






背景
近年来,大型语言模型(LLMs),如OpenAI的GPT系列和Google的BERT,已经显示出在多种自然语言处理任务中的出色能力。这些模型通常在多语言语料库上进行预训练,但在非英语任务上的性能常常不尽人意,尤其是在资源稀缺的语言上。
挑战
尽管LLMs在资源丰富的语言(如英语)上表现良好,它们在多语言应用上仍面临挑战。由于训练数据的不平衡,这些模型在资源稀缺语言上的表现往往落后。此外,仅依赖机器翻译生成的数据进行监督微调,会引入噪声并可能损害模型的性能,甚至会降低在资源丰富的语言上的表现。
方法
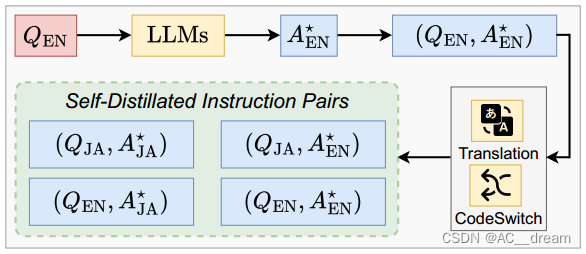
Self-Distillation from Resource-Rich Languages (Ours)
本文提出了一种名为SDRRL(利用资源丰富语言进行自我蒸馏)的新方法。SDRRL利用资源丰富语言的模型内在能力来增强多语言表现,具体包括两大策略:
1. 自我蒸馏:在资源丰富的语言中使用大型语言模型生成回答,并将这些回答作为“教师”来指导其他语言的“学生”模型。这一过程不依赖于真实的标签,而是使用从资源丰富语言生成的响应来构成transfer集合。然后利用机器翻译系统和代码转换工具将响应翻译成目标语言,形成语义相同但语言不同的问答对,并在同一批中进行句子级自蒸馏。
2. 外部平行语料库的整合:通过引入少量的机器翻译数据,来更好地对齐语言表示空间,减少机器翻译系统噪声对生成能力的负面影响,改善跨语言的知识转移。

