








论文链接:https://arxiv.org/pdf/2407.11385
github链接:https://www.zhengyiluo.com/Omnigrasp-Site/
亮点直击
本文设计了一种灵巧且通用的人形机器人运动表示,这显著提高了样本效率,并使得通过简单而有效的状态和奖励设计来学习抓取成为可能;
本文展示了利用这一运动表示,可以在不使用配对的全身和物体运动数据的情况下,学习合成抓取姿势和轨迹的抓取策略;
本文证明了训练人形控制器的可行性,该控制器能够实现高成功率的抓取物体,遵循复杂轨迹,适应多样的训练对象,并推广到未见过的对象。
本文提出了一种控制虚拟人形抓取物体并沿着物体轨迹移动的方法。由于控制具有灵巧手的人形存在挑战,先前的方法通常使用无身体的手,并且只考虑垂直提升或短轨迹。这种有限的范围限制了它们在动画和模拟所需的物体操作方面的适用性。为了弥补这一差距,本文学习了一个控制器,可以抓取大量(>1200)的物体并将它们携带到随机生成的轨迹上。本文的关键见解是利用一种提供类似人类运动技能并显著加快训练速度的人形运动表示。仅使用简单的奖励、状态和物体表示,本文的方法在不同物体和轨迹上显示出良好的可扩展性。在训练过程中,不需要配对的全身运动和物体轨迹数据集。在测试时,只需要物体网格和抓取、运输所需的轨迹。为了展示本文方法的能力,本文展示了在跟随物体轨迹和推广到未见物体方面的最新成功率。
Omnigrasp:抓取多样化的物体并跟随物体轨迹
为了解决拾取物体并跟随多样化轨迹的挑战性问题,作者首先获取了一个通用的灵巧人形机器人运动表示。利用这一运动表示,本文设计了一个分层强化学习框架,通过预抓取引导的简单状态和奖励设计来实现抓取物体。本文设计的架构如下图2所示。
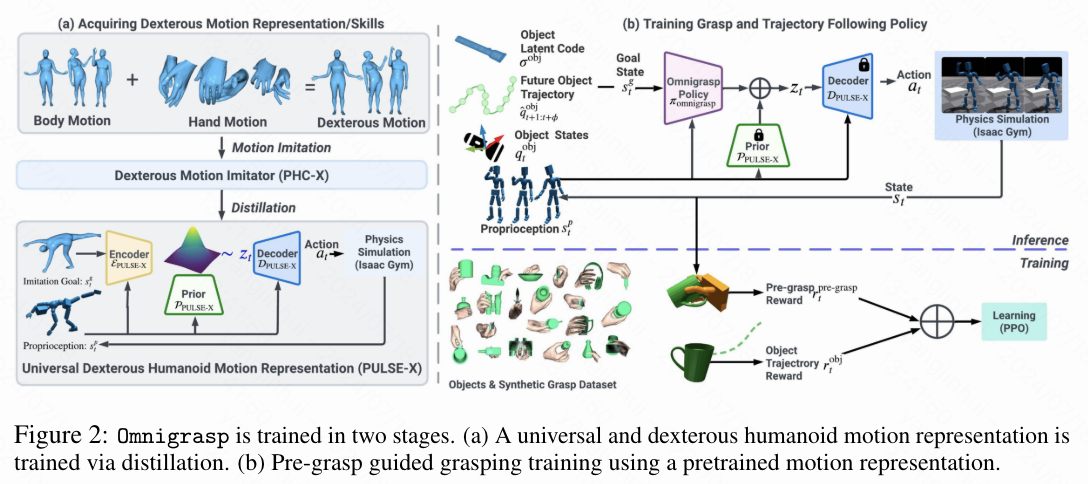
PULSE-X:基于物理的通用灵巧人形机器人运动表示
本文介绍了PULSE-X,它通过增加关节手指扩展了PULSE,使其适用于灵巧的人形机器人。 本文首先训练了一个人形机器人运动模仿器,该模仿器可以扩展到包含手指运动的大规模人类运动数据集。然后,本文使用 variational information bottleneck(类似于VAE)将运动模仿器提炼成一个运动表示。
数据增强。 由于包含手指动作的全身运动数据集很少(例如,AMASS序列中91%的数据不包含手指动作),本文首先通过添加关节手指动作来增强现有序列,并构建一个灵巧的全身运动数据集。类似于BEDLAM中的过程,本文将来自AMASS的全身运动与从GRAB和Re:InterHand中采样的手部动作随机配对,以创建一个灵巧的AMASS数据集。直观上,在这个数据集上进行训练可以提高模仿者的灵巧性以及后续的运动表示。
