







实时语义分割之BiSeNetv2(2020)结构原理解析及建筑物提取实践
深度学习pytorch之简单方法自定义9类卷积即插即用
引言
语义分割希望在处理高分辨率的图片时,能够捕捉到图片中不同部分之间的远距离关系,但是又不能让计算过程变得太复杂或者太费时,因此,提出了针对高质量像素级回归任务的自注意力机制–极化自注意力(PSA)机制。
论文地址:https://arxiv.org/pdf/2107.00782
原始代码:https://github.com/DeLightCMU/PSA
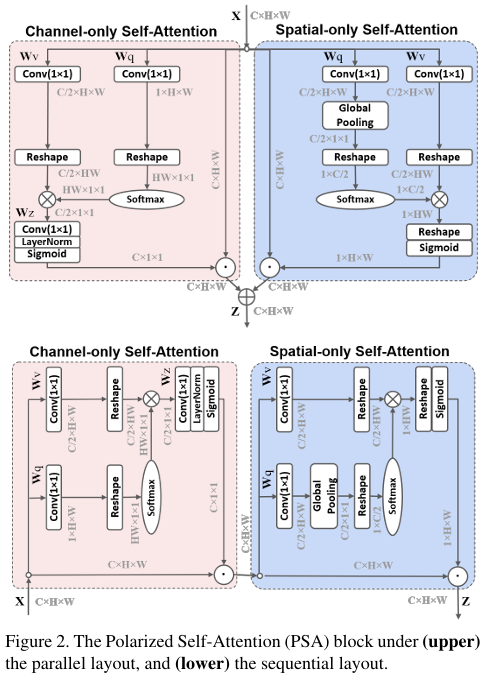
原理和结构
基础思想:在摄影时,所有横向的光都会进行反射和折射。极化滤波的作用就是只允许正交于横向方向的光通过,以此来提高照片的对比度。但由于它会阻挡一部分光线,导致图像整体亮度降低并缩小动态范围,从而可能导致细节丢失,因此需要通过后期处理来恢复原始场景的细节。
