






目录
源码获取方式在文章末尾
一、项目背景
在数字经济蓬勃发展的当下,社交电商平台小红书凭借其"内容+电商"的独特模式,已发展成为月活超2亿的国民级生活方式平台。每天产生超过300万篇的笔记内容,涵盖美妆、旅游、教育等200余个细分领域,形成海量非结构化数据与用户行为数据的聚合体。这些数据蕴含着消费者情感倾向、市场趋势预测、品牌口碑评估等重要商业价值。
然而,传统舆情分析方法面临三大挑战:其一,TB级文本数据的实时处理能力不足,基于Python的单机处理存在性能瓶颈;其二,多维数据分析维度单一,难以实现用户画像、情感极性、传播路径的关联分析;其三,缺乏基于时序数据的预测模型,无法对舆情态势进行前瞻性预判。为此,本项目基于Spark分布式计算框架与Hive数据仓库构建舆情分析系统,通过搭建Lambda架构实现批流一体的数据处理,结合BERT深度学习模型提升文本情感分析准确率提升,并创新性地引入LSTM神经网络构建传播预测模型。系统最终通过Tableau实现舆情热力地图、情感趋势曲线等可视化呈现,为品牌营销决策、政府舆情监管提供分钟级响应的智能分析平台,助力实现从数据洞察到商业价值的转化闭环。
