






1.YOLOv5是一个基于深度学习的实时目标检测模型,它在YOLO系列中具有重要地位。与之前的YOLO版本相比,YOLOv5具有更高的效率和易用性,采用了PyTorch框架实现,支持多种模型大小,满足不同应用场景的需求。它不仅具备出色的实时性和较高的精度,还提供了灵活的训练和部署方式,使得开发者能够方便地进行模型微调和迁移学习。YOLOv5通过优化数据增强、模型蒸馏等技术,提高了检测精度和召回率,特别在处理小物体时表现更佳。它支持多平台部署,并且有活跃的开源社区,提供了详细的文档和易于使用的代码库,是目前最受欢迎的目标检测工具之一。
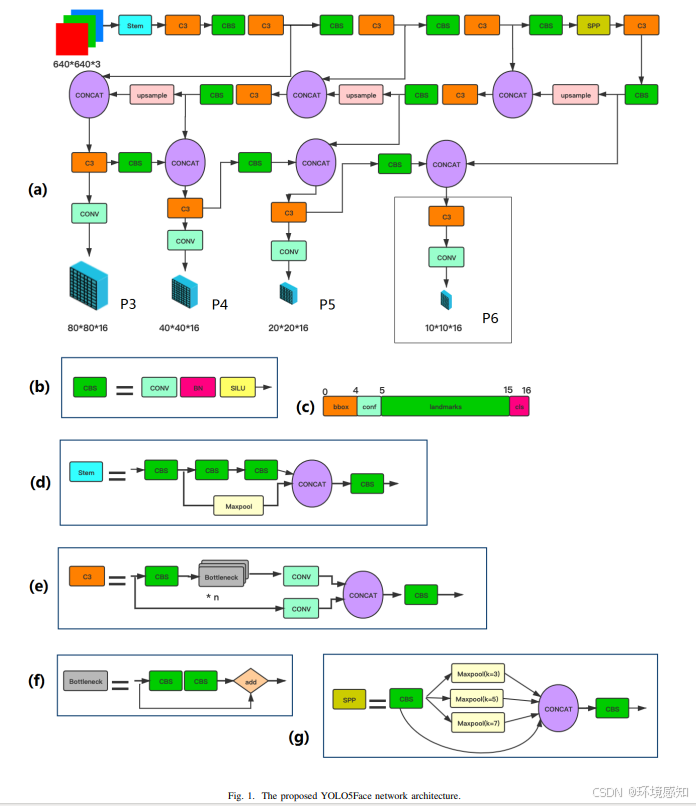
2.yolov5的网络结构如下图所示,关于其详细代码的原理可自行查找网上内容进行学习。
3. 首先利用conda创建相应的虚拟环境并进入环境,同时下载文件并进入其文件夹:
conda create -n yolo python=3.8
conda activate yoloconda info --envs #如果忘记创建的环境名,可以用这个命令查询
git clone https://github.com/ultralytics/yolov5
cd yolov5
4. 安装所需的环境及相应的配置文件:
pip install -r requirements.txt
5. 在data文件夹下建立相应的images和labels文件,存放KITTI数据集,以及相应的转换后的标签:
5.1.对于标签的转换,首先运行1生成标签.py文件用于kitti数据集格式的转换,其代码内容为:
import glob
import cv2
from tqdm import tqdm
import os
# 类别映射
dic = {'Car': 0, 'Van': 1, 'Truck': 2, 'Tram': 3, 'Pedestrian': 4, 'Person_sitting': 4, 'Cyclist': 5, 'Misc': 6}
def changeformat():
# 路径配置
img_path = '/home/pc/yolov5/data/images/*' # kitti图像数据
label_path = '/home/pc/yolov5/data/label_2/' # kitti标签数据
filename_list = glob.glob(img_path)
save_path = '/home/pc/yolov5/data/labels/' # 修改后标签数据
# 如果保存路径不存在则创建
if not os.path.exists(save_path):
os.makedirs(save_path)
# 检查是否找到图像
if not filename_list:
print("No images found in the specified path.")
