






原文:https://zhuanlan.zhihu.com/p/721870518

https://openreview.net/forum?id=XkHJo8iXGQ
本文介绍一篇相当有意思的文章,该文章的内容对我们使用指令微调将预训练模型改造为chat模型和下游专业模型相当有指导意义。本文的标题听起来有些唬人,有些标题党,但是这个论点在一定的限定条件下是成立的,笔者归纳为:对充分预训练的模型使用通用指令微调数据集进行全量微调有害。
一. LoRA指令微调并不能学习知识,但它很优秀
试图使用指令微调来为模型灌输知识,其实是一个很常见的做法。然而只要这样做过的人会发现,效果并不会特别好,特别是使用LoRA训练时,模型几乎学不到任何知识。笔者自己的实践是,在使用LoRA对一个Llama3.1本身没有怎么预训练过的内容进行微调时,最终的结果和随机预测基本没有区别(分类和回归任务改造的指令微调数据集)。这提示我们,在使用指令微调对模型进行训练时,首先需要确定模型是否预训练过相关内容,如果没有,最好进行补充性的继续预训练。
如何衡量模型是否通过指令微调学习到了知识?
作者团队通过比较微调后的模型和预训练模型的输出token概率分布来确定模型是否学习到了新知识。也就是说,我们定义指令 ,期望的输出为。那么在第步时,模型输出的token:对应的上下文窗口为。作者团队分析对应的模型概率分布来量化指令微调过程中的知识学习。具体而言,对一个给定的上下文窗口,有预训练模型的概率分布和指令微调模型的概率分布。对于这两个概率分布,我们有三种分析方法:
-
直接衡量两个概率分布的KL散度,KL散度越大说明模型学到了越多的知识。
-
对于 中的 token 我们查看它在 中的概率,该概率越小,说明模型的知识产生的越大的偏离。
