






第2章 GPGPU编程模型
2.1 计算模型
矩阵乘法运算:结果矩阵C中的每一个元素都可以由输入矩阵A行向量,B列向量点积运算得到,每个元素都是独立进行的,没有依赖关系,具有良好的数据并行性。
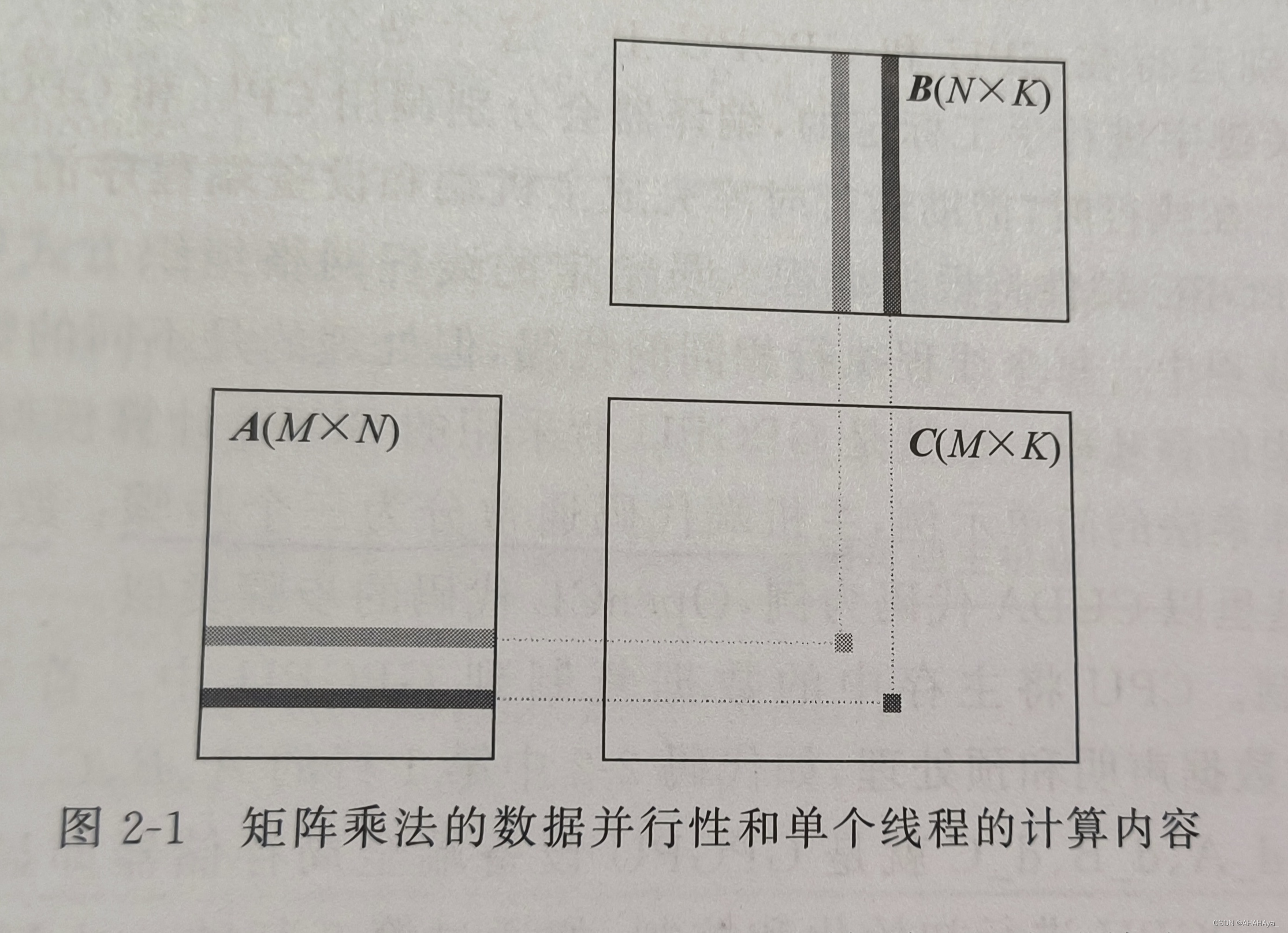
线程:GPGPU中,承担并行计算中每个计算单元任务的计算单元,每个线程在一次计算任务中执行相同的指令(SIMT)。
以下代码是矩阵乘法中单个线程计算内容的伪代码:
//从输入矩阵A和B中读取一部分向量a,b
for(i=0;i<N;i++)
c+=a[i]+b[i];
//将c写回结果矩阵C的对应位置中CUDA:线程网格(thread grid)、线程快(thread block)、线程(thread);
OpenCL:N维网络(NDRange)、工作组(work-group)、工作项(work-item)。
二者一一对应。
以上两种编程模型通常将代码分为主机端代码和设备端代码,分别在CPU和GPGPU运行。
以矩阵乘法为例,主机端代码分为三个步骤:
(1)数据复制:CPU将主存中的数据复制到GPGPU中。
float A[M*N],B[N*K],C[M*K];//主存中的数据
float* d_A,* d_B,* d_C;//显存中的数据
int size =M*n*sizeof(float);
cudaMalloc((void**)&d_A,size);
cudaMemcpy(d_A,A,size,cudaMemcpyHostToDevice);
size=N*K*sizeof(float);
cudaMalloc((void**)&d_B,size);//API分配设备端空间
cudaMemcpy(d_B,B,size,cudaMemcpyHostToDevice);//API控制CPU和GPGPU之间的通信,实现数据复制。
size=M*K*sizeof(float);
cudaMalloc((void**)&d_C,size);(2)GPGPU启动:CPU唤醒GPGPU线程进行计算。
unsigned T_size=16;
dim3 gridDim(M/T_size,K/T_size,1);
dim3 blockDim(T_size,T_size,1);
basic_mul<<<gridDim,blockDim>>>(d_A,d_B,d_C);//唤醒响应设备,并将线程组织方式和参数传入GPGPU
