








大型语言模型 (LLMs) 近期因其文本交互能力而受到广泛关注。然而,自然的人类互动通常依赖语音,这促使人们向语音模型转变。一种实现这一目标的直接方法是使用“自动语音识别 (ASR) + LLM + 语音合成 (TTS)”的流水线,即将输入语音转录为文本,经由 LLM 处理后再转换回语音。尽管此方法直观简单,但它存在固有的局限性,如在模式转换过程中信息丢失,以及在三个阶段中累积的误差。为了解决这些问题,语音语言模型 (SpeechLMs) 应运而生。这些端到端模型无需文本转换,直接生成语音,成为一种有前景的替代方案。本综述论文首次全面概述了构建 SpeechLMs 的最新方法,详细介绍了其架构的关键组成部分以及其开发中的各种训练方法。此外,我们系统地考察了 SpeechLMs 的多种能力,分类了对 SpeechLMs 的评估指标,并讨论了该快速发展的领域中的挑战与未来研究方向。
1 引言
大型语言模型(LLMs)在文本生成和自然语言处理任务中展现出显著的能力,成为推动 AI 驱动语言理解和生成的强大基础模型 [Achiam 等, 2023; Dubey 等, 2024a; Zhang 等, 2022b]。它们的成功还推动了其他领域的众多应用,然而,仅依赖文本模式存在明显的局限性。这促使人们发展基于语音的生成模型,使人与模型之间的互动更加自然和直观。引入语音不仅有助于实现实时语音互动,还能通过结合文本和语音信息丰富交流内容 [Nguyen 等, 2023b; Nguyen 等, 2024]。
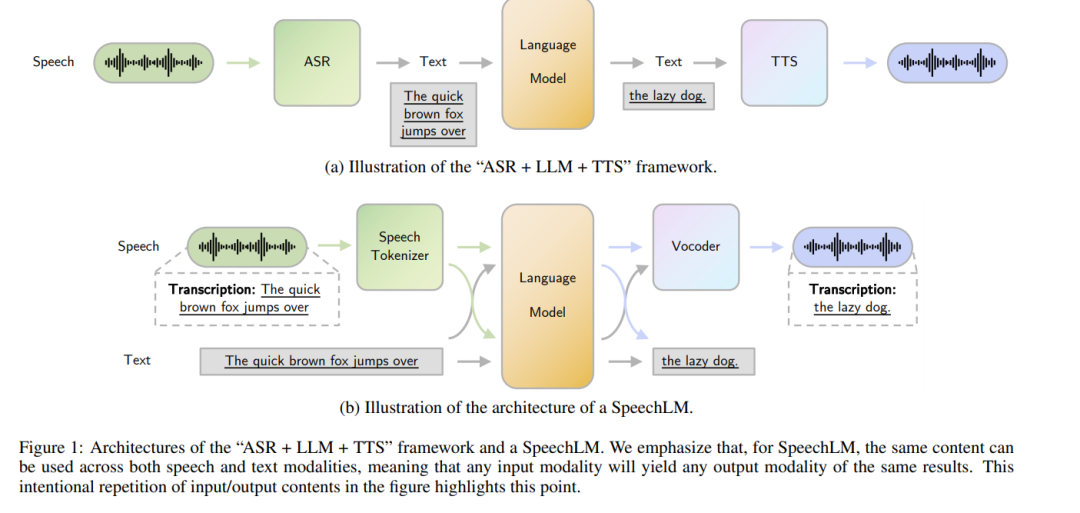
鉴于文本与语音之间存在大量的互信息,对现有的 LLM 进行修改以支持语音互动功能是一项自然的选择。一种直接的方法是采用“自动语音识别(ASR)+ LLM + 语音合成(TTS)”框架(图1a)[Huang 等, 2024]。在该设置中,用户的语音输入首先由 ASR 模块处理,将其转换为文本。然后,LLM 基于该转录文本生成响应,最后由 TTS 模块将该文本响应转换回语音并播放给用户。然而,这种简单方案主要面临以下两个问题:1)信息丢失。语音信号不仅包含语义信息(即语音的意义),还包含副语言信息(例如音调、音色、语调等)。在处理中使用纯文本 LLM 会导致输入语音中的副语言信息完全丢失 [Zhang 等, 2023a]。2)累积误差。此种分阶段的方法容易在整个流程中产生累积误差,特别是在 ASR 到 LLM 阶段 [Fathullah 等, 2024]。特别是在 ASR 模块将语音转换为文本时发生的转录错误会对 LLM 的语言生成性能产生负面影响。
由于 ASR + LLM + TTS 框架的局限性,语音语言模型(SpeechLMs,图1b)被开发出来。与简单的框架不同,SpeechLMs 直接将语音波形编码为离散的 token,从音频中捕获重要特征和信息(第 3.1 节)。尽管单个语音 token 可能不具备词汇层面的语义意义,但它们捕捉到语音话语的语义信息并保留宝贵的副语言信息,从而避免信息丢失。SpeechLMs 自回归地建模这些 token,无需完全依赖文本输入,使其能够利用附加的副语言信息生成更具表现力和细腻的语音(第 3.2 节)。最终,这些生成的 token 被合成回语音(第 3.3 节)。通过直接处理编码后的语音 token,SpeechLMs 有效地减轻了累积误差,因为其训练与语音编码一体化进行,而简单框架中 LLM 的语言建模训练则完全独立于 ASR(语音识别)模块。
除基础对话能力外,SpeechLMs 还具备执行更复杂任务的潜力,如编码特定说话者信息和情感细微差别(图2)。这种能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