return
# 统计类别的处理次数
category_count = {key: 0 for key in dic.keys()}
ignored_count = 0
processed_images = 0
# 遍历图像文件
for img_name in tqdm(filename_list, desc='Processing'):
image_name = os.path.basename(img_name).split('.')[0] # 获取图片名称(无扩展名)
label_file = os.path.join(label_path, image_name + '.txt') # 找到对应的标签
savelabel_path = os.path.join(save_path, image_name + '.txt') # 修改后标签保存路径
# 检查标签文件是否存在
if not os.path.exists(label_file):
print(f"Label file not found: {label_file}")
continue
# 读取图像
img = cv2.imread(img_name)
if img is None:
print(f"Failed to load image: {img_name}")
continue
h, w, _ = img.shape
dw = 1.0 / w
dh = 1.0 / h # 归一化比例
# 读取标签
with open(label_file, 'r') as f:
labels = f.readlines()
# 清空标签文件内容以避免追加重复数据
with open(savelabel_path, 'w') as w:
for label in labels:
label = label.split(' ')
# 检查标签长度是否正确
if len(label) < 8:
print(f"Incomplete label in file {label_file}: {label}")
continue
classname = label[0]
if classname not in dic:
ignored_count += 1 # 统计被忽略的标签
continue
# 获取位置信息并进行归一化
x1, y1, x2, y2 = map(float, label[4:8])
bx = ((x1 + x2) / 2.0) * dw
by = ((y1 + y2) / 2.0) * dh
bw = (x2 - x1) * dw
bh = (y2 - y1) * dh
# 保留6位小数
bx = round(bx, 6)
by = round(by, 6)
bw = round(bw, 6)
bh = round(bh, 6)
# 获取类别索引
classindex = dic[classname]
category_count[classname] += 1 # 统计该类别的标签数量
# 写入转换后的标签
w.write(f'{classindex} {bx} {by} {bw} {bh}\n')
processed_images += 1
# 打印统计信息
print(f'Done processing {processed_images} images!')
print(f'Ignored {ignored_count} labels not in the dictionary.')
for classname, count in category_count.items():
print(f'{classname}: {count} labels processed.')
# 调用函数
changeformat()
5.2. 运行2划分数据集.py文件进行数据集标签的划分:
import glob
import random
def splitdataset():
random.seed(1234)
label_path = '/home/pc/yolov5/data/labels/*.txt' # 修改为上一步保存的新标签的位置
filename_list = glob.glob(label_path)
num_file = len(filename_list)
val = 0.15 # 验证集的比例
try:
val_file = open('/home/pc/yolov5/data/val.txt', 'w', encoding='utf-8') # 包含验证集的txt文件,修改为自己想要保存的位置
train_file = open('/home/pc/yolov5/data/train.txt', 'w', encoding='utf-8') # 包含训练集的txt文件,修改为自己想要保存的位置
for i in range(num_file):