cudaDeviceSynchronize();//将CPU和GPGPU进行同步(3)数据写回:GPGPU运算完毕将计算结果写回主机端存储器中。
size=M*K*sizeof(float);
cudaMemcpy(C,d_C,size,cudaMemcpyDeviceToHost);//将设备计算结果d_C写回到主机端存储器并保存在C中
cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);//释放GPGPU设备端存储空间
return 0;
设备端代码通常由多个内核函数组成,内核函数会被分配到每个GPGPU的线程中执行。一个维度为16*16的矩阵乘法计算中,一种自然的方式就是结果矩阵中的一个元素就是一个线程计算,那么需要256个线程并行计算。
理想情况下,CPU启动一次内核函数完成运算。当面对复杂问题时,需要通过多次交互和多次内核函数调用来完成大规模的运算。如下图所示:
 2.2 线程模型
2.2 线程模型
1.线程组织结构
线程网格是最大的线程范围,包含了主机端代码启动内核函数时唤醒的所有线程。线程网格由多个线程块组成,其数量由gridDim参数指定(dim3 gridDim(M/T_size,K/T_size,1);)其中gridDim是一种dim3类型的数据,而dim3数据类型是由CUDA定义的关键字。本质上是一个数组,3个无符号整型字段代表块的维度是三维,当线程块是二维时z设置为1,一维线程块时只需设置为标量值即可。
线程块是线程的集合。同一线程块的线程可以相互通信。线程块的配置参数blockDim也是一个dim3类型数据,代表线程块的形状(dim3 blockDim(T_size,T_size,1);)。
2.应用数据的索引
blockIdx: x,y,z描述该线程块所处线程网格结构中的位置。
threadIdx: x,y,z描述每个线程所处线程块的位置。
如图所示假设有一个包含12个元素的一维数组A,建立3个一维线程块,每个线程块包含4个一维排布的线程。三种索引方式及索引结果见下面代码:
__global__ void kernel1(int* A){
int index = threadIdx.x + blockIdx.x * blockDim.x;
A[Index] = index
}
