









机器学习概念
何为机器学习?
1.西瓜书中简明扼要地阐述了机器学习是研究“学习算法”的学问。
2.根据SAS Inc. 给出的解释:
Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.
可见ML一方面是数据分离和自动化建模的过程,另一方面是人工智能中的一个分支,且系统可以最大程度的避免人为干预,并基于数据进行学习,模式识别或者进行决策、
3.根据维基百科的定义,有如下几种:
a.机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
b.机器学习是对能通过经验自动改进的计算机算法的研究。
c.机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
四大学习方法类别
监督学习 Supervised Learning
定义:
监督学习就是从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
简单说,就是给你一堆西瓜,在输入数据集进行训练时候,你会明确告诉机器,色泽绿,声音响亮,尾巴卷或者怎样的是好瓜,或者图片中把人都标记出来,进行学习。样本对应的有标签、其实就是监督学习
常见的学习算法有:线性回归、逻辑回归、统计分类、决策树、朴素贝叶斯、KNN
应用于:价格预测、图像识别、语音翻译……
无监督学习 Unsupervised Learning
定义:
监督学习和非监督学习的差别就是训练集目标是否人标注。他们都有训练集 且都有输入和输出
简单的说,没有标记了,就像你去街边买瓜,卖瓜的也不知道什么好瓜坏瓜,但是可以直观的从一大堆瓜中区分、例如按照大小,落成一落落。或按照瓜的颜色,落成一落落。。这也算是聚类的一种
常见的学习算法有:生成对抗网络GAN、聚类算法、PCA降维、异常检测
应用场景:客户划分、新闻聚类、数据降维
半监督学习 Semi-supervised Learning
有部分数据是有标签的,介于监督学习和无监督学习之间
这个场景也很多,比如到手的数据集部分有标记,部分无标记。其实就是通过半监督学习来进行训练模型
常见学习算法:结合监督学习和无监督学习
应用场景:混血学习应用……
强化学习 Reinforcement Learning
程序初始化->根据执行效果给予奖励/惩罚->逐步寻找获得高分的方法
为了达成目标,随着环境的变动,而逐步调整其行为,并评估每一个行动之后所到的回馈是正向的或负向的。
应用场景:OpenAi Five/AlphaGo…
线性回归
模型求解与线性回归
给定数据集D={(x1,y1),(x2,y2)…(xm,ym)},其中x是向量,xi=(xi1,xi2,xi3,…xid),yi属于R,"线性回归"识途血的一个线性模型以尽可能准确地预测实值输出标记
梯度下降法
简单来说,本来有x->y,现在经过模型预测后变成了x->y^
y^=wx+b
我们希望y与y’尽可能地接近
loss损失函数=|y^-y|min=h(theta)
theta就对应着w和b两个参数
h’(theta)=0,不断进行求导,调theta至对loss满意
准备工作Scikit-learn
Scikit-learn是针对机器学习应用而开发的算法库
常用功能:数据预处理、分类、回归、降维、模型选择等常用的机器学习算法
三大优点:1 丰富的算法模块 2 易于安装与使用 3 样例丰富、教程文档详细
任务一: 基于面积的单因子房价预测
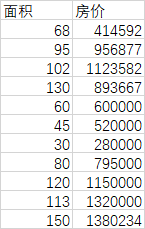
基于下表数据,建立单因子线性回归模型,预测面积100平米售价120万是否值得投资?
step1 完成数据加载与可视化
import pandas as pd
import numpy as np
data=pd.read_csv('task1_data.csv')
data.head()#读入成功
面积 房价
0 68 414592
...