PHC-X:具有关节手指的人形运动模仿。 受PHC的启发,本文设计了PHC-X(),用于具有关节手指的人形运动模仿。对于额外的手指关节,本文将它们与身体的其他部分类似对待,并发现这种方法足以获得抓取所需的灵巧性。正式地说,使用强化学习(RL)训练的目标状态是:
其中包含本体感受与单帧参考姿态之间的差异。
通过在线蒸馏学习运动表示。 在PULSE中,学习了一个编码器、解码器和先验,以将运动技能压缩到潜在表示中。对于下游任务,冻结的解码器和先验将把潜在编码转换为关节驱动。即,编码器基于当前输入状态计算潜在编码分布。解码器基于潜在编码生成动作(关节驱动)。先验基于本体感受定义高斯分布,替代了VAE中使用的单位高斯分布。先验通过形成残差动作空间增加了潜在空间的表达能力并指导下游任务学习。本文将编码器和先验分布建模为对角高斯分布:
![]()
为了训练模型,本文使用类似于DAgger的在线蒸馏方法,通过在仿真中展开编码器-解码器并查询PHC-X的动作标签。
预抓取引导的物体操作
使用分层强化学习和PULSE-X训练的解码器以及先验,本文的物体操作策略的动作空间变成了潜在运动表示。由于动作空间提供了强大的类似人类运动的先验,本文能够使用简单的状态和奖励设计,并且不需要任何配对的物体和人类运动来学习抓取策略。本文仅使用抓取前的手部姿势(预抓取),无论是通过生成方法还是动作捕捉(MoCap)获得的,来训练本文的策略。
状态。 为了向任务策略提供关于物体和期望物体轨迹的信息,本文将目标状态定义为:
![]()
状态包含参考物体姿态以及接下来帧的参考物体轨迹与当前物体状态之间的差异。是使用标准物体姿态和基点集(BPS)[58]计算的物体形状潜在编码。是当前物体位置与每个手部关节位置之间的差异。最后一项是所有手指的接触力。所有数值都相对于人形机器人的朝向进行归一化。注意,状态不包含全身姿态、抓取引导或相位变量,这使得本文的方法在测试时可以直接应用于未见过的物体和参考轨迹。
动作。 类似于PULSE中的下游任务策略,本文将πOmnigrasp的动作空间形成为相对于先验均值μ的残差动作,并在以下位置计算PD目标:
![]()
其中, 由先验 计算得出。策略 计算 ,而不是直接计算目标 ,并利用 PULSE-X 的潜在运动表示来生成类似人类的动作。
奖励。 虽然本文的策略不需要任何抓取指导或参考身体轨迹作为输入,但本文在奖励中使用了预抓取指导。本文将预抓取 定义为单帧的手部姿势,包括手的平移 和旋转 。PGDM表明,将浮动手初始化到预抓取位置可以帮助策略更好地接近物体并开始操作。由于本文没有像 PGDM 那样将人形机器人初始化为预抓取姿势,本文设计了逐步的预抓取奖励。
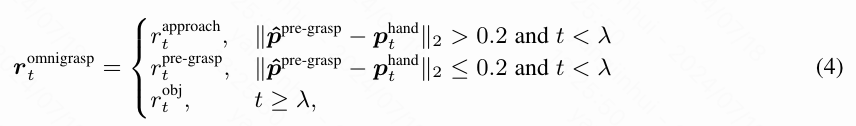