//kernel1结果:0 1 2 3 4 5 6 7 8 9 10 11
__global__ void kernel1(int* A){
int index = threadIdx.x + blockIdx.x * blockDim.x;
A[Index] = blockIdx.x
}
//kernel1结果:0 0 0 0 1 1 1 1 2 2 2 2
__global__ void kernel1(int* A){
int index = threadIdx.x + blockIdx.x * blockDim.x;
A[Index] = threadIdx.x
}
//kernel1结果:0 1 2 3 0 1 2 3 0 1 2 33.SIMT和SIMD模型对比
SIMT的优势:
- SIMD利用同一条指令在不同数据上执行相同操作,需要数据在空间上是连续的,还需要借助其他指令对数据进行重组和拆分;而SIMT利用不同线程执行同一指令来处理不同数据,通过各个线程独立对数据进行灵活索引,降低空间连续性的需求。
- SIMD往往需要指令显式地对活掩码寄存器进行设置,以控制相应数据是否参与计算;而SIMT往往通过硬件自动对谓词寄存器进行管理。SIMT还允许线程分支,实现多执行路径,在一定程度上间接支持MIMD执行模式。
- SIMD模型在不同并行元素个数往往需要设计不同格式的SIMD指令,造成指令规模的膨胀;而SIMT对线程数原则上没有限制,硬件管理方式也使得SIMT不需要设计新的指令。
2.3 存储模型
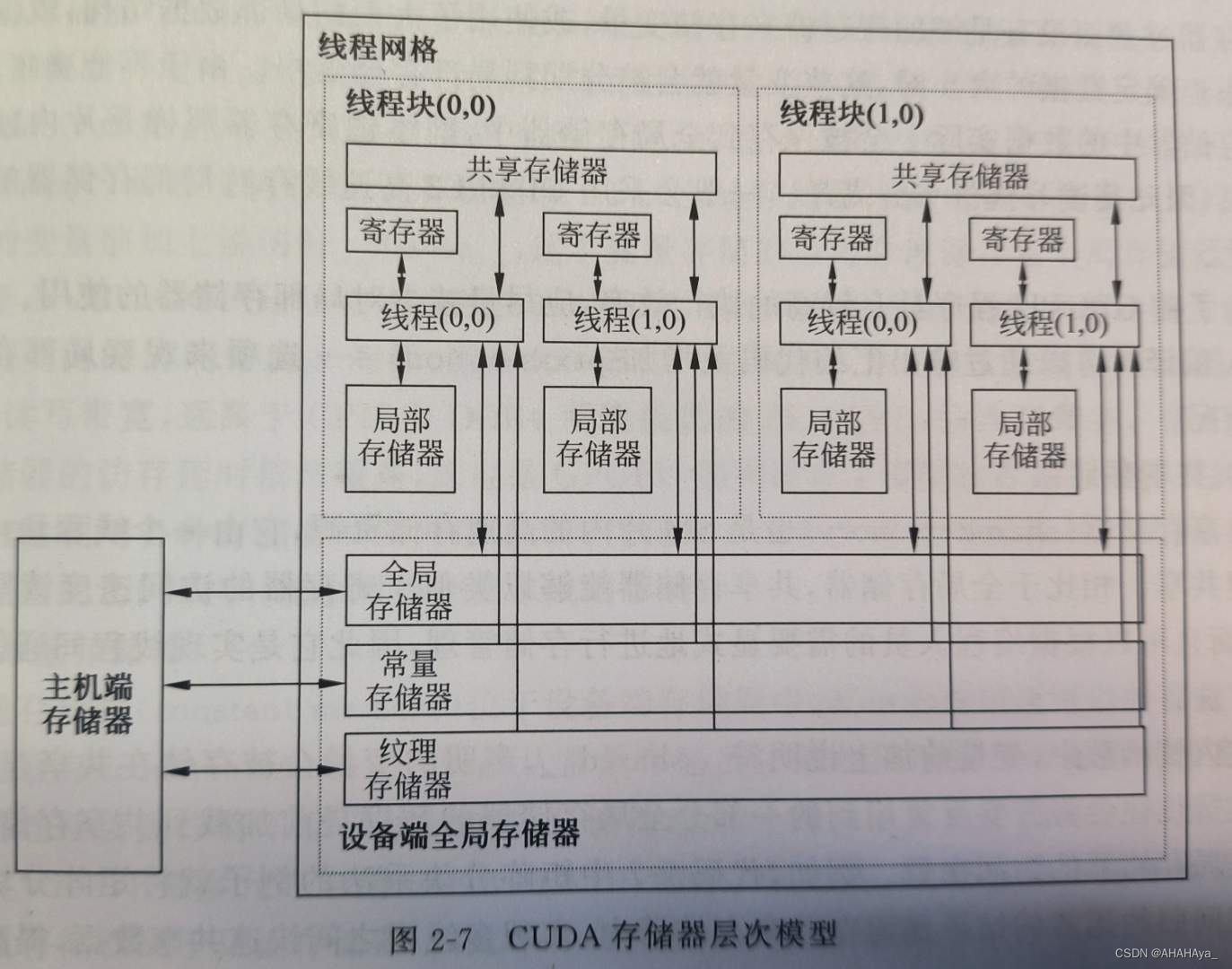
对于CUDA模型,每个线程都拥有自己独立的存储空间,包括寄存器文件和局部存储器,只有本线程才能访问;每个线程块允许内部线程访问共享存储器,在块内进行线程间通信。线程网格内部的所有线程都能访问全局存储器,也可以访问纹理存储器和常量存储器。详细的组织结构和设计见第4章。
2.4 线程同步与通信模型
并行的线程之间需要进行协同和通信的情况:
- 某个任务依赖于另一个任务产生的结果;
- 若干任务的中间结果需要汇集后在进行处理,例如归约操作。
2.4.1 同步机制
- 线程块内线程同步
在CUDA编程模型中,__syncthreads()可用于同一线程块内线程的同步操作,所对应的PTX指令为bar指令。该指令会在其所在程序计数器(PC)位置产生一个同步栅栏,并且要求线程块内所有的线程都到达这一栅栏位置才能继续执行,这可以通过监控线程的PC来实现。
