







 超级会员免费看
超级会员免费看
引言
在计算机视觉领域,尤其是医学图像分割任务中,UNet架构以其独特的U型结构和跳跃连接机制成为了标杆模型。随着Transformer在自然语言处理领域的巨大成功,自注意力机制也逐渐被引入到计算机视觉任务中。本文将详细解析一种结合了传统卷积操作与自注意力机制的改进版UNet架构,从理论基础到代码实现进行全面剖析。
1. UNet基础架构回顾
1.1 UNet的经典结构
UNet最初由Ronneberger等人于2015年提出,主要用于生物医学图像分割。其核心特点包括:
-
对称的编码器-解码器结构
-
编码器通过下采样逐步提取高层次特征
-
解码器通过上采样逐步恢复空间分辨率
-
跳跃连接将编码器的特征图与解码器对应层级的特征图拼接
这种结构能够同时利用低层次的空间信息和高层次的语义信息,在医学图像分割中表现出色。
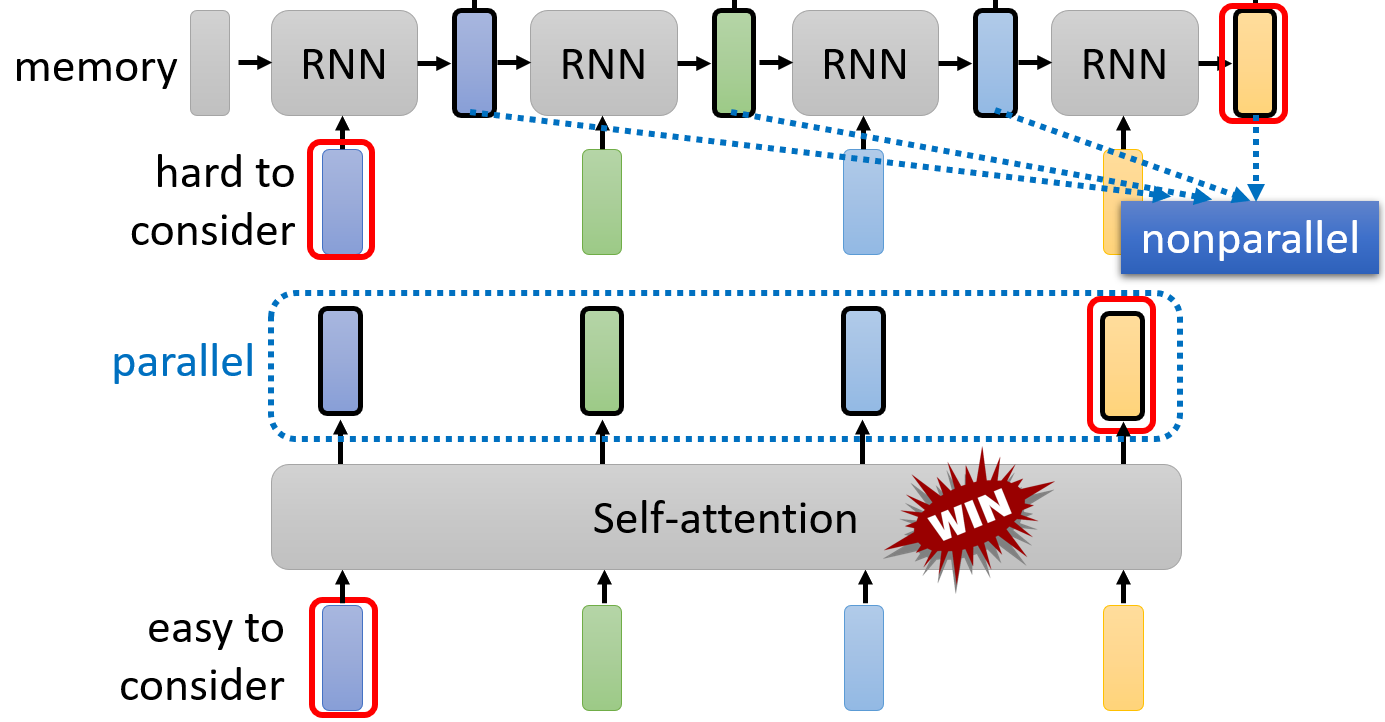
1.2 传统UNet的局限性
尽管UNet表现优异,但仍存在一些不足:
-
卷积操作的局部性限制:传统卷积只能捕捉局部感受野内的信息
-
长距离依赖难以建模:对于图像中相距较远的关联区域,标准卷积难以建立有效联系

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