基于时间和物体与手之间的距离。 这里, 表示应进行抓取的帧, 表示手的位置。当物体远离手()时,本文使用类似于点目标奖励的接近奖励 :,鼓励策略接近预抓取。当手足够接近()时,本文使用更精确的手部模仿奖励:,以鼓励手接近预抓取位置。对于只涉及一只手的抓取,本文使用指示变量 来过滤掉离物体太远的手。在时间步 之后,本文仅使用物体轨迹跟随奖励:
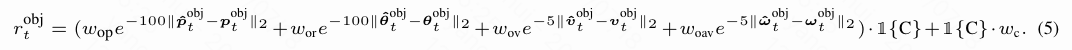
计算当前物体姿态与参考物体姿态之间的差异,这一差异会通过一个指示变量 进行过滤,该变量在物体与人形机器人的手接触时设置为 true。奖励 鼓励人形机器人的手与物体接触。
物体3D轨迹生成器。 由于地面真实物体轨迹的数量有限,这些轨迹要么是通过运动捕捉(MoCap)收集的,要么是由动画师制作的,本文设计了一个3D物体轨迹生成器,可以生成具有不同速度和方向的轨迹。使用这个轨迹生成器,本文的策略可以在没有任何地面真实物体轨迹的情况下进行训练。这种策略提供了更好的潜在物体轨迹覆盖范围,所生成的策略在跟踪未见过的轨迹时取得了更高的成功率(见下表1)。具体来说,本文将PACER中使用的2D轨迹生成器扩展到3D,并创建了本文的轨迹生成器 。给定初始物体姿态 , 可以生成一系列合理的参考物体运动 。本文将z方向的轨迹限制在0.03米到1.8米之间,而xy方向则不受限制。
训练。 训练过程如下算法1所示。运动模仿性能提升的主要来源之一是硬负样本挖掘,即定期评估策略以找到失败的序列进行训练。因此,本文没有使用对象课程,而是使用简单的硬负样本挖掘过程来选择难度较大的对象 进行训练。具体来说,设 为对象 在所有之前运行中失败的次数。选择对象 的概率 为:
其中 是所有对象的总数。

实验
抓取和轨迹跟踪
由于运动效果在视频中呈现得最好.除非另有说明,所有策略均在各自数据集的训练集上进行训练,并且本文在GRAB和OakInk数据集上进行了跨数据集实验。所有实验运行10次并取平均值,因为模拟器每次运行时会由于浮点误差等原因产生略微不同的结果。由于全身模拟人形抓取是一个相对较新的任务,基线数量有限,本文使用Braun等人[6]作为主要比较对象。本文还实现了AMP和PHC作为基线。本文在训练AMP时采用了类似的状态和奖励设计(不使用PULSE-X的潜在空间),并使用了任务和鉴别器奖励权重0.5和0.5。PHC指的是使用模仿器进行抓取,本文直接将真实的运动学身体和手指运动数据输入预训练的模仿器以抓取物体。
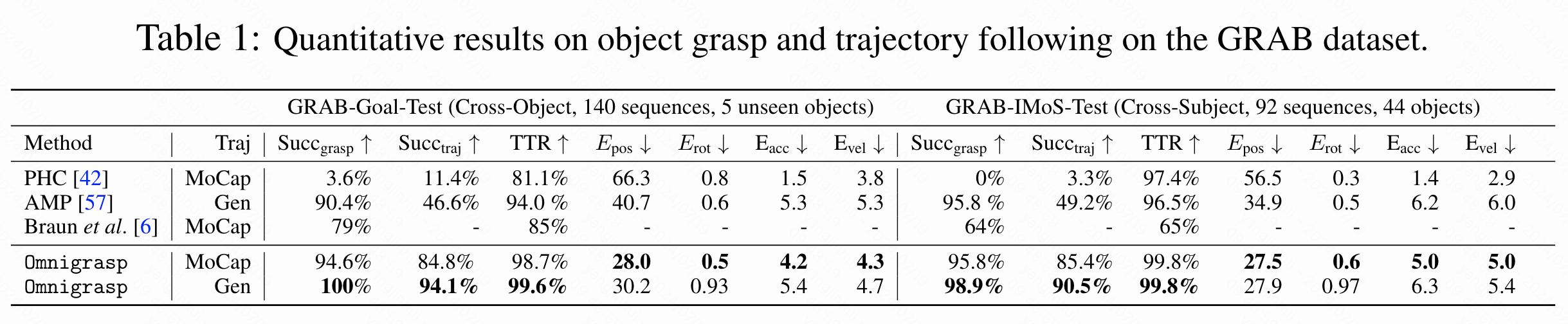