作者思考:基于上述思想,作者决定在一个方向上对特征进行压缩,然后对损失的强度范围进行提升,,以实现高质量的像素级回归具体可分为两个结构:
(1)极化滤波(Filtering):使一个维度的特征(通道维度)完全压缩输入张量沿其对应维度,同时让正交方向的维度(空间维度)保持高分辨率。
(2)High Dynamic Range(HDR):首先在attention模块中最小的tensor上用Softmax函数来增加注意力的范围,然后再用Sigmoid函数进行动态的映射。
作者设计并行(PSA_p)和串行(PSA_s)两种,并行结构同时处理空间和通道注意力,结果相加;串行结构先空间注意力,后通道注意力。作者给出的公式是直接对下图卷积、reshape、sigmoid等转为符号化表示,不如图形直观易理解,因此不详细介绍,详细结构如下所示:
方法对比
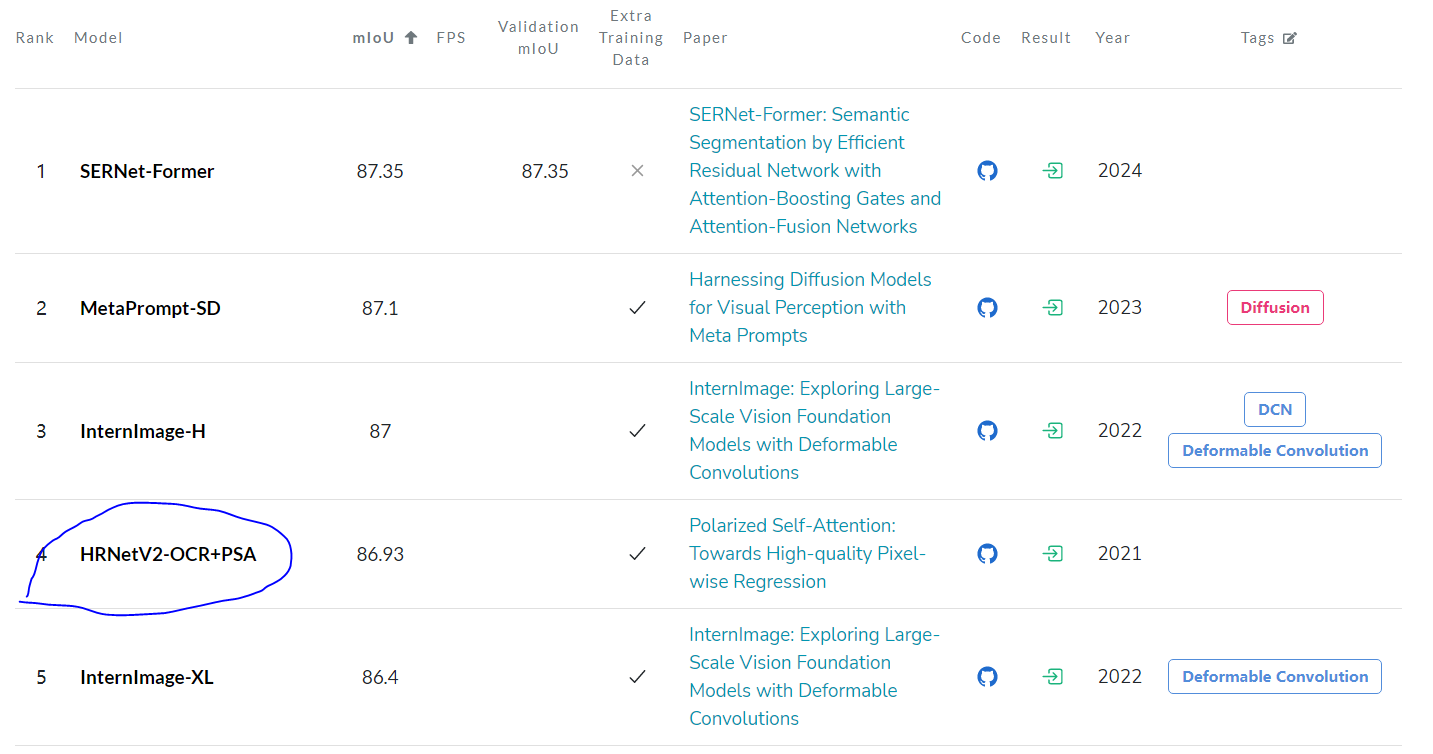