2.存储器同步
通过同步机制保证存储器数据的一致性,GPGPU采取宽松的存储一致性操作,存储栅栏操作使得在同步点处保持一致性。通过以下函数来实现:
(1)__threadfence():线程在该指令之前所有对于存储器的读取或写入对于网格的所有线程都是可见的。
(2)__threadfence()_block():与__threadfence()类似,作用范围为通线程块的线程。
(3)__threadfence()_system():与__threadfence()类似,作用范围是系统内部的所有线程,包括主机端的线程以及其他设备的线程。
3. GPGPU与CPU间的同步
(1)cudaDeviceSynchronize():停止CPU端线程的执行,直到GPGPU端完成之前CUDA的任务,包括内核函数、数据复制等。
(2)cudaThreadSynchronize()_block():与cudaDeviceSynchronize()完全相同,CUDA10.0后被弃用。
(3)cudaStreamynchronize()_system():这个方法接受一个流,将阻止CPU执行直到GPGPU端完成相应流的所有任务,但其他流不受影响。
2.4.2 协作组
协作组:支持将不同粒度和范围内的线程重新构建为一个组,并在这个新的协作组基础上支持同步和通信操作。可以提供线程块内部已有__syncthreads()类似的同步操作,还可以提供更为丰富多样的线程组合及其内部的通信和同步操作,如单个GPGPU上的线程网格或多个GPGPU之间的线程网格。
协作组粒度和线程索引
构建协作组的粒度范围从小到大包括:
(1)线程束内部线程合并分组。调用coalesced_threads()方法,将线程束内活跃的线程重新构建一个协作组。
(2)线程块分块。可以在线程块或已有协作组的基础上,继续划分协作组。通过调用tiled_partition<num>(thread_group)方法,允许从特定的协作组中以num数量的线程为一组,继续进行细分分组。
(3)线程块。通过调用this_thread_block()方法,以线程块为基本单元进行分组。
(4)线程网格分组。通过调用this_grid()方法,将单个线程网格中所有线程分为一组。
(5)多GPGPU线程网格分组。调用this_multi_grid()方法,将运行在多个GPGPU上的所有线程网格内的线程分为一组。