step2 进行数据预处理(x,y赋值,格式转化,维度确认)
#x y赋值
x=data.loc[:,'面积']
y=data.loc[:,'房价']
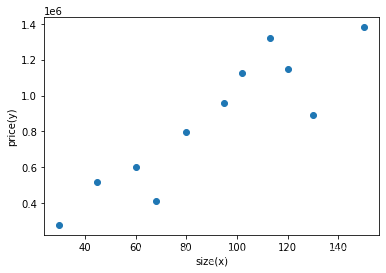
#数据可视化
from matplotlib import pyplot as plt
fig1=plt.figure()
plt.scatter(x,y)
plt.xlabel('size(x)')
plt.ylabel('price(y)')
plt.show()
#格式
x=np.array(x)
y=np.array(y)
#维度转化
x=x.reshape(-1,1)#行数不变,列数变1
y=y.reshape(-1,1)
step3 建立单因子线性回归模型,训练模型
#建立模型 linear regression
from sklearn.linear_model import LinearRegression
model=LinearRegression()
print(model)
#训练模型
model.fit(x,y)
#获取线性回归模型参数a,b
a=model.coef_
b=model.intercept_
print(a)
print(b)
[[8905.69177214]]
[53690.91547905]
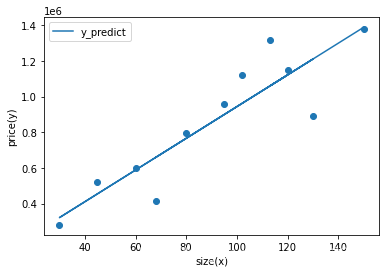
step4 评估模型表现,可视化线性回归预测结果
#结果预测法一
y_predict=8905.69177214*x+53690.91547905
#第二种预测方法
y_predict2=model.predict(x)
#数据可视化
fig2=plt.figure()
plt.scatter(x,y)
plt.plot(x,y_predict,label='y_predict')
plt.xlabel('size(x)')
plt.ylabel('price(y)')
plt.legend()
plt.show()
#模型评估
from sklearn.metrics import mean_squared_error,r2_score
MSE=mean_squared_error(y,y_predict)
R2=r2_score(y,y_predict)
print(MSE)
print(R2)
24142828491.61458
0.8059384532844912
均方误差(MSE)

均方误差亦称为平方损失(square loss)
均方误差有非常好的几何意义,对应了常用的欧氏距离。通过均方误差最小化来进行模型优化
R^2分数
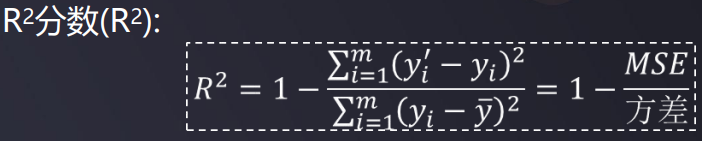
在统计学中对变量进行线行回归分析,采用最小二乘法进行参数估计时,R平方为回归平方和与总离差平方和的比值,表示总离差平方和中可以由回归平方和解释的比例,这一比例越大越好,模型越精确,回归效果越显著。R平方介于0~1之间,越接近1,回归拟合效果越好,一般认为超过0.8的模型拟合优度比较高。
总而言之:
MSE越小越好,R^2分数越接近1越好
回答问题
#测试样本x_test=100,计算y^
x_test=np.array([[100]])
y_test_predict=model.predict(x_test)
print(y_test_predict)
[[944260.09269259]]
任务二:实现多因子房价预测
以面积为输入变量,建立单因子模型,评估模型表现,可视化线性回归预测结果
import pandas as pd
import numpy as np
data=pd.read_csv('task2_data.csv')
面积 人均收入 平均房龄 价格
0 188.581619 79245.63626 4.901877 1.096850e+06
1 164.161571 78936.74809 4.688919 1.455588e+06
2 232.949602 63236.99563 4.878289 1.051696e+06
3 150.608655 65122.34212 3.577503 1.373964e+06
4 153.862555 63628.64511 5.877775 6.231222e+05
from matplotlib import pyplot as plt
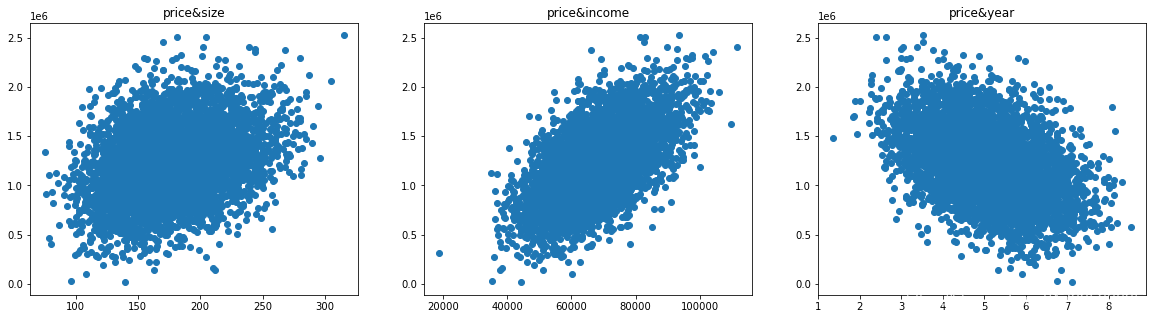
fig= plt.figure(figsize=(20,5))