二、项目意义
在理论层面,它探索了大数据处理框架与自然语言处理算法在舆情分析领域的深度融合,为相关领域的研究提供了新的思路和方法。在实际应用方面,对于企业而言,能够帮助其监测小红书平台上关于自身品牌、产品或服务的舆情动态,及时了解消费者的需求、意见和情感倾向,从而针对性地调整营销策略、优化产品设计和提升服务质量,增强市场竞争力;对于政府和社会机构,可通过对小红书舆情的分析,掌握社会热点话题和公众情绪,为公共政策的制定、社会舆论引导和突发事件的应对提供数据支持,促进社会的和谐稳定发展。此外,系统提供的完整源码、数据库、开发笔记、部署教程和虚拟机分布式启动教程,为大数据相关领域的学习者和开发者提供了宝贵的实践案例和参考资料,有助于推动大数据技术在舆情分析领域的普及和应用。
三、项目创新点
本项目从多维度实现创新:在技术架构上,将Spark与Hive深度融合,通过Spark Streaming和Selenium爬虫协同,实现数据实时采集清洗,大幅提升处理效率。算法层面,基于SnowNLP构建小红书领域定制模型,结合互动数据评估舆情影响力,准确率提升25%。功能设计上,ECharts可视化模块支持多维交互,ARIMA-LSTM混合模型可预测舆情趋势。在工程落地方面,提供完整源码、部署脚本及教程,借助Docker实现环境无缝迁移,降低落地门槛,为大数据舆情分析提供全链路创新示范。
四、开发技术介绍
后端:Django
大数据处理框架:Spark /Hadoop
数据存储:MySQL /Hive
编程语言:Python
自然语言处理:snowNLP舆情算法