-
对于 中的 token 我们查看它在 的排序,如果排序仍为 我们将其归类为未偏移;如果排序为 将其归类为边缘偏移;否则归类为偏移。
作者团队使用了多个指令微调数据集,分别通过全量和LoRA的方式对 Llama2_7B 进行训练,并且查看了模型在以上三个标准下的表现。
作者团队使用了多个指令微调数据集,分别通过全量和LoRA的方式对Llama2_7B进行训练,并且查看了模型在以上三个标准下的表现。
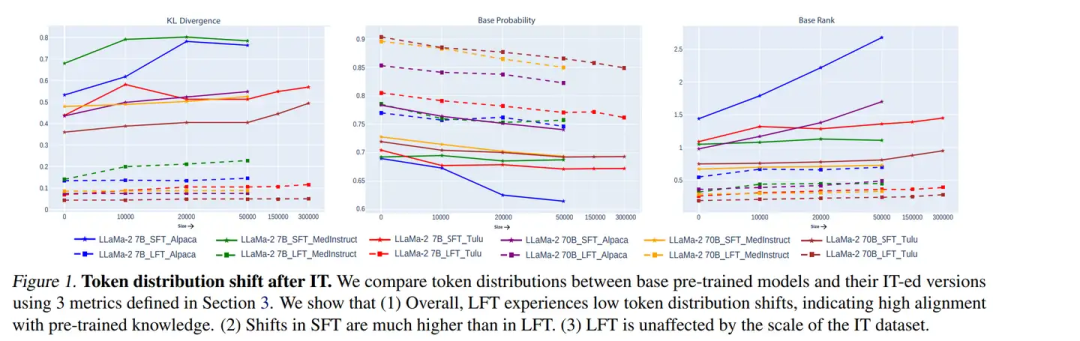
图一:指令微调后模型概率分布的变化,图中LFT指LoRA训练,SFT指全量训练。
结论一:LoRA仅能够让模型学会输出的格式,完全无法获取新知识,同时增大数据集的规模对LoRA无效。
从图一中我们可以发现,通过LoRA训练后,模型的概率分布偏移的并不大。模型仅在前百分之五的概率分布中有比较大的KL散度发散,而在余下的概率分布中几乎保持不变,并且与全量训练相比,LoRA训练的KL散度偏移接近于0。这说明LoRA仅仅做到了学会输出的格式,而做不到学会具体的知识。体现在loss上我们可以发现,使用LoRA训练时模型收敛的非常快,然而在快速收敛之后loss保持平稳,无法进行进一步的下降。
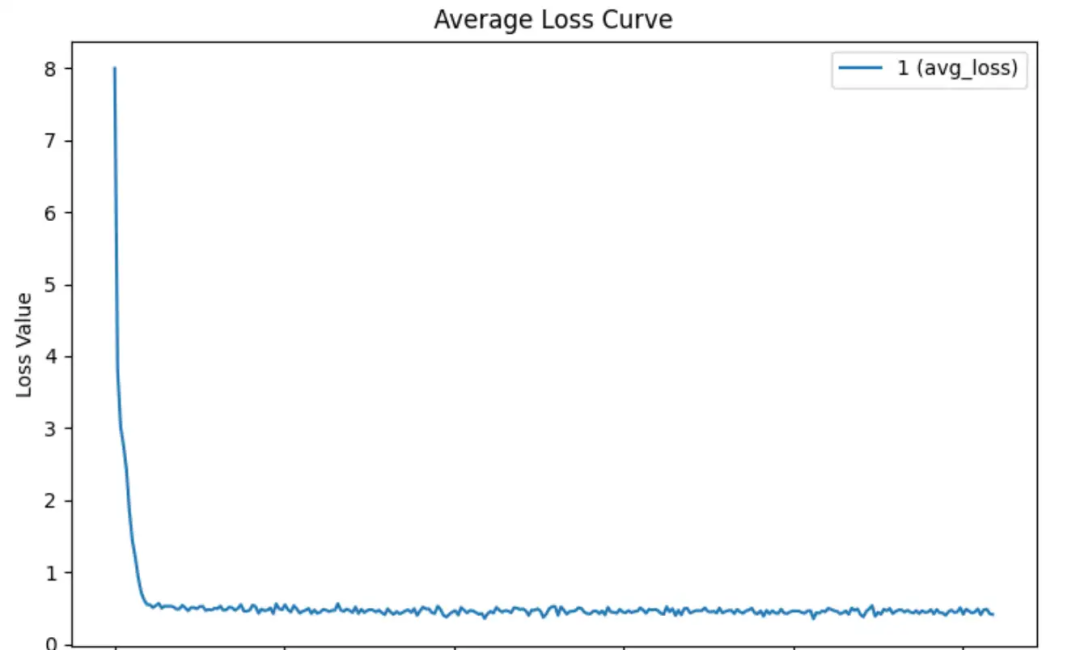
图二:LoRA无法学会新知识的一个例子,快速收敛后loss无法下降。
在这种情况下,增加数据集的规模对模型是无效的。现在许多研究将下游训练的指令微调数据集扩大到百万级的规模,这种做法并不能进一步提高模型的性能。即使将数据集的规模扩大52倍;扩大326倍,也没有作用。在图三中可以发现,扩大数据集规模后LoRA训练的模型在五个维度上的表现都没有得到增强。