CodeSwitch
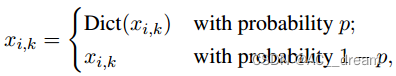

引入外部平行语料库

以印尼语-英语为例,给出了构建Dmt和Dcomp的模板。Dmt包括双向翻译。Dcomp只包含目标语言句子,这些句子在随机位置被分割。

训练目标
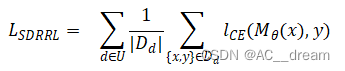
U={LL,TL,LT,TT,mt,comp}
实验结果
研究主要在BELEBELE、FLORES、XL-SUM、MKQA四个数据集上进行测试。
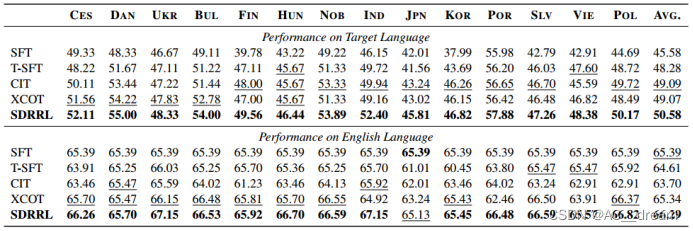
BELEBELE数据集上的结果
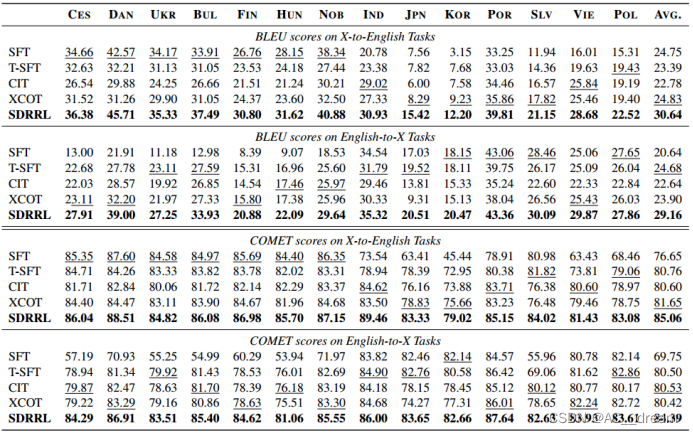
FLORES数据集上的结果
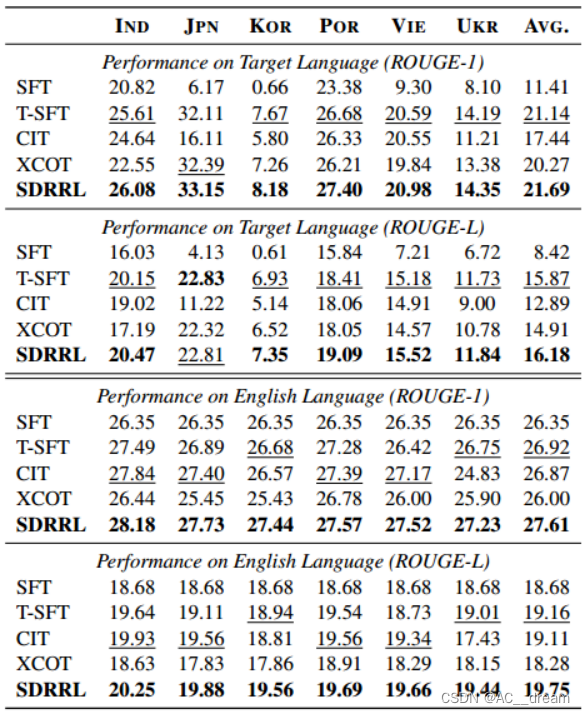
XL-SUM数据集上的结果
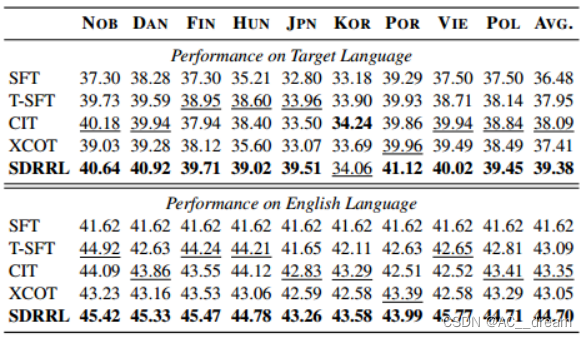
MKQA数据集上的结果
从结果中可以看出SDRRL在理解任务中的表现提高了大约+1.5 BLEU分数,说明SDRRL有效地提高了目标语言的性能。在Flores数据集上的结果可以得到,资源丰富语言的熟练反应作为知识蒸馏的监督信号,显著提高了其他目标语言的性能。从XL-SUM数据集上的结果我们可以看出SDRRL在生成任务中表现出较强的鲁棒性。SDRRL还能在英语任务上保持较高的原始能力,但是从BELEBELE数据集上的结果我们也可以看出对于像日语这样有独特字符的语言,保持原始英语能力是一件比较困难的事情,通过SFT方法的结果能看出线性方法导致英语性能下降,而SDRRL方法已经最大程度的保留了原始英语的能力。
研究团队在多个多语言理解和生成任务上评估了SDRRL方法,例如LLaMA-2和SeaLLM,涵盖了英语和法语等资源丰富的语言。实验结果表明,SDRRL能够显著提升LLMs在多语言任务上的性能,同时保持或甚至提升在资源丰富语言上的表现。此外,通过实验还证明了自我蒸馏在减少对昂贵外部翻译依赖方面的潜力。
总结
本文提出的SDRRL方法有效地解决了大型多语言模型在处理非资源丰富语言时的性能问题,通过内部生成能力的利用和高质量翻译数据的整合,实现了对多语言能力的显著增强。这不仅推动了多语言模型在理论上的发展,也为实际应用中的语言模型部署提供了新的思路。















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