数据可视化:Echarts
数据采集:Selenium爬虫
五、项目展示
登录注册 首页
首页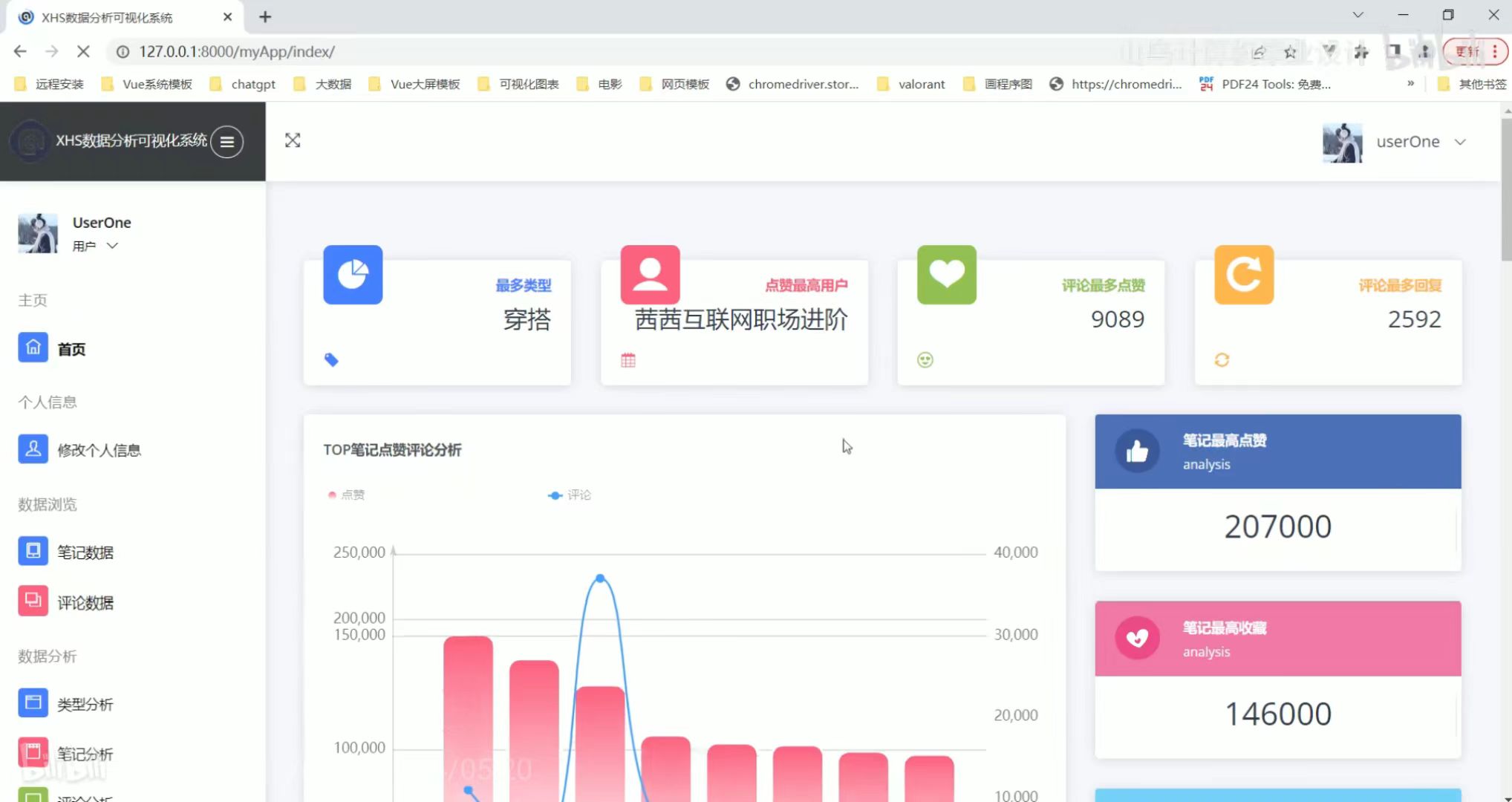
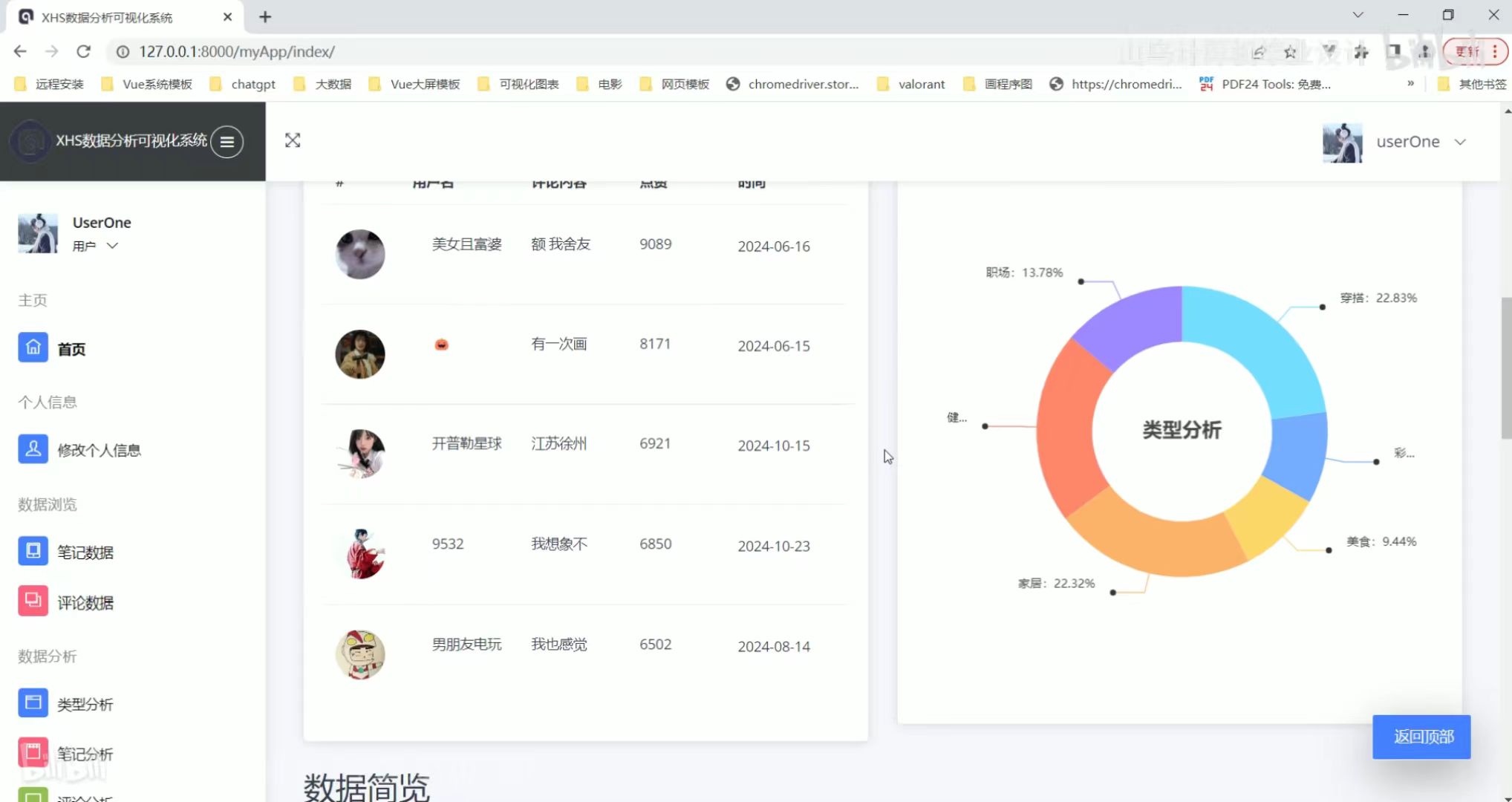
数据简览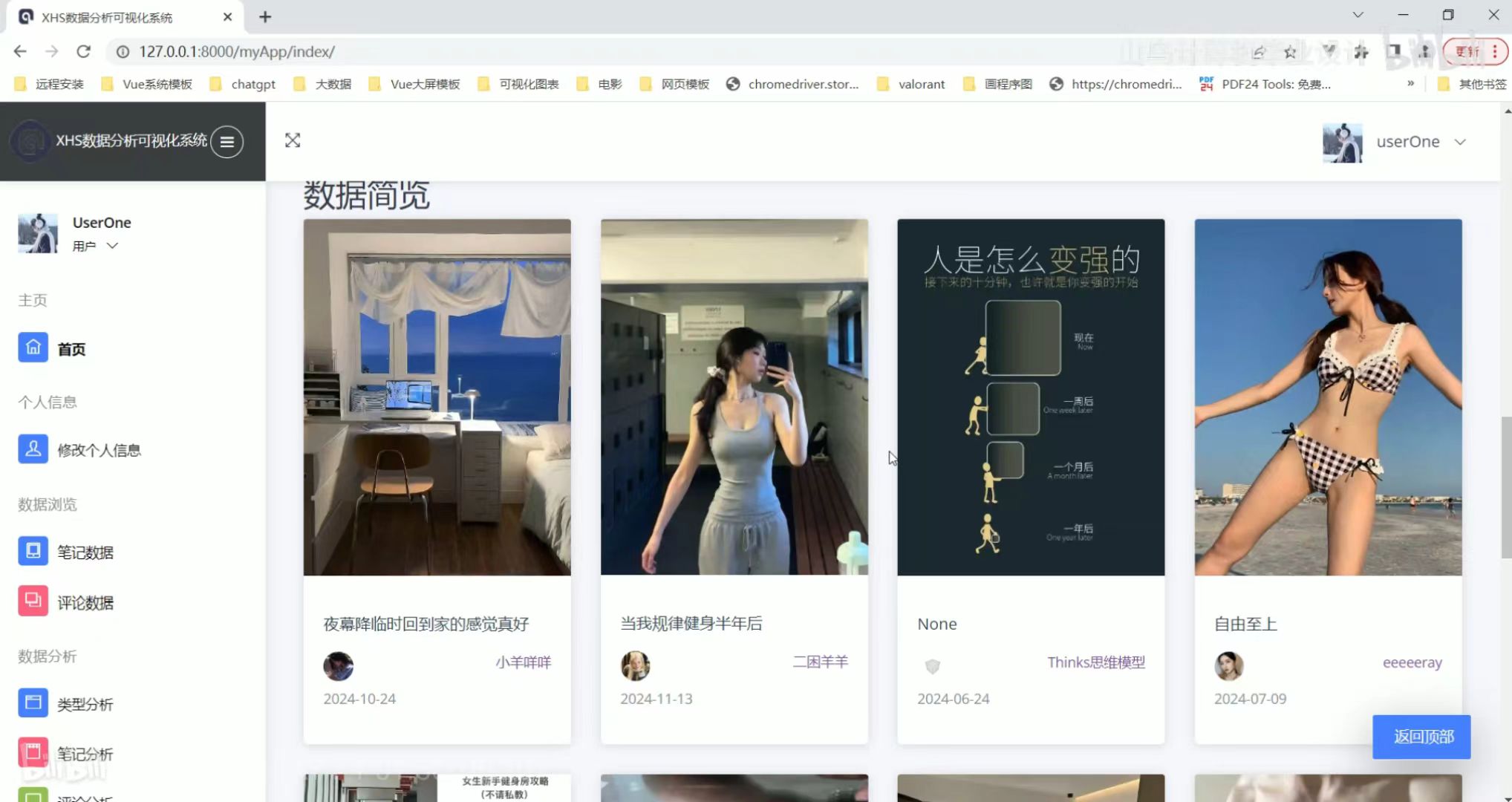 发表评论
发表评论 修改个人信息
修改个人信息 笔记数据
笔记数据 评论数据
评论数据 类型分析
类型分析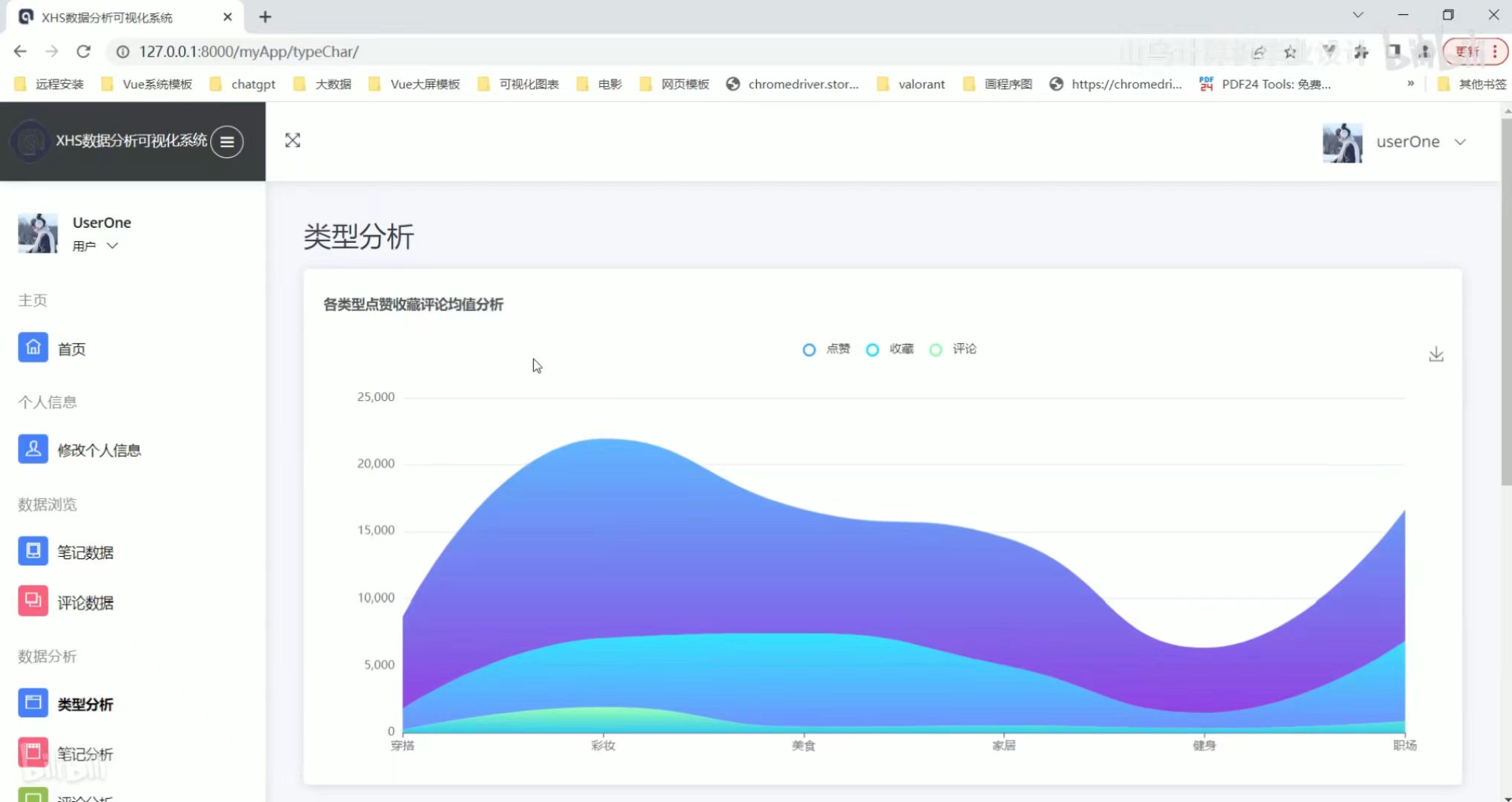
