






model-base-s3dis风格自定义数据集制作
model_base的意思是:已知一个3d模型,训练并将其检测出来。
一、s3dis数据集详解
由上述链接可以知道:
(1)s3dis数据集分为6个区域,每个区域有许多房间;
(2)每个区域的文件夹结构为:
以hallway3为例:
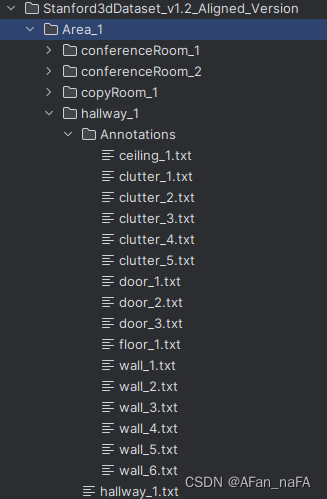 其中每个房间文件夹(hallway3)文件夹下有hallway3.txt以及一个Anotations文件夹;其中hallway3.txt是这个房间的点云文件, 由annotations文件夹中的所有点云文件组成。
其中每个房间文件夹(hallway3)文件夹下有hallway3.txt以及一个Anotations文件夹;其中hallway3.txt是这个房间的点云文件, 由annotations文件夹中的所有点云文件组成。
(3)每个annotations文件夹中夹的文件名即为其标注;
(4)每个txt文件的每一行代表一个点,每一列代表一个维度;
(5)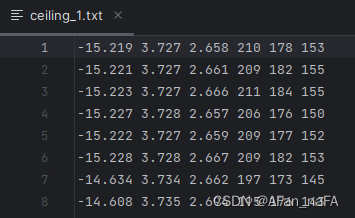
s3dis点云数据有6个维度,分别是xyz坐标和rgb颜色信息。
好!知道了以上信息,聪明的你一定有一个朴素的想法,我想训练自己的数据集,一个简单的方法就是把自己的txt文件起好名字放在annotations文件夹中,再跟房间点云合并起来即可。
二、model处理
随便下载一个3D模型,这里以小马为例。
这里需要下载一个看点云的软件,推荐cloudCompare。安装参考:
ubuntu 安装 cloudcompare(两种方法)_ubuntu cloudcompare-CSDN博客
通过以上软件打开后:

下载的3Dmodel通常是stl和obj格式的。通过第一节可以知道,s3dis数据集的点云文件是txt格式的。所以第一步...
2.1 obj2txt:
# 打开OBJ文件并读取内容
with open('/home/afan/Downloads/Arabian_Horse_Galloping_V2_L1.123c04971ec6-5ac5-40e7-bcac-936197b82865/16270_Arabian_Horse_Galloping_V2.obj', 'r') as file:
lines = file.readlines()
# 提取顶点坐标并保存到列表
vertices = []
for line in lines:
if line.startswith('v '):
vertex = line.split()[1:] # 提取x, y, z坐标
vertices.append(vertex)
# 将顶点坐标写入TXT文件
with open('/home/afan/Desktop/0021hk/txt/hourse.txt', 'w') as file:
for vertex in vertices:
file.write(' '.join(vertex) + '\n')得到的点云文件通过cloudCompare打开之后如下图

打开txt文件: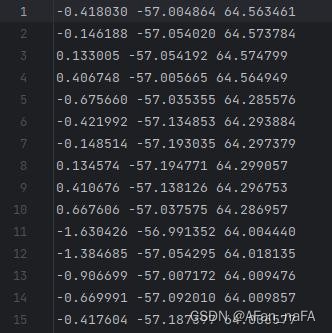 可以看到是3维的,只有xyz坐标信息,没有颜色信息。所以需要...
可以看到是3维的,只有xyz坐标信息,没有颜色信息。所以需要...
2.2 addcolor(dim3-->dim6)
def append_color_to_file_in_place(file_path, color=[255, 255, 255]):
with open(file_path, 'r') as infile:
lines = infile.readlines()
with open(file_path, 'w') as outfile:
for line in lines:
line = line.strip() # 移除行尾的换行符和多余的空白
colored_line = f"{line} {color[0]} {color[1]} {color[2]}\n"
outfile.write(colored_line)
# 示例使用
file_path = '/home/afan/Desktop/0021hk/txt/a.txt'
color = [255, 255, 255] # 阿拉伯白马!
append_color_to_file_in_place(file_path, color)上述代码替换为加颜色的txt。
同样的方法,我又添加了一只蓝猫:

三、数据集制作
3.1 准备
文件夹目录如下
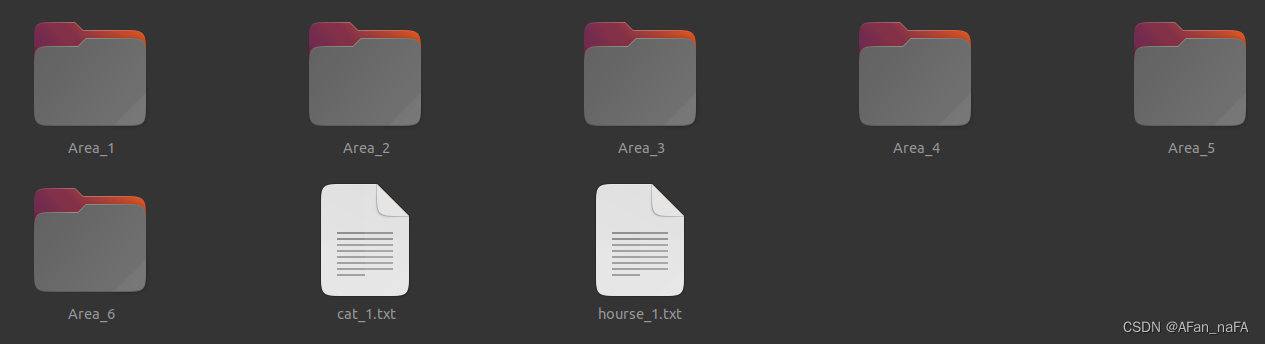
cat_1.txt与hourse_1.txt是上面生成的点云文件。
3.2 将代训点云添加至Area中:
import os
import shutil
def merge_files_and_copy_a_txt(area_dir, source_file):
# 遍历Area_1目录下的所有子目录
for subdir, _, files in os.walk(area_dir):
# 跳过子目录中的Annotations文件夹
if 'Annotations' in subdir:
continue
# 找到子目录中的第一个.txt文件
txt_files = [file for file in files if file.endswith('.txt')]
if txt_files:
# 假设只处理找到的第一个.txt文件
txt_file_path = os.path.join(subdir, txt_files[0])
annotations_dir = os.path.join(subdir, 'Annotations')
annotations_a_txt = os.path.join(annotations_dir, source_file)
# 读取找到的.txt文件内容
with open(txt_file_path, 'r', encoding='utf-8') as f:
txt_file_content = f.read()
# 读取a_1.txt文件内容(假设a_1.txt文件在当前脚本目录下)
if os.path.exists(source_file):
with open(source_file, 'r', encoding='utf-8') as f:
a_content = f.read()
# 合并内容
merged_content = txt_file_content + '\n' + a_content
# 将合并后的内容写回原来的.txt文件
with open(txt_file_path, 'w', encoding='utf-8') as f:
f.write(merged_content)
# 确保Annotations目录存在
os.makedirs(annotations_dir, exist_ok=True)
# 将a_1.txt文件复制到Annotations目录中
shutil.copy(source_file, annotations_a_txt)
print(f"文件已合并并更新: {txt_file_path}")
print(f"文件已复制到: {annotations_a_txt}")
else:
print(f"未找到{source_file}文件,跳过目录: {subdir}")
# 定义Area_1目录
area_1_dir = 'Area_1'
source_file = 'cat_1.txt'
# 执行批量操作
merge_files_and_copy_a_txt(area_1_dir, source_file)
3.3 删除数据集原有的点云
import os
def remove_common_lines(file1_path, file2_folder_path, exclude_files):
# 读取 file2 文件夹中所有 .txt 文件的内容并存储在集合中,排除指定的文件
file2_lines = set()
for filename in os.listdir(file2_folder_path):
if filename.endswith('.txt') and filename not in exclude_files:
with open(os.path.join(file2_folder_path, filename), 'r', encoding='utf-8') as file2:
file2_lines.update(file2.readlines())
# 读取 file1.txt 的内容并过滤掉 file2 文件夹中所有 .txt 文件中存在的行
with open(file1_path, 'r', encoding='utf-8') as file1:
file1_lines = file1.readlines()
filtered_lines = [line for line in file1_lines if line not in file2_lines]
# 将过滤后的内容写回到 file1.txt 中
with open(file1_path, 'w', encoding='utf-8') as file1:
file1.writelines(filtered_lines)
# 删除没有保留的文件
for filename in os.listdir(file2_folder_path):
if filename.endswith('.txt') and filename not in exclude_files:
os.remove(os.path.join(file2_folder_path, filename))
# 主文件夹路径
area_folder_path = '/home/afan/DeepL/3D/mkdir/Stanford3dDataset_v1.2_Aligned_Version/Area_1'
# 你想保留的 Annotations 文件夹中的文件列表
exclude_files = ['cat_1.txt', 'hourse_1.txt',]
# 遍历主文件夹中的所有子文件夹
for conference_room_folder in os.listdir(area_folder_path):
conference_room_folder_path = os.path.join(area_folder_path, conference_room_folder)
if os.path.isdir(conference_room_folder_path):
# 构建文件和文件夹路径
file1_path = os.path.join(conference_room_folder_path, f'{conference_room_folder}.txt')
file2_folder_path = os.path.join(conference_room_folder_path, 'Annotations')
# 检查文件和文件夹是否存在
if os.path.isfile(file1_path) and os.path.isdir(file2_folder_path):
# 调用函数
remove_common_lines(file1_path, file2_folder_path, exclude_files)
上述两步骤运行后的目录结构为:
 可以看到cat和hourse添加进去了,而confereRoom_1.txt只由Annotations中的两个文件组合而成。
可以看到cat和hourse添加进去了,而confereRoom_1.txt只由Annotations中的两个文件组合而成。















 1865
1865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









