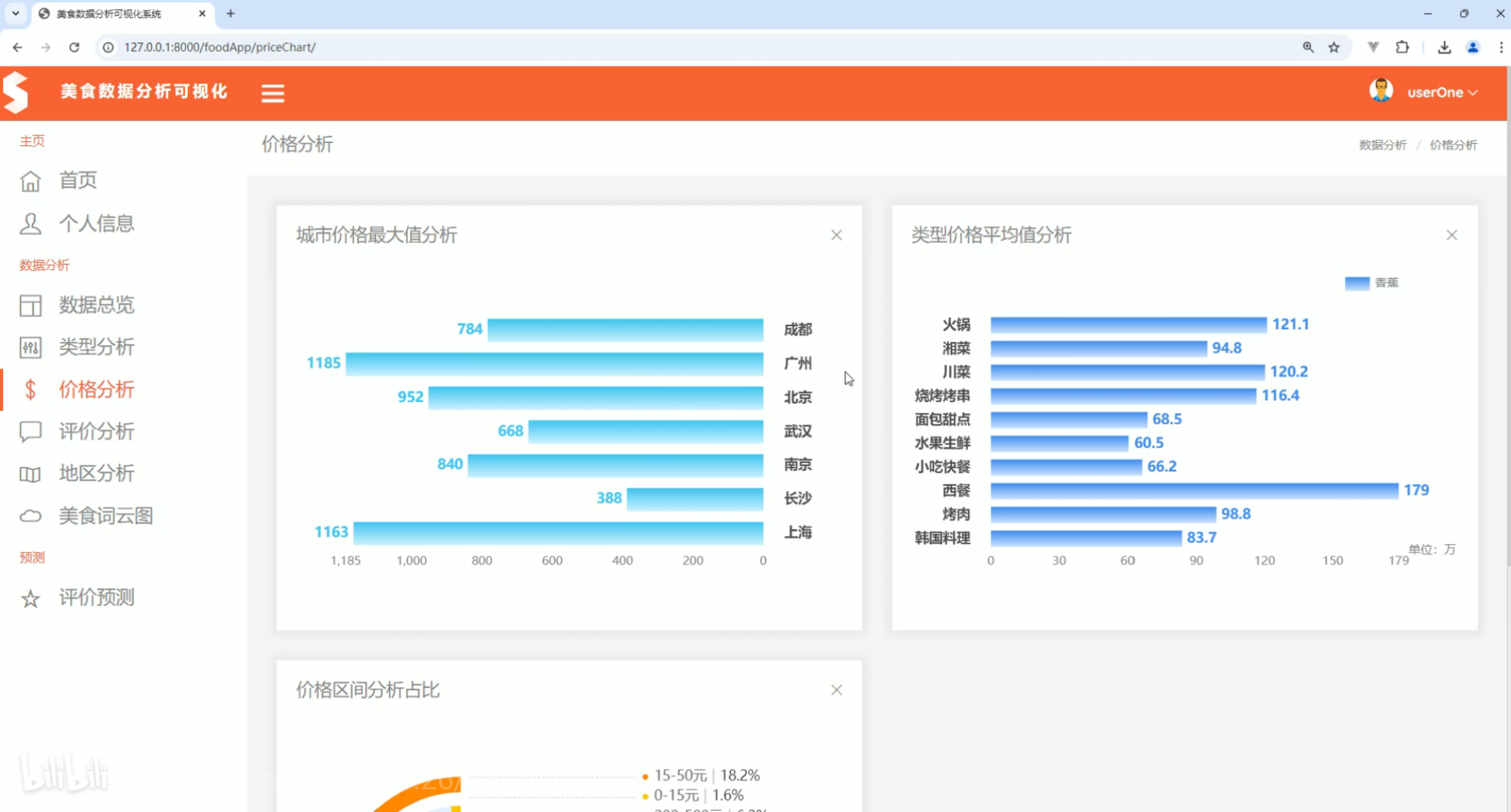 评价分析
评价分析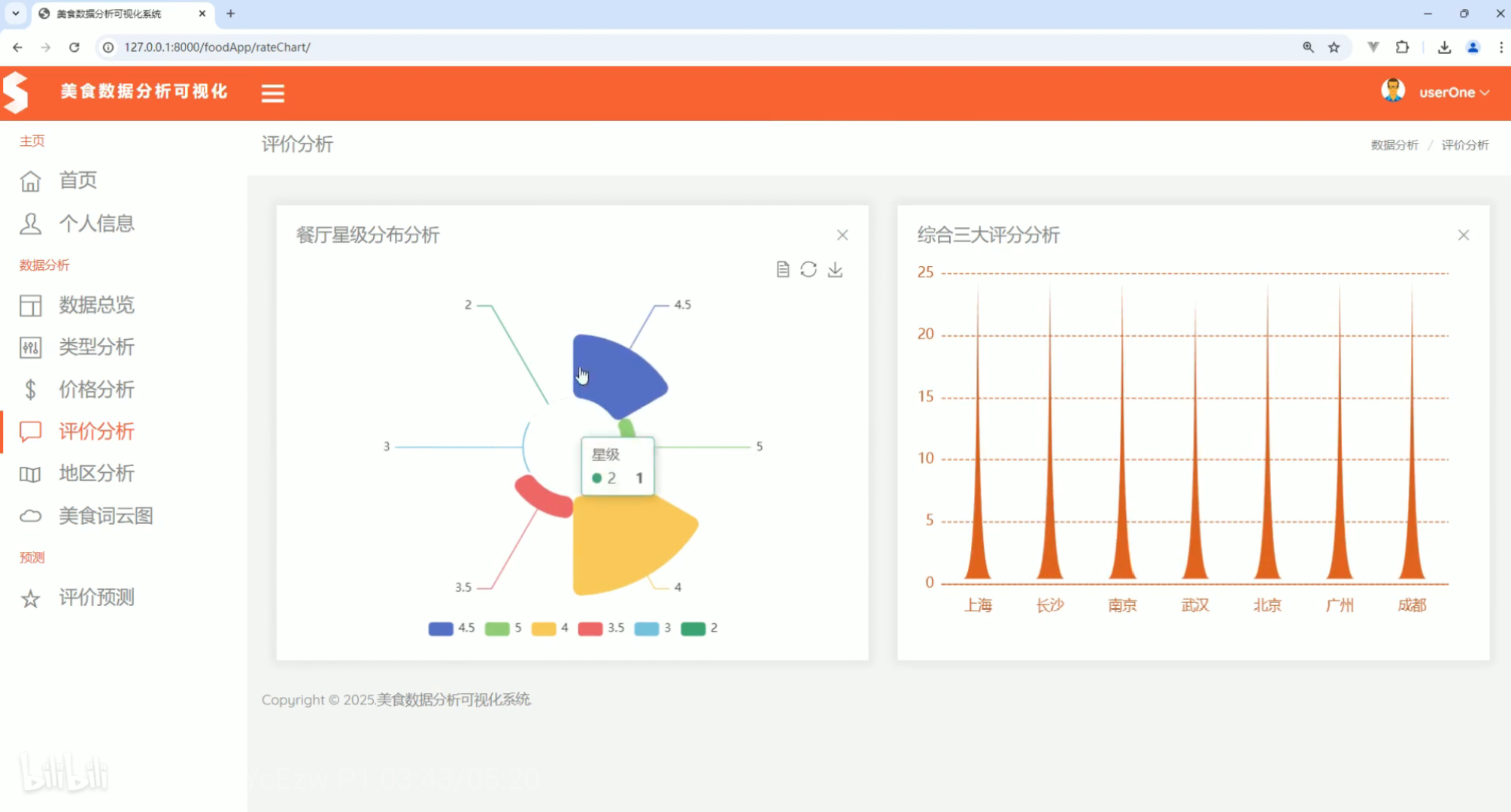 地区分析
