






GPT-Sovits模型介绍:
GPT-Sovits是一款先进的开源语音合成模型,具备强大的音色克隆能力,仅需少量语音数据即可精准模拟目标音色。它支持多语言合成,提供便捷的WebUI工具,确保本地运行保护隐私,为语音合成任务提供高效、灵活的解决方案。

一、注册账号与准备工作
平台注册
- 访问星海智算GPU云平台
- 点击注册可填写邀请码 21735375(注册双方均可获赠额外算力资源)。
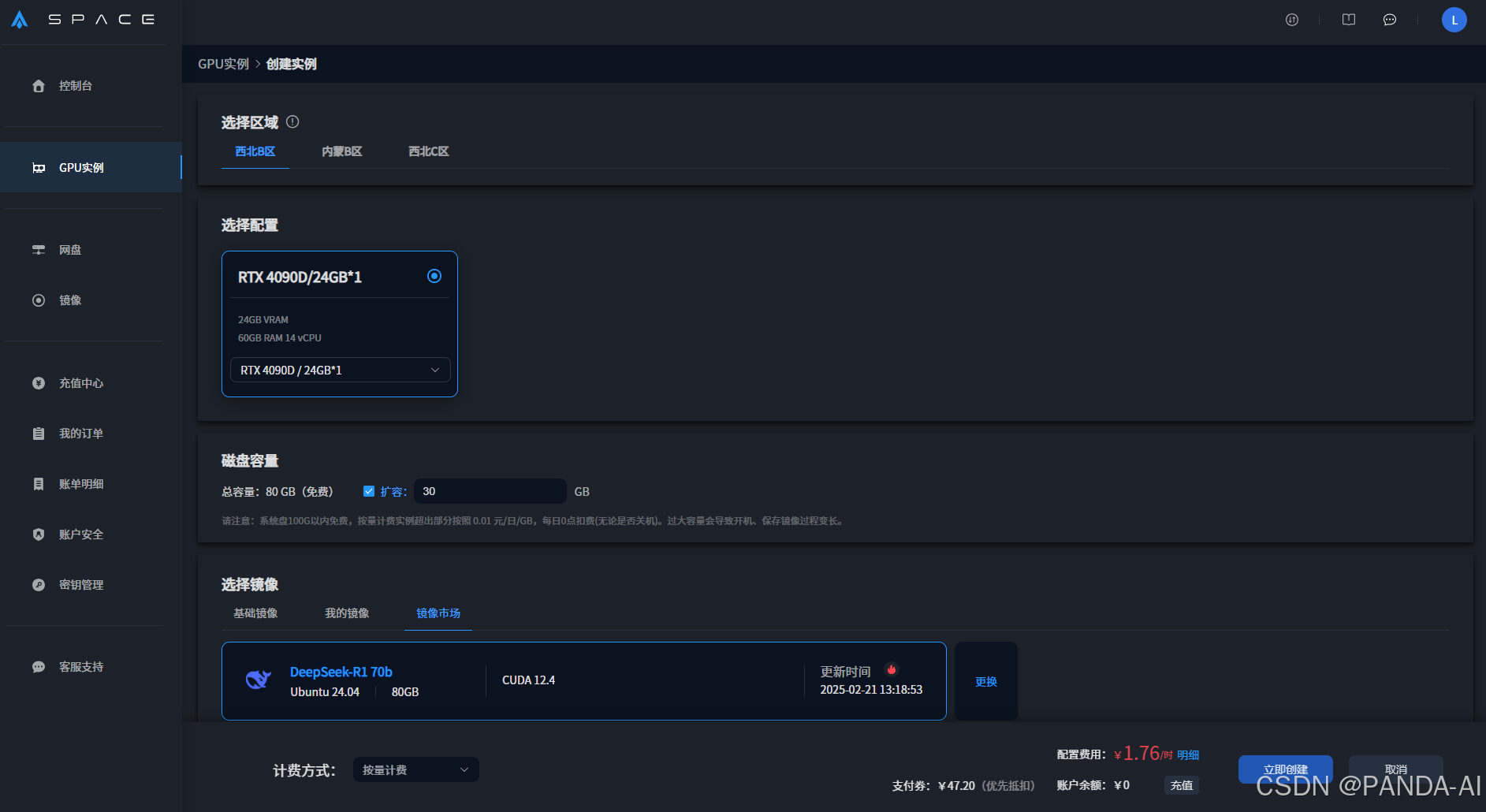
二、GPU实例创建与镜像配置
1. 创建实例:登录控制台后,依次点击【GPU实例】→【创建实例】。
2. 硬件选择建议:
-
显卡类型:推荐NVIDIA RTX 3090/4090(性价比与算力均衡)
-
存储配置:默认50GB系统盘(需扩展可后续挂载云盘)。
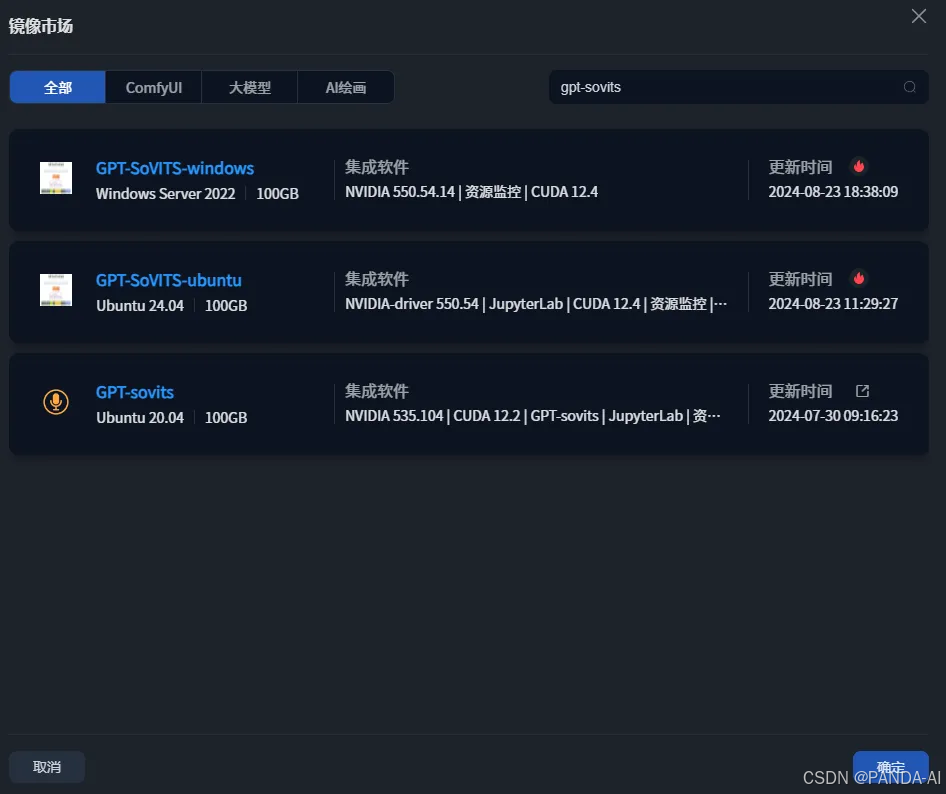
3. 镜像配置关键步骤:
-
点击【镜像市场】→ 搜索关键词
gpt-sovits→ 选择官方镜像 GPT-SoVITS-windows(已预装依赖环境)。 -
确认配置后点击【立即创建】,等待实例初始化完成。
三、远程桌面连接与本地资源挂载
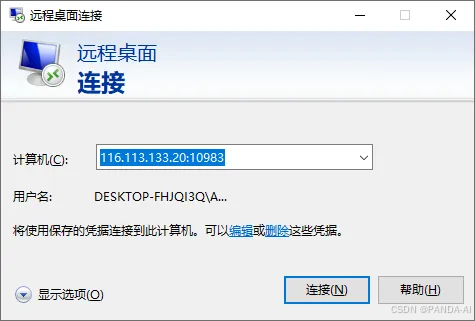
-
远程访问实例
- 连接前准备:确保实例状态为【运行中】。

- 操作流程:
- 本地Windows系统打开【远程桌面连接】(Win键搜索或
mstsc命令启动)。
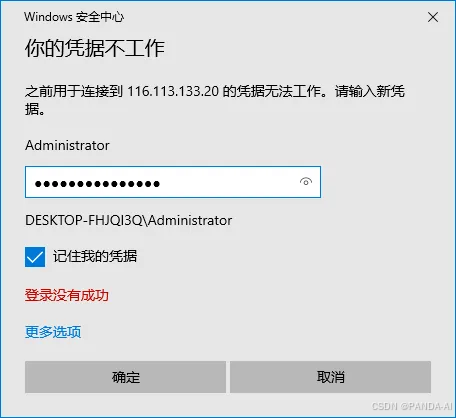
-
输入账号密码
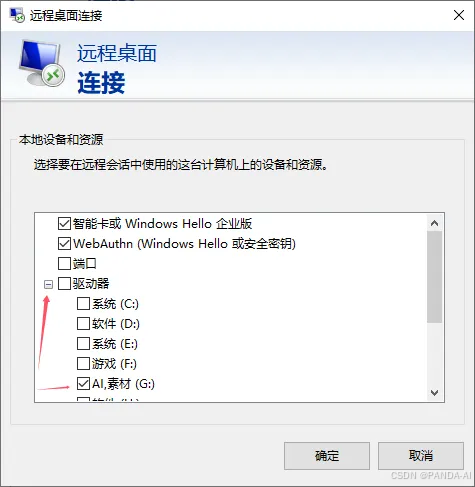
挂载本地存储(必需步骤):
-
点击【显示选项】→【本地资源】→【详细信息】→ 勾选需映射的本地磁盘分区。
-
输入实例密码(从控制台复制第三个密码项)完成认证。
四、GPT-SoVITS环境启动与操作