协作组的其他操作(线程范围是按照协作组的一维索引thread_rank()方法来计算的)
(1)线程洗牌操作:
g.shfl(v,i):返回组内线程i的寄存器v中的数据;
g.shfl_up(v,i):先计算本线程索引减去i,并返回该索引的寄存器v的数据;
g.shfl_down(v,i):先计算本线程索引加上i,并返回该索引的寄存器v的数据;
g.shfl_xor(v,i)将交换本线程和以本线程索引加i为索引线程的寄存器v的数据。
(2)本线程索引减去i,并返回该索引的寄存器v的数据表决操作:g.all(p1):如果组内所有线程的谓词寄存器p1都为1,则返回1,否则为0;g.any(p1):如果组内存在线程的谓词寄存器为1,则返回1,否则为0。
(3)匹配操作:Volta架构,g.match_any(value):查找组内所有线程是否含有value值,返回拥有value值的线程掩码;g.match_all(value,pred):查找组内所有线程是否含有value值,如果都包含value值则返回全1的掩码,并将pred置1,否则返回全0的掩码,并将pred置0。
2.4.3 流与事件
流:为了提升资源利用率,可以借助流将数据传输和设备端计算进行异步化,实现一个设备上运行多个内核函数,实现任务级别的并行。
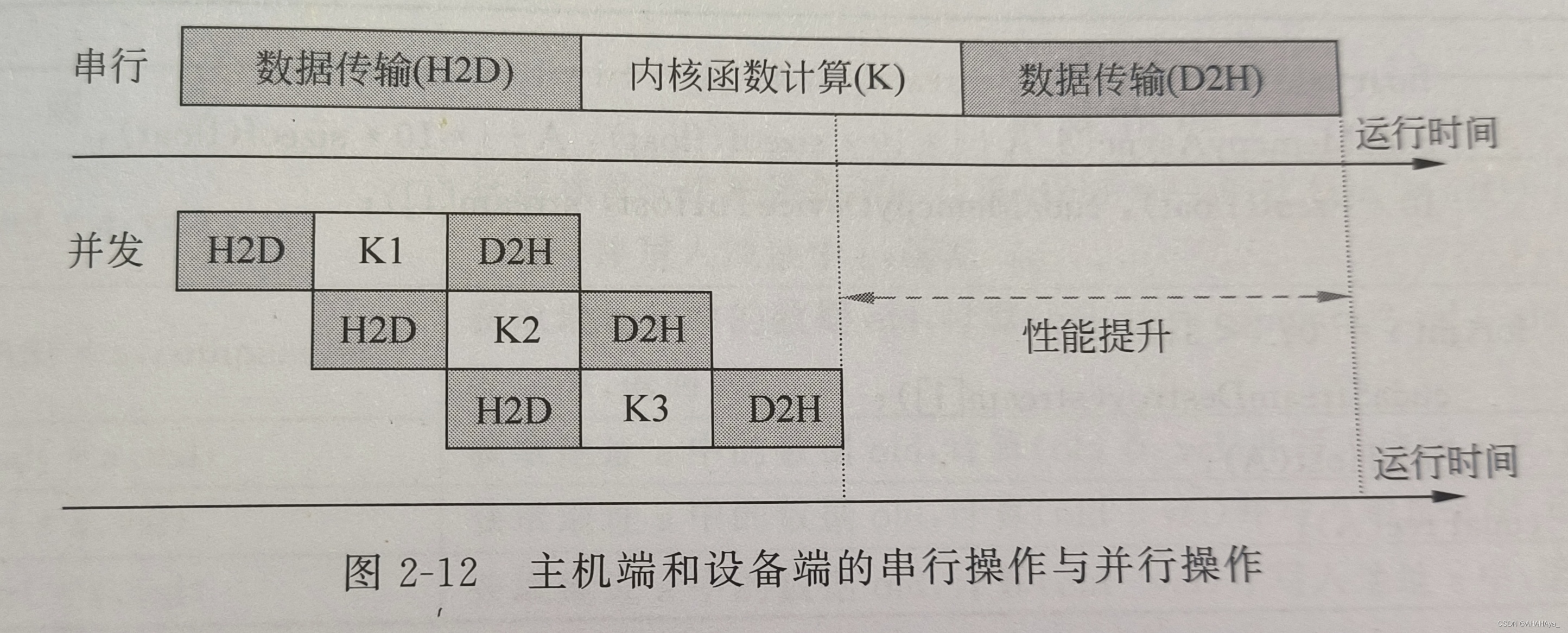
事件:在GPGPU编程模型中,可以声明事件,在流的执行中添加标记点,以更加细致的粒度来检测正在执行的流是否执行到了制定的位置。
事件的主要用途:
(1)事件可以插入不同的流中,用于流之间的操作。在流需要同步的地方插入事件,如在CUDA中可以使用cudaEventRecord()来记录一个事件,之后用cudaStreamWaitEvent()指定某个流必须到事件结束后才能进入GPGPU执行。
(2)可以用于统计时间,在需要测量的函数前后插入cudaEventRecord(event)来记录事件。调用cudaEventElapseTime()查看两个事件之间的时间间隔,从而得到GPGPU运行内核函数的时间。
2.4.4 原子操作



















 4162
4162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