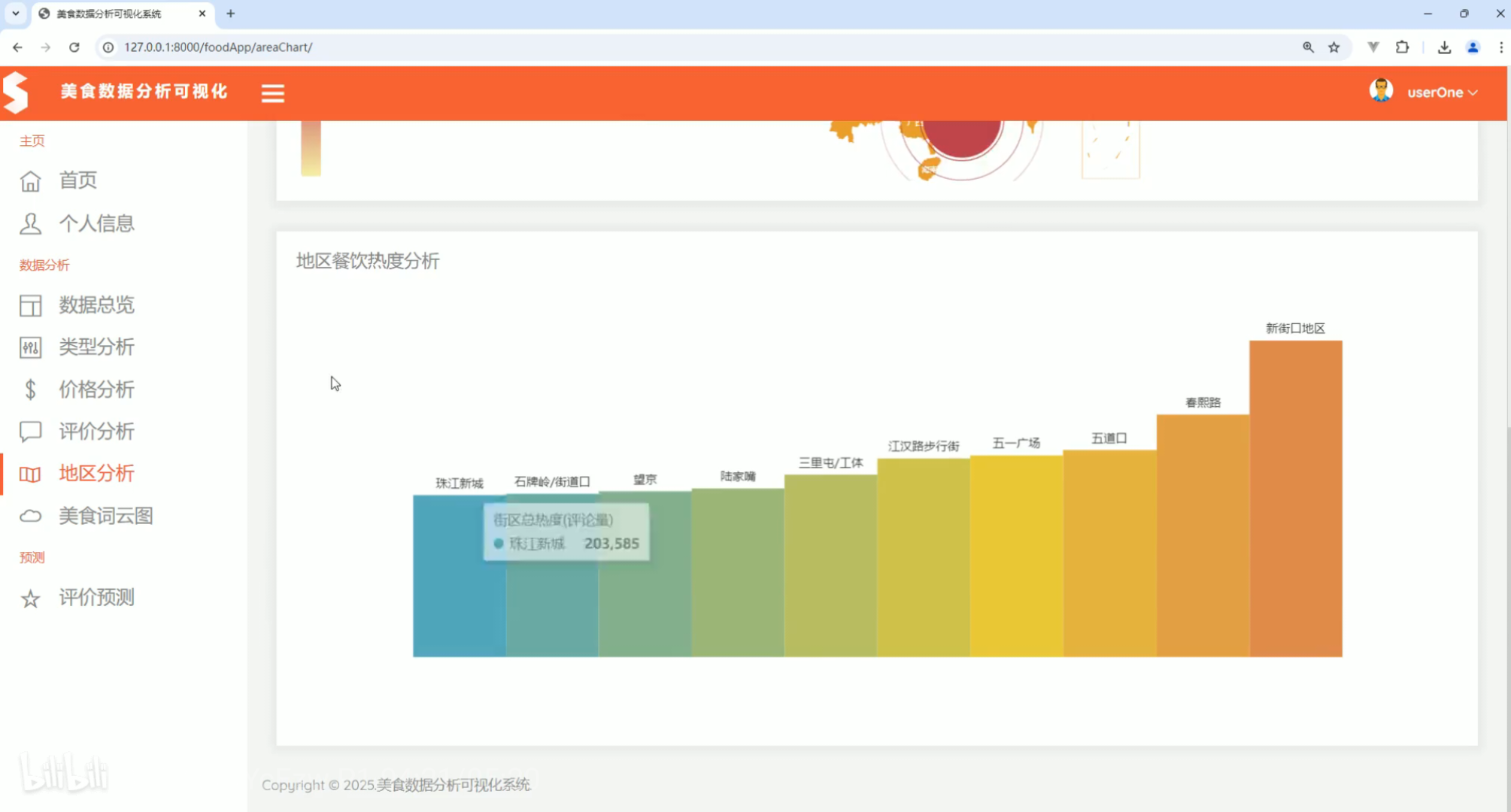
地区分析
 美食词云图
美食词云图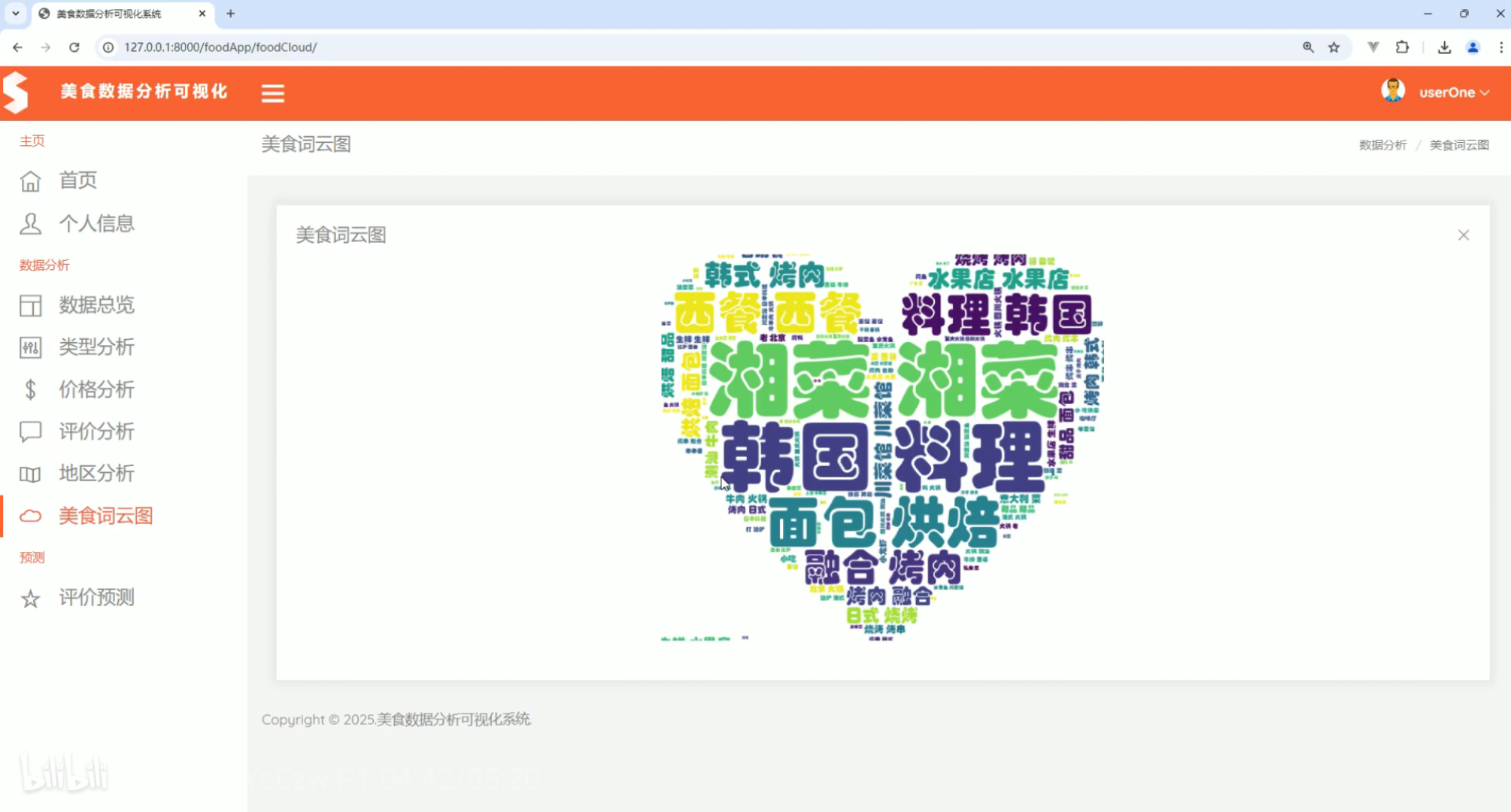 评价预测
