







链接:bert-base-chinese at main (huggingface.co),将下图中,画红框的文件下载下来。在项目的根目录新建chinese_wwm_pytorch文件夹,将下载的文件放进去。
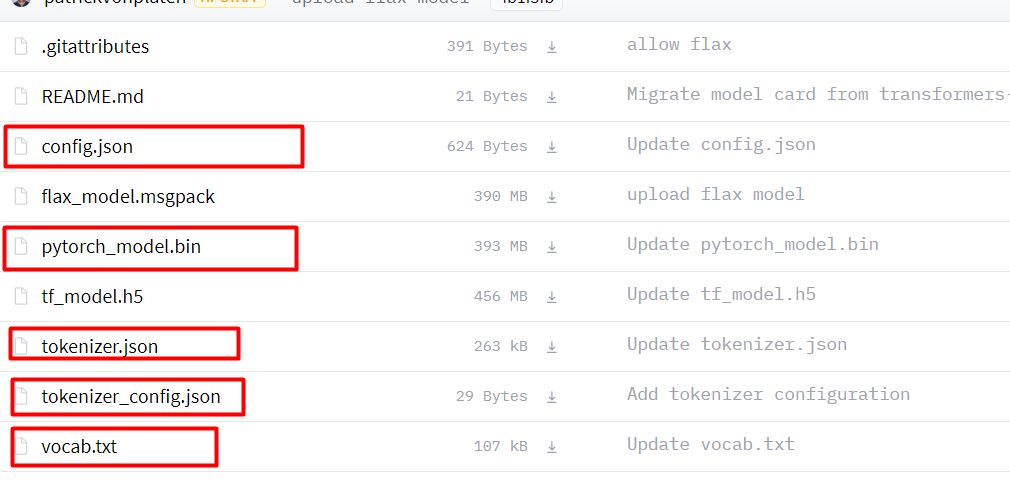
新建outs文件夹,将config.json、tokenizer.json、tokenizer_config.json和vocab.txt复制到outs文件夹中。
注:模型的类型在configuration_bert.py中查看。选择合适的模型很重要,比如这次是中文文本的分类。选择用bert-base-uncased只能得到86%的准确率,但是选用bert-base-chinese就可以轻松达到96%。
====================================================&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