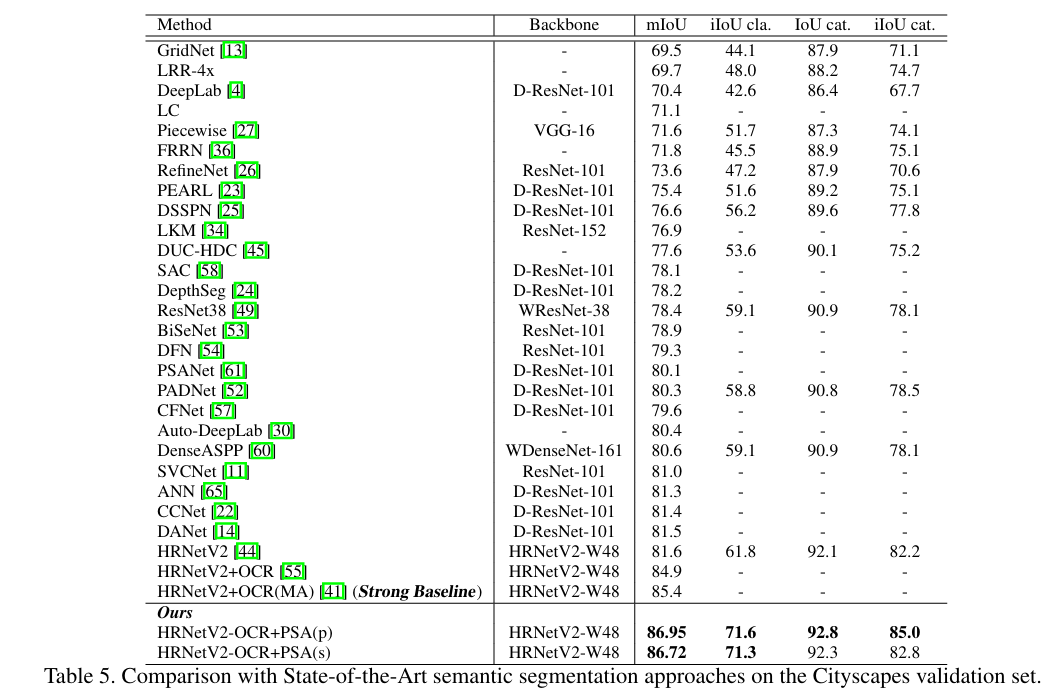
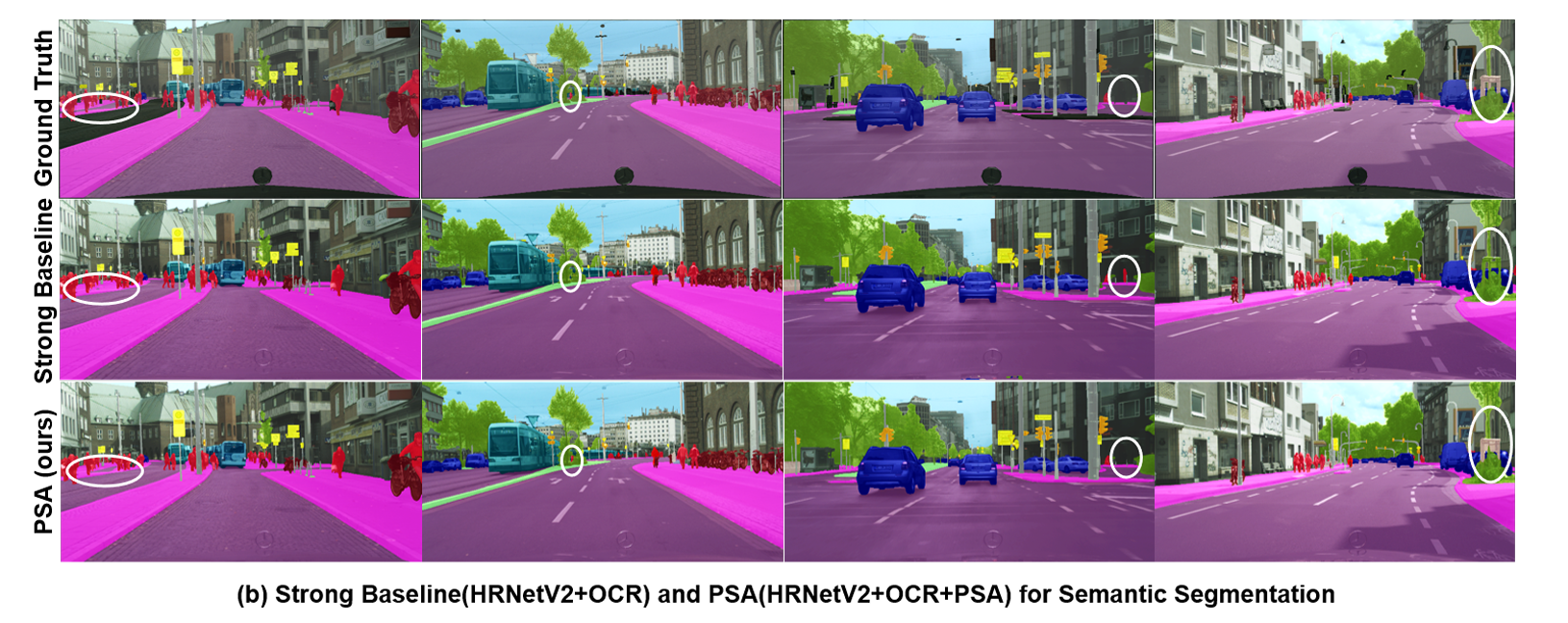
在Cityscapes语义分割数据集上,基于PSA的HRNet-OCR结构,达到了86.95 mIoU的新SOTA性能,该性能直到2025年3月仍为该数据精度榜单第4。
结构代码
将下述完整结构代码复制后命名为PSA.py,其中PSA_p类为并行双分支结构,PSA_s类 为串行级联结构。两个结构在其他模型中任意位置可import即插即用。定义接口只需要输入输出通道数,如:
class unet(nn.Module):
def __init__(self, inplanes, planes, stride=1, downsample=None):
self.psattn = PSA_s(planes, planes)
..........