图三:扩大数据集的规模对LoRA无效,途中实线为大数据集的结果,虚线为小数据集的结果。
结论二:即使LoRA并不能让模型学会新的知识,它也比全量微调强。
当然,这个结论有一个前提,那就是模型在相关领域上有充分的预训练。经过充分预训练之后,将模型应用到聊天上,只需要令其学会输出结果的格式。而不需要让其学会新的知识,因为模型能够依靠充足的知识储备来给出正确回答。而新的知识反而会扰乱这种知识储备。
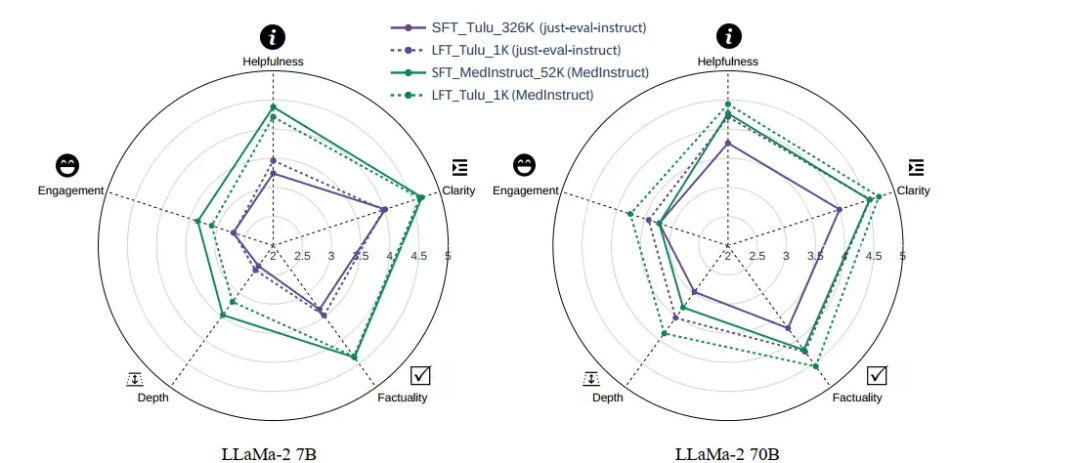
图四:LoRA的性能优于全量微调,图中实线为全量微调,虚线为LoRA训练。可以看到在70B的模型中LoRA微调全面优于全量微调,这得益于70B模型具备更全面的知识储备。
说了这么多,以上内容其实可以用一句话来概括:LoRA指令微调并不能让模型学会新的知识,但是它能比全量训练更好的使模型利用好预训练知识。
二. 全量微调有害
从模式复制说起
指令微调数据集通常都有自己的模式,最典型的例子,去年被很多大模型厂商用来训练自己的模型的非常受欢迎的ShareGPT数据集。由于该数据集是由与ChatGPT对话而来,它完全是ChatGPT的风格。使用ShareGPT训练模型会使模型的风格贴近ChatGPT,甚至认为自己就是ChatGPT。使用有明显风格的数据集训练模型,会让模型进行模式复制。模式复制有两种:
-
模仿指令微调数据集中的用词。
-
模型指令微调数据集中的风格。
我们会认为第一种模式复制是有害的,因为模型在测试场景中使用训练场景中的用词,可能会导致严重的幻觉。毕竟指令微调的目的是让模型更好的利用预训练知识,而不是强行使用指令微调数据集中可能与测试场景无关的词语。
全量微调会学习指令微调数据集中的用词导致严重的幻觉
作者团队研究了全量微调和LoRA微调后模型输出概率分布中的边缘偏移token和偏移token。发现LoRA训练后的偏移token常常为风格token,例如However和Typically。而全量微调中的偏移token包含了指令微调数据集中出现的所有token,也就是说全量微调可能会把指令微调数据集中的任何token利用到测试场景中,即使这些token与测试场景无关。图五给出了一些例子,例如在图五的左边。测试场景的提问为是什么导致了极光,而全量微调的模型大量使用了指令微调数据集中问题为“哪里能看到极光“的样本中的token,这导致了输出的内容偏离了实际的提问,而LoRA训练的模型则正确的回答了该问题。

图五:全量微调会让模型在测试场景中使用指令微调数据集中的相似样本中的token,即使这些token实际上是无关的。这导致了模型答非所问,而LoRA微调的模型正确的回答了问题。
同时,风格模仿在一些时候也是有害的,例如模型的预训练知识并不充足,而指令微调的数据风格为让模型输出足够长的回答,这会导致模型原本能正确回答的问题中出现了幻觉。图六中给出了一些例子,模型在强行输出足够长的回答的情况下,出现了幻觉。而原本简短的回答是正确的。这说明在使用这种指令微调数据集的时候要考虑模型是否经过了充分的预训练。

图六:风格模仿的一些有害实例。















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