if random.random() < val:
val_file.write(f'/home/pc/yolov5/data/images/{i:06}.png\n') # 修改为kitti数据集图片的位置,即txt文件里存的是图片的位置
else:
train_file.write(f'/home/pc/yolov5/data/images/{i:06}.png\n') # 修正路径
finally:
val_file.close()
train_file.close()
# 调用函数
splitdataset()
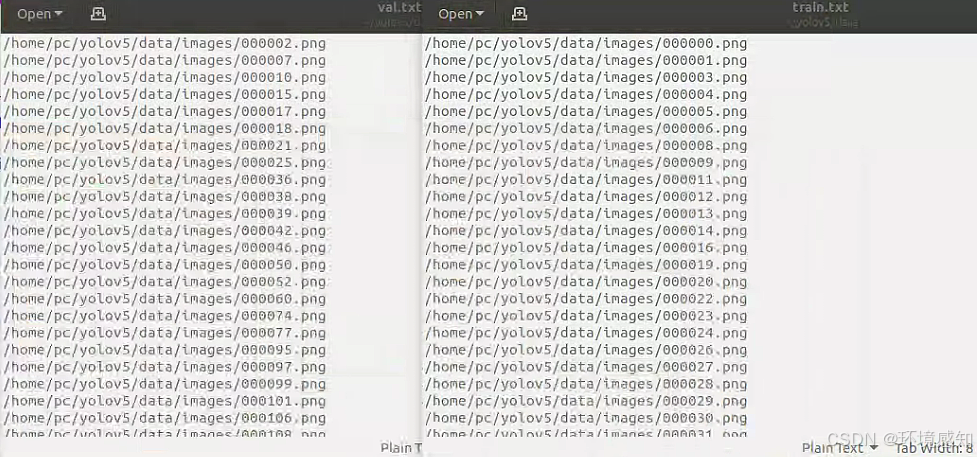
生成的标签索如下图所示:
 6. 最最最重要的,在当前文件夹仿照coco128.yaml文件的内容,写一个kitti.yaml的文件,其内容如下:
6. 最最最重要的,在当前文件夹仿照coco128.yaml文件的内容,写一个kitti.yaml的文件,其内容如下:
# Ultralytics YOLOv5 , AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/pc/yolov5/data # dataset root dir
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images
# test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0: car
1: van
2: truck
3: tram
4: pedestrian
5: cyclist
6: misc
7. 在model文件夹下选择我们需要的不同模型版本,YOLOv5的s、m、l、n、x版本主要在模型大小、参数量、计算量和精度上有所不同。YOLOv5s是最小的版本,适合资源有限的设备,推理速度最快但精度较低;YOLOv5m提供了速度与精度的平衡,适合大多数中等性能的硬件;YOLOv5l在精度上更强,但计算量较大,适合对精度要求较高的场景;YOLOv5x是最大的版本,精度最高,但需要最强的计算资源,适合高精度要求且资源充足的应用。选择哪个版本取决于具体的硬件条件和应用需求。

8.我们以yolov5s.yaml为例,主要修改其种类的数量nc: 7 # number of classes,完整的代码如下所示:
# Ultralytics YOLOv5 , AGPL-3.0 license
# Parameters
nc: 7 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
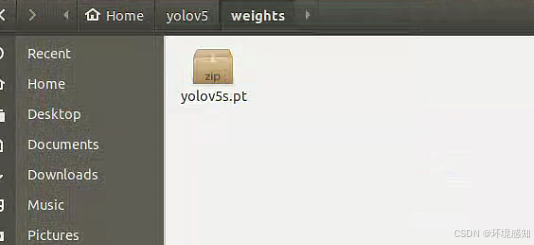
]9.接下来需要下载相应的训练权重文件,放在 /yolov5/weights文件夹下,如下图所示:
当然可以下载其它的权重文件,修改的配置文件也需修改种类的个数 nc: 7 # number of classes
权重的下载地址为:
在文件夹中的路径为data/scripts/download_weights.sh
github地址:https://github.com/ultralytics/yolov5/releases
10.修改配置文件train.py,主要修改以下几个部分:分别是权重文件地址,模型参数位置、结构文件、数据位置、训练次数、以及训练轮数。
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/kitti.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")11.之后在当前文件夹下输入一下命令开始训练:
python train.py
训练过程如下:
12.训练结束后会在文件夹yolov5/runs/train/exp里生成相应的训练配置文件:
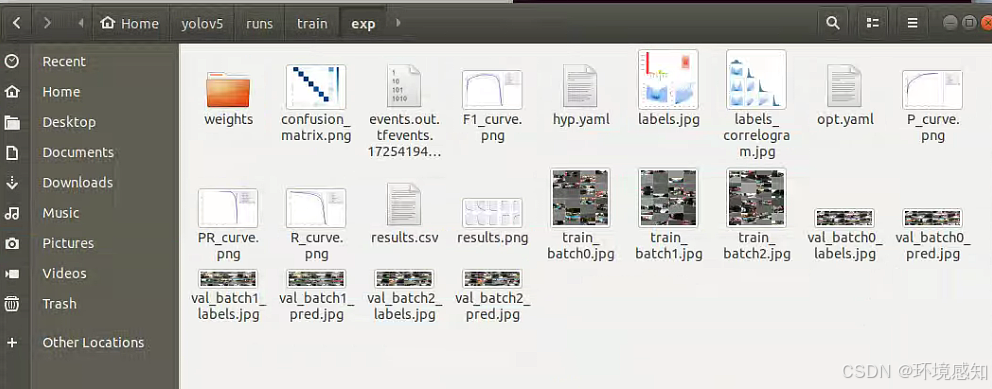
其中weights就是我们这次训练之后的权重,之后进行模型测试,在detect.py文件修改检测文件数据集位置可以自己随意放,以及修改权重文件所在的位置:
weights=ROOT / "yolov5s.pt", # model path or triton URL
source=ROOT / "data/images", # file/dir/URL/glob/screen/0(webcam)
13.之后会在/yolov5/runs/detect/exp中生成我们训练好的已经检测过的图片:
14.检测效果如下图所示:


15.后续进行yolov8的复现,以及自制数据集的训练


















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