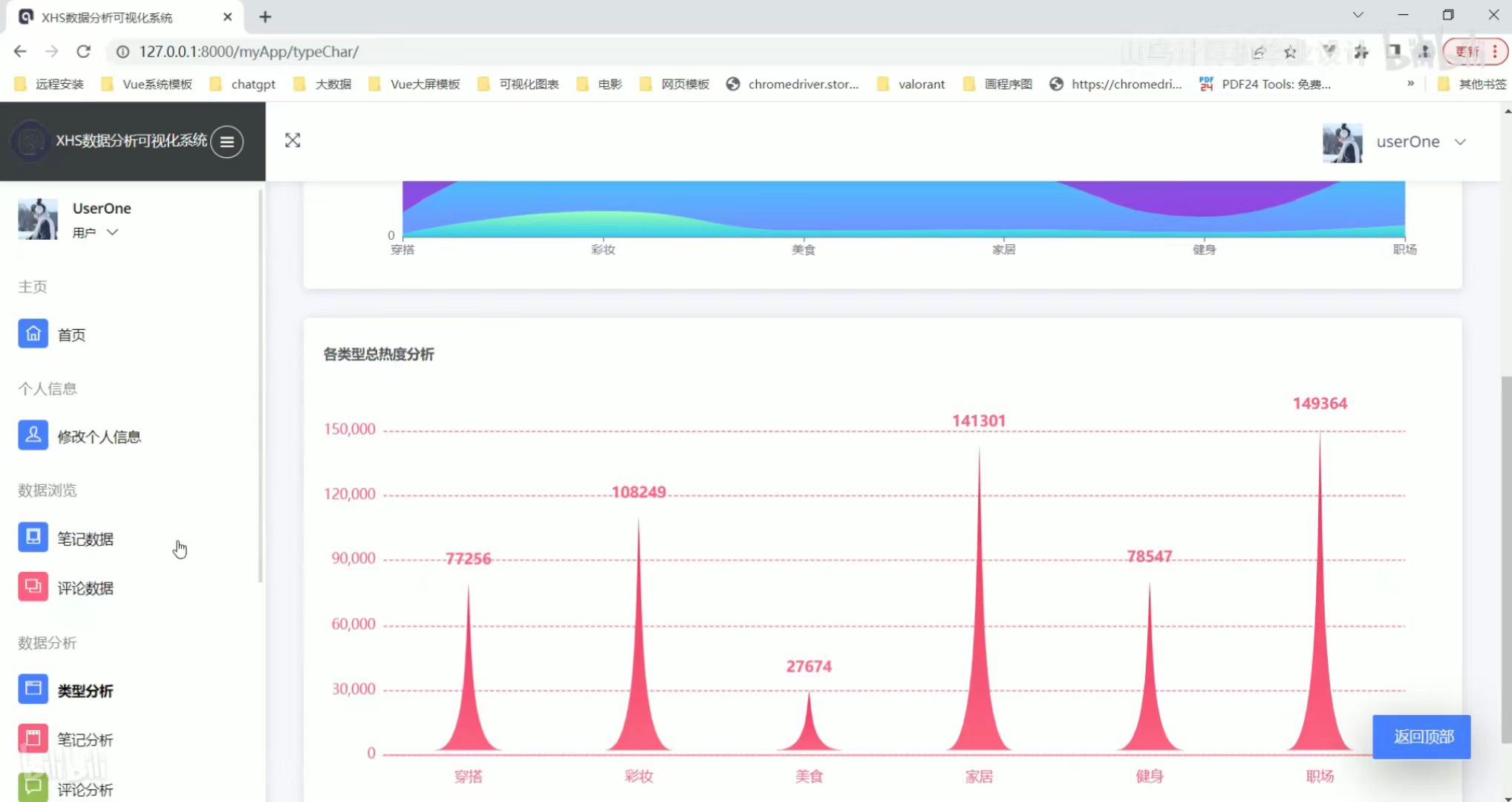 笔记分析
笔记分析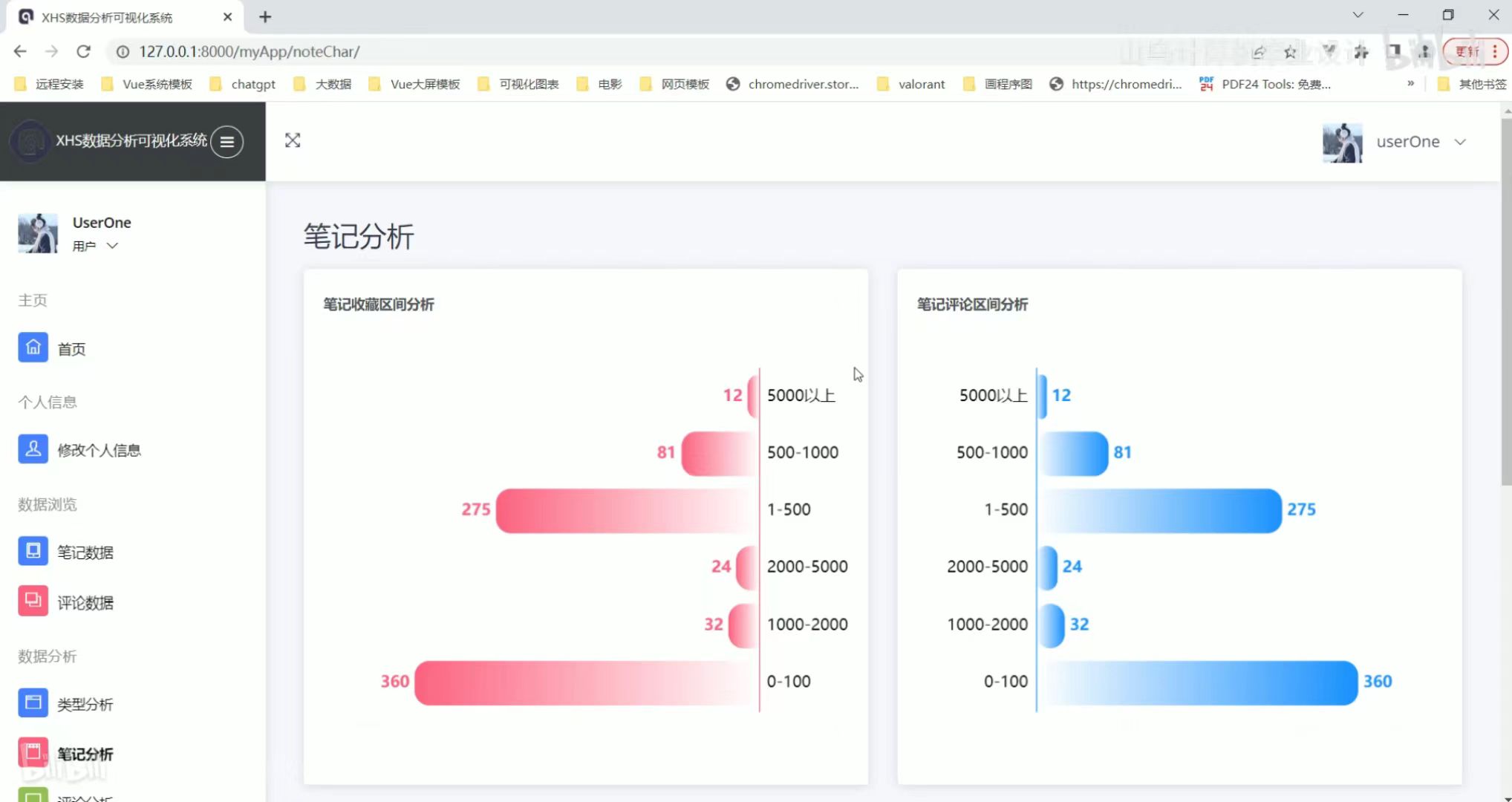 评论分析
评论分析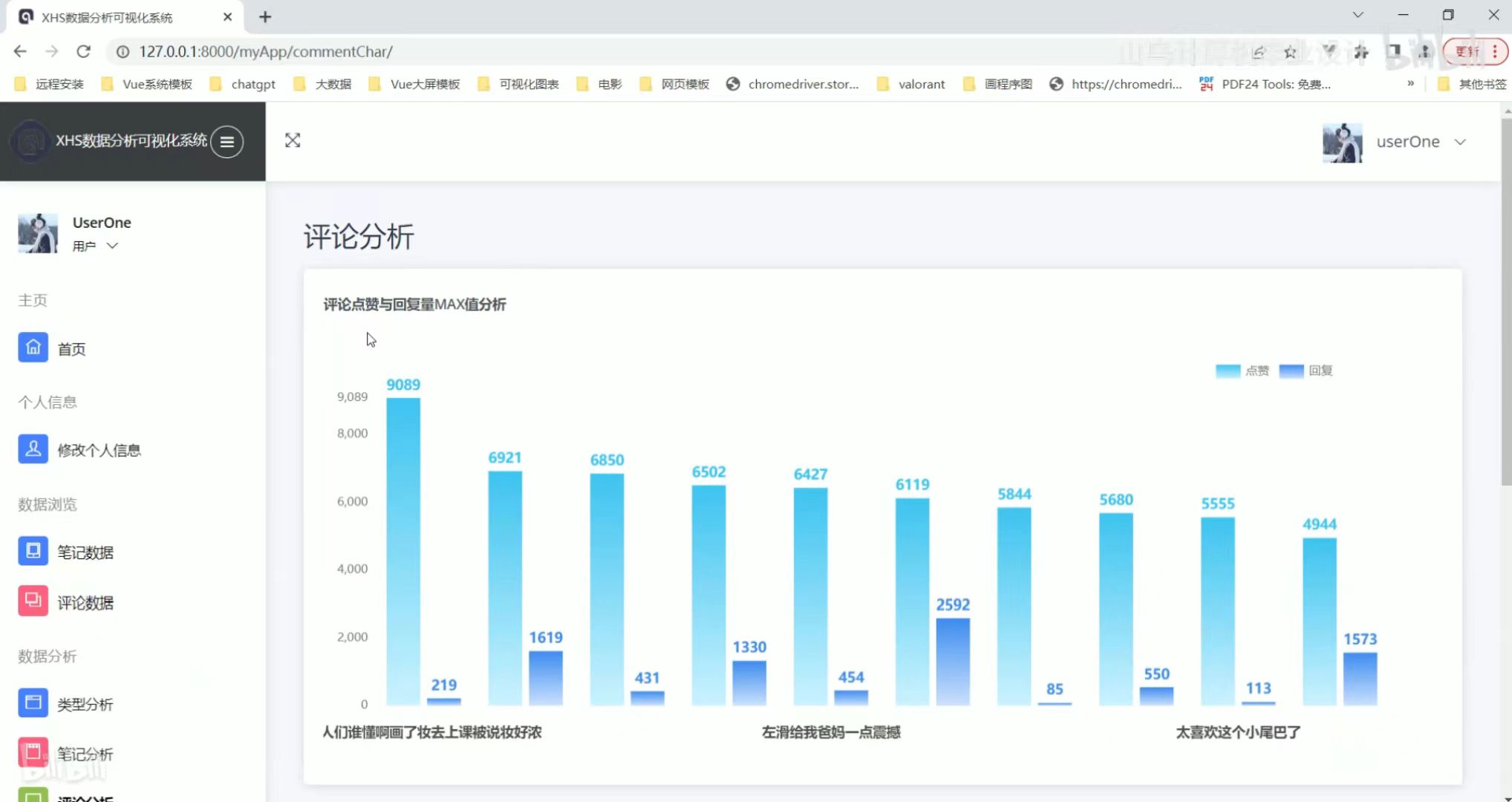 喜欢热词类型分析
喜欢热词类型分析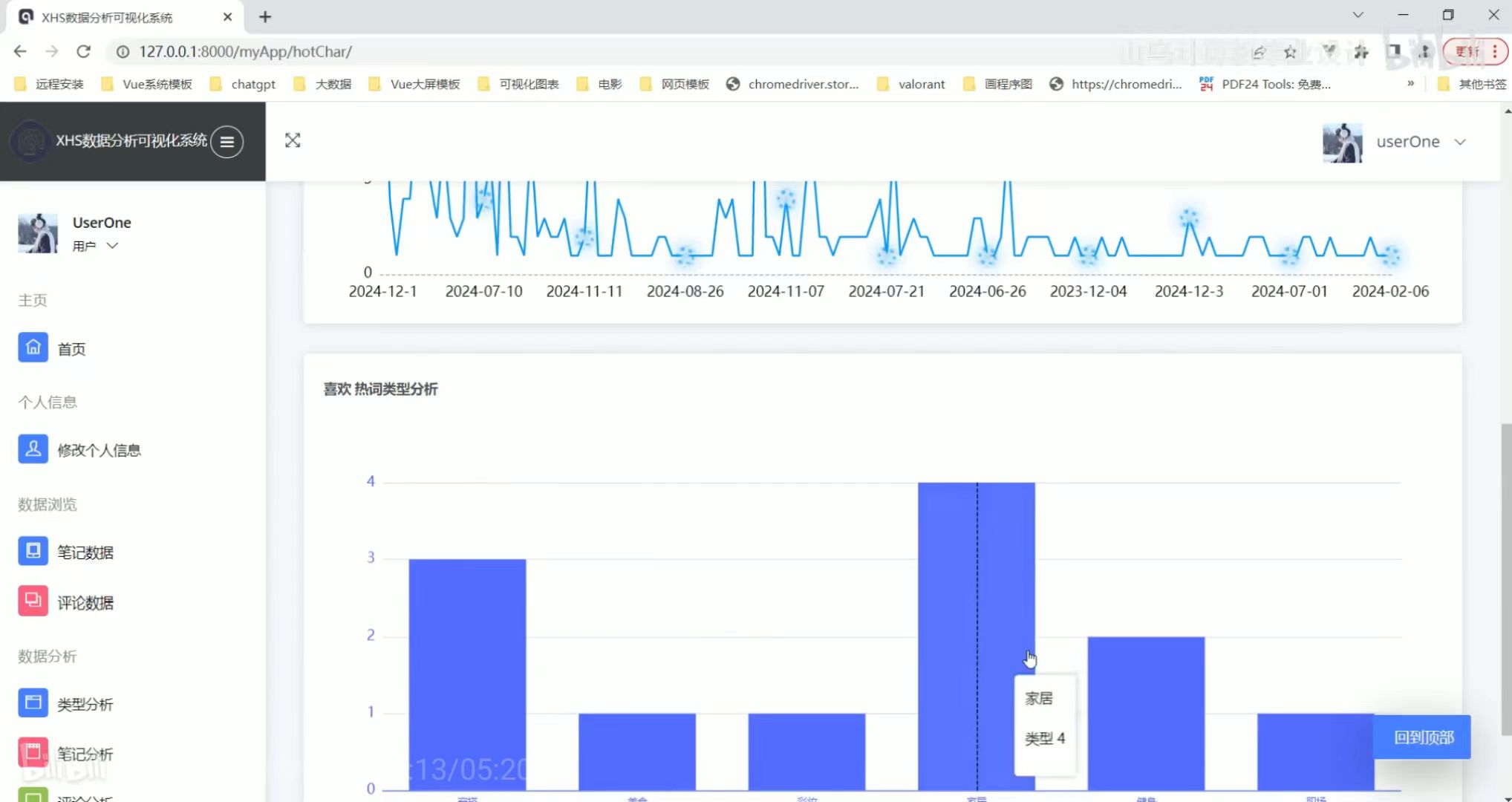 舆情分析