-
启动语音克隆服务
- 远程桌面内操作:
进入桌面【GPT-SoVITS】项目目录,双击运行 go-webui.bat 启动脚本。
等待WebUI自动加载。
- 文件交互方案:
本地文件上传:通过映射的磁盘分区(如Z:\)直接拖放至实例内。
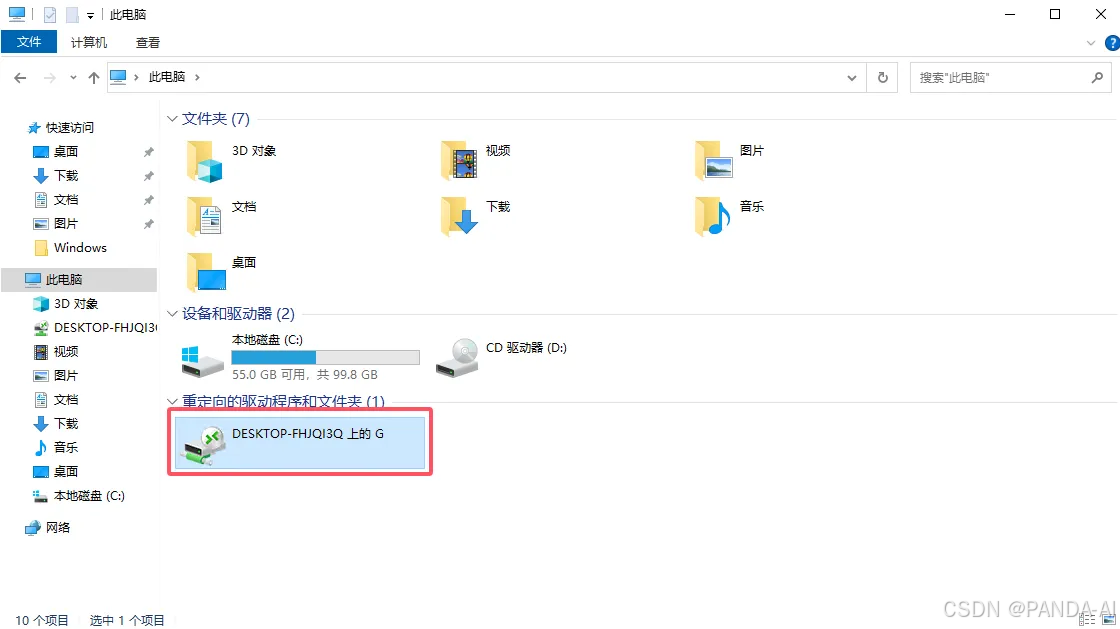
输出文件下载:生成结果保存至映射盘符路径,实时同步至本地。
五、资源管理与优化建议
-
操作规范与成本控制
- 实例生命周期:任务完成后及时【停止实例】以避免持续计费。重要数据需定期备份至本地或云存储。
-
性能调优:
-
大型数据集建议使用平台内置网盘工具传输(如阿里云盘、WebDAV)。
-
若需更高算力,可切换至A100/V100显卡实例(需评估成本)。
-

















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