def forward(self, x):
..........
x = self.psattn (x)
..........
完整结构代码
import torch
import torch.nn as nn
import torch._utils
import torch.nn.functional as F
def constant_init(module, val, bias=0):
if hasattr(module, 'weight') and module.weight is not None:
nn.init.constant_(module.weight, val)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def kaiming_init(module,
a=0,
mode='fan_out',
nonlinearity='relu',
bias=0,
distribution='normal'):
assert distribution in ['uniform', 'normal']
if distribution == 'uniform':
nn.init.kaiming_uniform_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
else:
nn.init.kaiming_normal_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
class PSA_p(nn.Module):
def __init__(self, inplanes, planes, kernel_size=1, stride=1):
super(PSA_p, self).__init__()
self.inplanes = inplanes
self.inter_planes = planes // 2
self.planes = planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = (kernel_size-1)//2
self.conv_q_right = nn.Conv2d(self.inplanes, 1, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_v_right = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_up = nn.Conv2d(self.inter_planes, self.planes, kernel_size=1, stride=1, padding=0, bias=False)
self.softmax_right = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.conv_q_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #g
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_v_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #theta
self.softmax_left = nn.Softmax(dim=2)
self.reset_parameters()
def reset_parameters(self):
kaiming_init(self.conv_q_right, mode='fan_in')
kaiming_init(self.conv_v_right, mode='fan_in')
kaiming_init(self.conv_q_left, mode='fan_in')
kaiming_init(self.conv_v_left, mode='fan_in')
self.conv_q_right.inited = True
self.conv_v_right.inited = True
self.conv_q_left.inited = True
self.conv_v_left.inited = True
def spatial_pool(self, x):
input_x = self.conv_v_right(x)
batch, channel, height, width = input_x.size()
# [N, IC, H*W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, H, W]
context_mask = self.conv_q_right(x)
# [N, 1, H*W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H*W]
context_mask = self.softmax_right(context_mask)
# [N, IC, 1]
# context = torch.einsum('ndw,new->nde', input_x, context_mask)
context = torch.matmul(input_x, context_mask.transpose(1,2))
# [N, IC, 1, 1]
context = context.unsqueeze(-1)
# [N, OC, 1, 1]
context = self.conv_up(context)
# [N, OC, 1, 1]
mask_ch = self.sigmoid(context)
out = x * mask_ch
return out
def channel_pool(self, x):
# [N, IC, H, W]
g_x = self.conv_q_left(x)
batch, channel, height, width = g_x.size()
# [N, IC, 1, 1]
avg_x = self.avg_pool(g_x)
batch, channel, avg_x_h, avg_x_w = avg_x.size()
# [N, 1, IC]
avg_x = avg_x.view(batch, channel, avg_x_h * avg_x_w).permute(0, 2, 1)
# [N, IC, H*W]
theta_x = self.conv_v_left(x).view(batch, self.inter_planes, height * width)
# [N, 1, H*W]
# context = torch.einsum('nde,new->ndw', avg_x, theta_x)
context = torch.matmul(avg_x, theta_x)
# [N, 1, H*W]
context = self.softmax_left(context)
# [N, 1, H, W]
context = context.view(batch, 1, height, width)
# [N, 1, H, W]
mask_sp = self.sigmoid(context)
out = x * mask_sp
return out
def forward(self, x):