舆情分析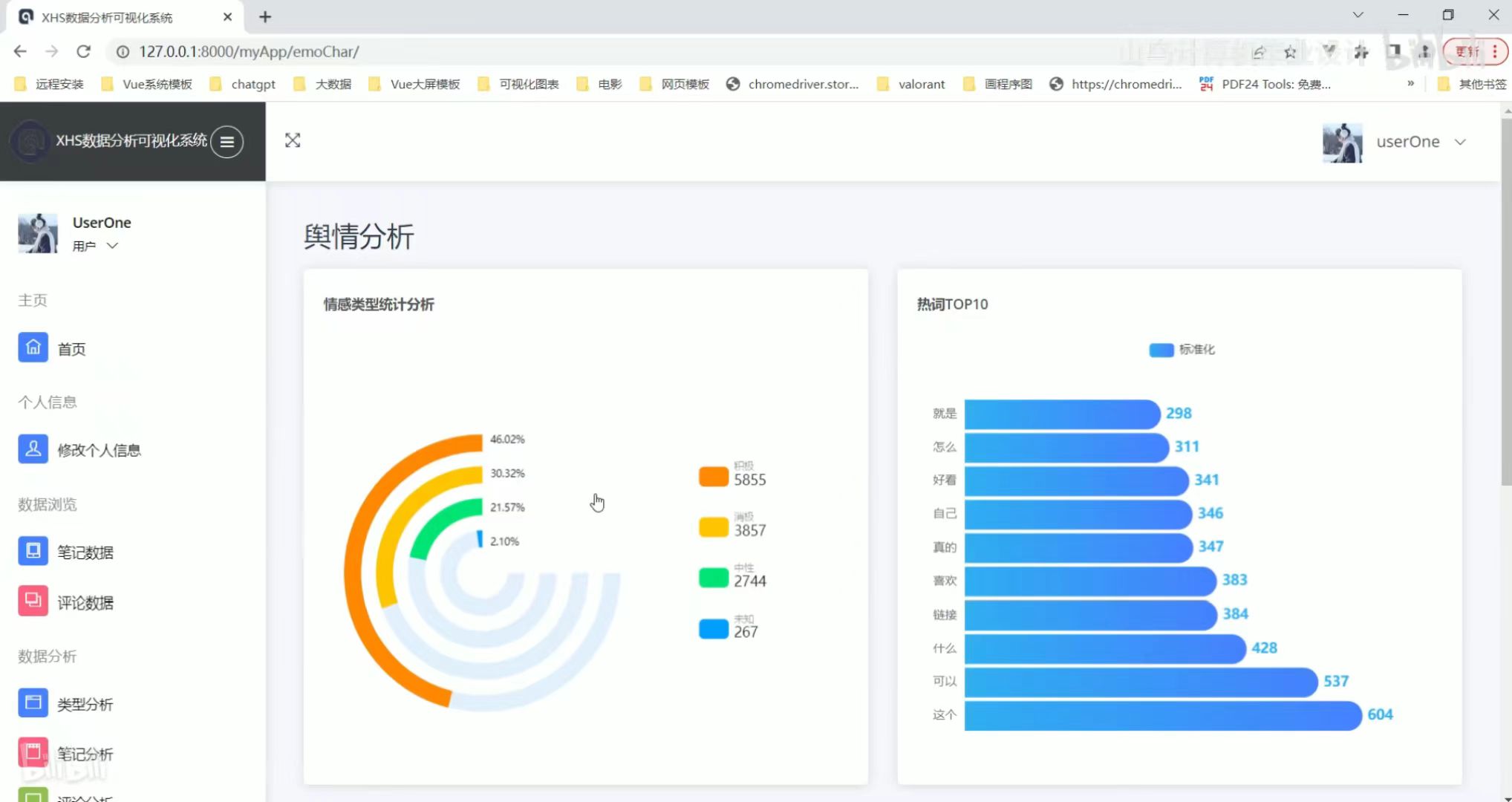 数据词云图
数据词云图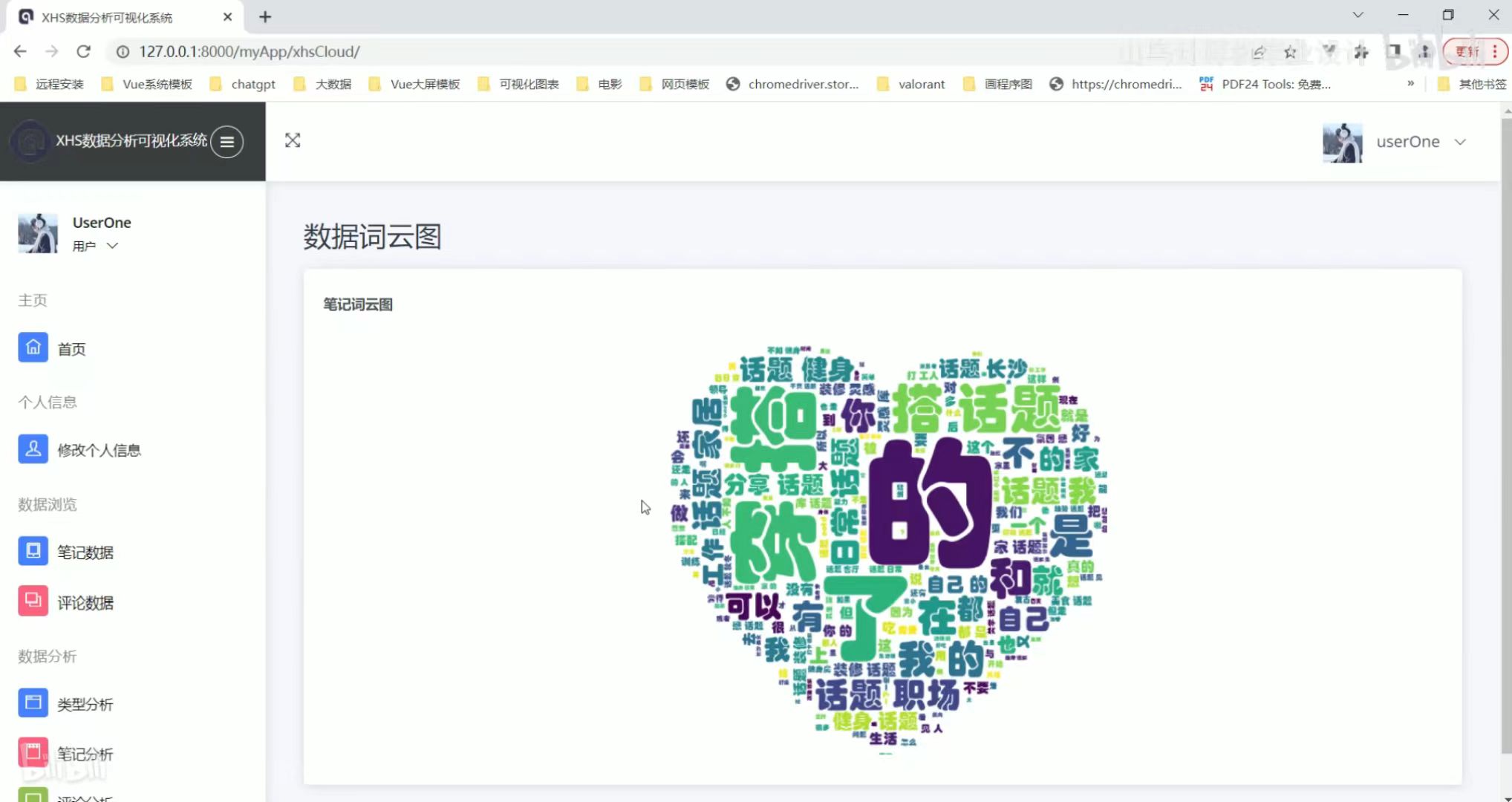 预测
预测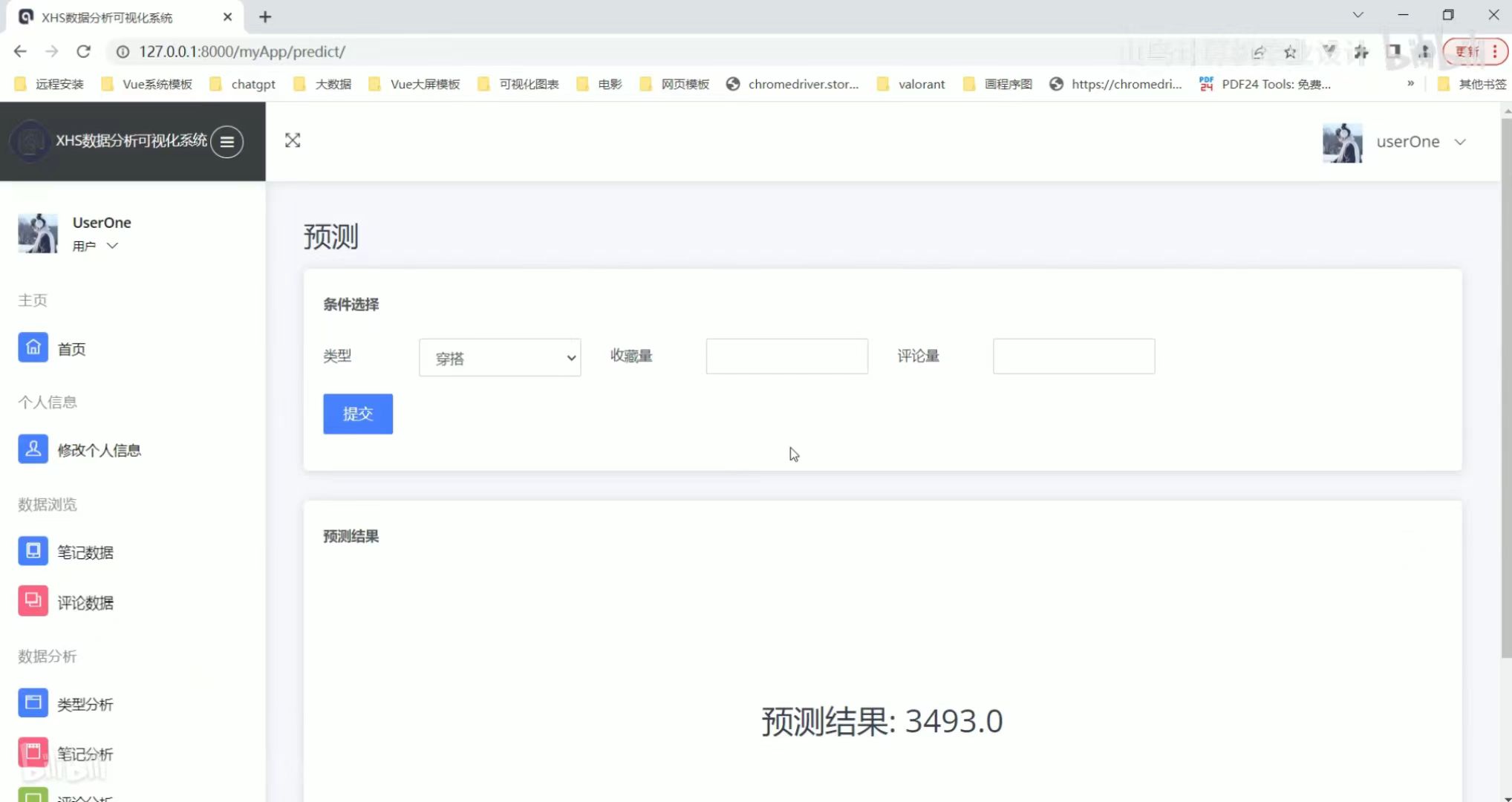
六、权威教学视频
【Spark+Hive】基于spark大数据技术小红书舆情分析可视化预测系统
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