fig1=plt.subplot(131)
plt.scatter(data.loc[:,'面积'],data.loc[:,'价格'])
plt.title('price&size')
fig2=plt.subplot(132)
plt.scatter(data.loc[:,'人均收入'],data.loc[:,'价格'])
plt.title('price&income')
fig3=plt.subplot(133)
plt.scatter(data.loc[:,'平均房龄'],data.loc[:,'价格'])
plt.title('price&year')
plt.show()
# x,y赋值
x=data.loc[:,'面积']
y=data.loc[:,'价格']
#数据预处理
x=np.array(x)
y=np.array(y)
x=x.reshape(-1,1)
y=y.reshape(-1,1)
print(x.shape,y.shape)
#模型建立训练
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(x,y)
y_predict=model.predict(x)
print(y_predict)
[[1273463.80967472]
[1192500.07431933]
[1420564.16140447]
...
[1113233.11006996]
[1237040.41730573]
[1162515.70057855]]
#模型评估
from sklearn.metrics import mean_squared_error,r2_score
MSE=mean_squared_error(y,y_predict)
R2=r2_score(y,y_predict)
print(MSE)
print(R2)
116859388203.27335
0.10766339222843158
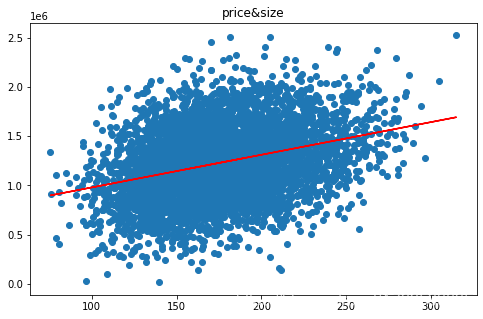
fig2= plt.figure(figsize=(8,5))
plt.scatter(data.loc[:,'面积'],data.loc[:,'价格'])
plt.plot(x,y_predict,'r')
plt.title('price&size')
以面积、人均收入、平均房龄作为输入变量,建立多因子模型,评估模型表现
#x,y再次赋值
x=data.drop(['价格'],axis=1)
y=data.loc[:,'价格']
#建立多因子回归模型 并且训练
model_multi=LinearRegression()
model_multi.fit(x,y)
#多因子模型的预测
y_predict_multi=model_multi.predict(x)
print(y_predict_multi)
[1463868.24688829 1445981.85185019 1253388.6205439 ... 1285670.68139457
1243839.71867446 1116875.92416746]
MSE_multi=mean_squared_error(y,y_predict_multi)
R2_multi=r2_score(y,y_predict_multi)
print(MSE_multi)
print(R2_multi)
58264450329.883
0.555093495178965
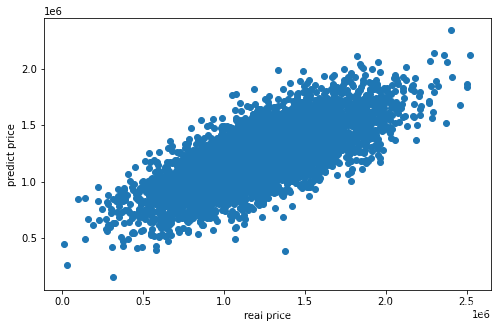
#可视化多因子训练后的预测结果
fig3=plt.figure(figsize=(8,5))
plt.scatter(y,y_predict_multi)
plt.xlabel('real price')
plt.ylabel('predict price')
plt.show()
预测面积=160,人均收入70000,平均房龄=5的合理房价
#预测面积=160,人均收入,70000 平均房龄=5的合理房价
x_test=np.array([[160,70000,5]])
y_test_predict=model_multi.predict(x_test)
print(y_test_predict)
[1235099.47156076]
由上对比很直观,多因子训练出来的模型具有更高的拟合度、















 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