# [N, C, H, W]
context_channel = self.spatial_pool(x)
# [N, C, H, W]
context_spatial = self.channel_pool(x)
# [N, C, H, W]
out = context_spatial + context_channel
return out
class PSA_s(nn.Module):
def __init__(self, inplanes, planes, kernel_size=1, stride=1):
super(PSA_s, self).__init__()
self.inplanes = inplanes
self.inter_planes = planes // 2
self.planes = planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = (kernel_size - 1) // 2
ratio = 4
self.conv_q_right = nn.Conv2d(self.inplanes, 1, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_v_right = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False)
# self.conv_up = nn.Conv2d(self.inter_planes, self.planes, kernel_size=1, stride=1, padding=0, bias=False)
self.conv_up = nn.Sequential(
nn.Conv2d(self.inter_planes, self.inter_planes // ratio, kernel_size=1),
nn.LayerNorm([self.inter_planes // ratio, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.inter_planes // ratio, self.planes, kernel_size=1)
)
self.softmax_right = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.conv_q_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False) # g
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_v_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False) # theta
self.softmax_left = nn.Softmax(dim=2)
self.reset_parameters()
def reset_parameters(self):
kaiming_init(self.conv_q_right, mode='fan_in')
kaiming_init(self.conv_v_right, mode='fan_in')
kaiming_init(self.conv_q_left, mode='fan_in')
kaiming_init(self.conv_v_left, mode='fan_in')
self.conv_q_right.inited = True
self.conv_v_right.inited = True
self.conv_q_left.inited = True
self.conv_v_left.inited = True
def spatial_pool(self, x):
input_x = self.conv_v_right(x)
batch, channel, height, width = input_x.size()
# [N, IC, H*W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, H, W]
context_mask = self.conv_q_right(x)
# [N, 1, H*W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H*W]
context_mask = self.softmax_right(context_mask)
# [N, IC, 1]
# context = torch.einsum('ndw,new->nde', input_x, context_mask)
context = torch.matmul(input_x, context_mask.transpose(1, 2))
# [N, IC, 1, 1]
context = context.unsqueeze(-1)
# [N, OC, 1, 1]
context = self.conv_up(context)
# [N, OC, 1, 1]
mask_ch = self.sigmoid(context)
out = x * mask_ch
return out
def channel_pool(self, x):
# [N, IC, H, W]
g_x = self.conv_q_left(x)
batch, channel, height, width = g_x.size()
# [N, IC, 1, 1]
avg_x = self.avg_pool(g_x)
batch, channel, avg_x_h, avg_x_w = avg_x.size()
# [N, 1, IC]
avg_x = avg_x.view(batch, channel, avg_x_h * avg_x_w).permute(0, 2, 1)
# [N, IC, H*W]
theta_x = self.conv_v_left(x).view(batch, self.inter_planes, height * width)
# [N, IC, H*W]
theta_x = self.softmax_left(theta_x)
# [N, 1, H*W]
# context = torch.einsum('nde,new->ndw', avg_x, theta_x)
context = torch.matmul(avg_x, theta_x)
# [N, 1, H, W]
context = context.view(batch, 1, height, width)
# [N, 1, H, W]
mask_sp = self.sigmoid(context)
out = x * mask_sp
return out
def forward(self, x):
# [N, C, H, W]
out = self.spatial_pool(x)
# [N, C, H, W]
out = self.channel_pool(out)
# [N, C, H, W]
# out = context_spatial + context_channel
return out


















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