评价预测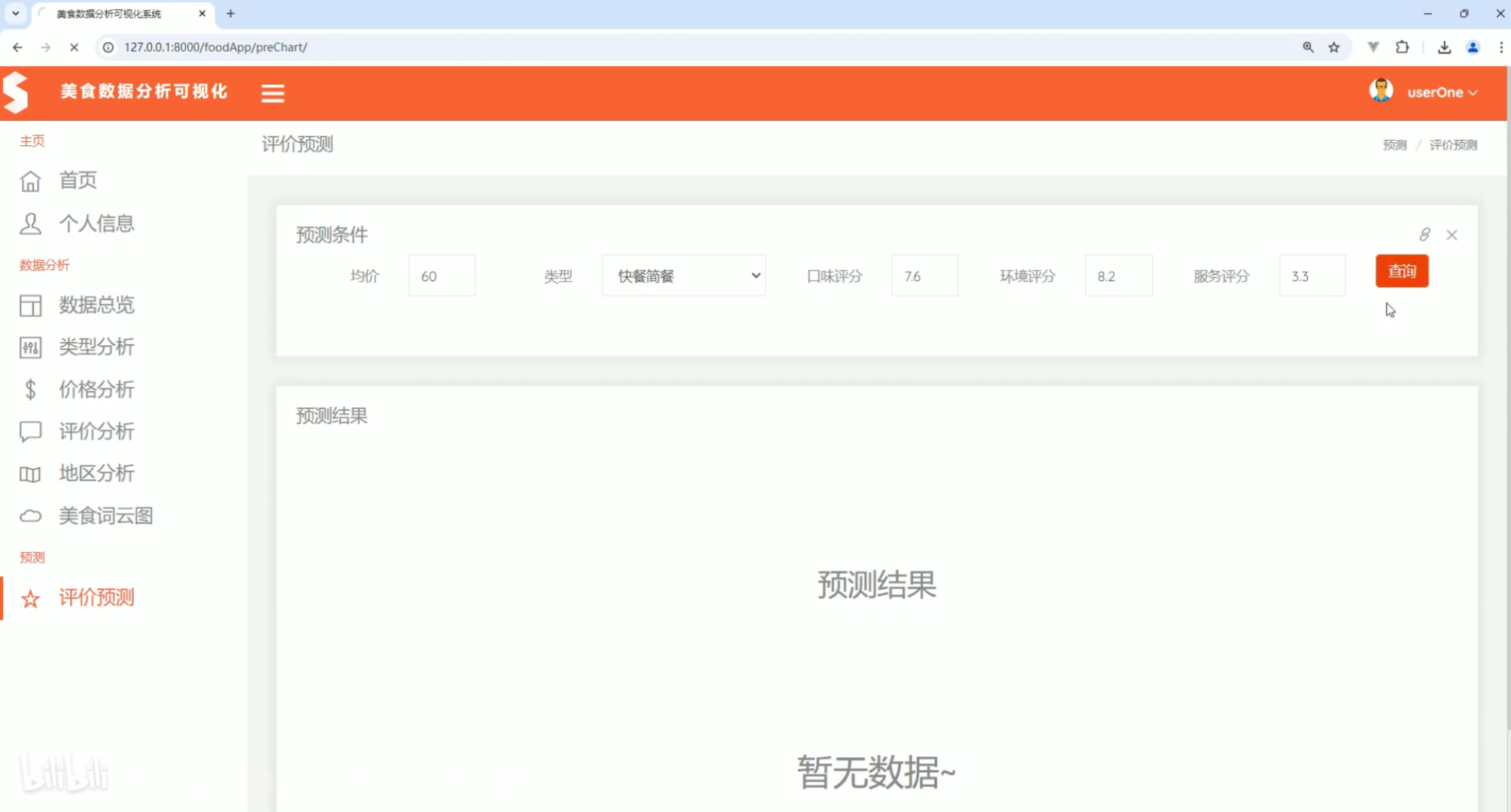
七、权威教学视频
【Spark+LSTM】美食大众点评数据分析预测系统 餐厅 hadoop Hive 大数据毕设 大众点评数据 计算机毕业设计—免费完整实战教学视频
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。

















 1876
1876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