GRAB数据集(50个物体)。 由于Braun等人不使用随机生成的轨迹,为了公平比较,本文在两种不同的设置下训练了Omnigrasp:一种仅使用MoCap物体轨迹进行训练,另一种仅使用合成轨迹进行训练。从表1中可以看出,本文的方法在所有指标上都优于之前的SOTA和基线,尤其是在成功率和轨迹跟踪方面。由于所有方法都基于模拟,本文省略了穿透/脚滑动指标,并报告了精确的轨迹跟踪误差。与Braun等人相比,Omnigrasp在物体提升和轨迹跟踪方面都实现了高成功率。直接使用运动模仿器PHC,即使提供了真实的运动学姿态,成功率也很低,显示出模仿器的误差(平均30毫米)对于精确抓取物体来说太大。MoCap和本文的模拟人形之间的身体形状不匹配也导致了这种误差。AMP导致低轨迹成功率,显示了在动作空间中使用运动先验的重要性。Omnigrasp可以以平均28毫米的误差精确跟踪MoCap轨迹。比较在MoCap轨迹和随机生成的轨迹上进行训练,本文可以看到在生成的轨迹上训练在成功率和位置误差上表现更好,虽然在旋转误差上表现较差。这是因为本文的3D轨迹生成器在物理上合理的3D轨迹上收敛得很好,但在随机生成的旋转和MoCap物体旋转之间存在差距。通过在轨迹生成器上引入更多的旋转变化可以改善这一点。轨迹成功率(Succtraj)和抓取成功率(Succgrasp)之间的差距显示,跟踪完整轨迹比仅仅抓取要困难得多,并且在轨迹跟踪过程中物体可能会掉落。定性结果见下图3。

OakInk数据集(1700个物体)。 在OakInk数据集上,本文将抓取策略扩展到超过1000个物体,并测试对未见过物体的泛化能力。本文还进行了跨数据集实验,在GRAB数据集上训练,并在OakInk数据集上测试。结果如下表3所示。可以看到,1330个物体中有1272个被训练成功抓取,整个提升过程也有很高的成功率。在测试集中本文观察到类似的结果。经过检查,失败的物体通常要么太大,要么太小,导致人形机器人无法建立抓取。大量的物体也对难负样本挖掘过程造成了压力。在GRAB和OakInk上训练的策略显示出最高的成功率,因为在GRAB中有双手预抓取,策略学会了使用双手。使用双手显著提高了一些较大物体的成功率,人形机器人可以用一只手勺起物体并用双手携带。由于OakInk只有单手预抓取,因此无法学习这种策略。令人惊讶的是,仅在GRAB上训练在OakInk上也取得了很高的成功率,抓取了超过1000个物体而无需在该数据集上进行训练,展示了本文抓取策略在未见过物体上的鲁棒性。

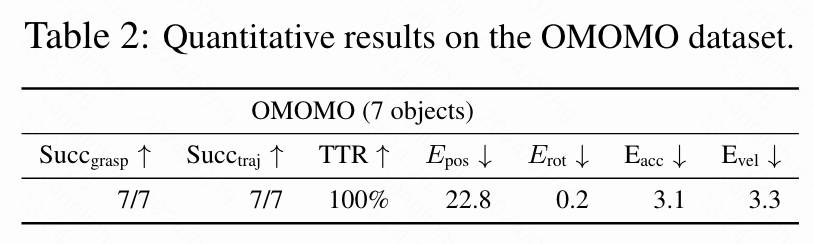
OMOMO数据集(7个物体)。 在OMOMO数据集上,本文训练了一种策略以展示本文的方法能够学习抓取大型物体。如下表2显示,本文的方法能够成功学习抓取所有物体,包括椅子和灯。对于较大的物体,预抓取指导对于引导策略学习双手操作技能至关重要(如上图3所示)。
消融 & 分析
消融实验
在本节中,本文使用GRAB数据集的跨对象分割来研究本文框架中不同组件的影响。结果如下表4所示。
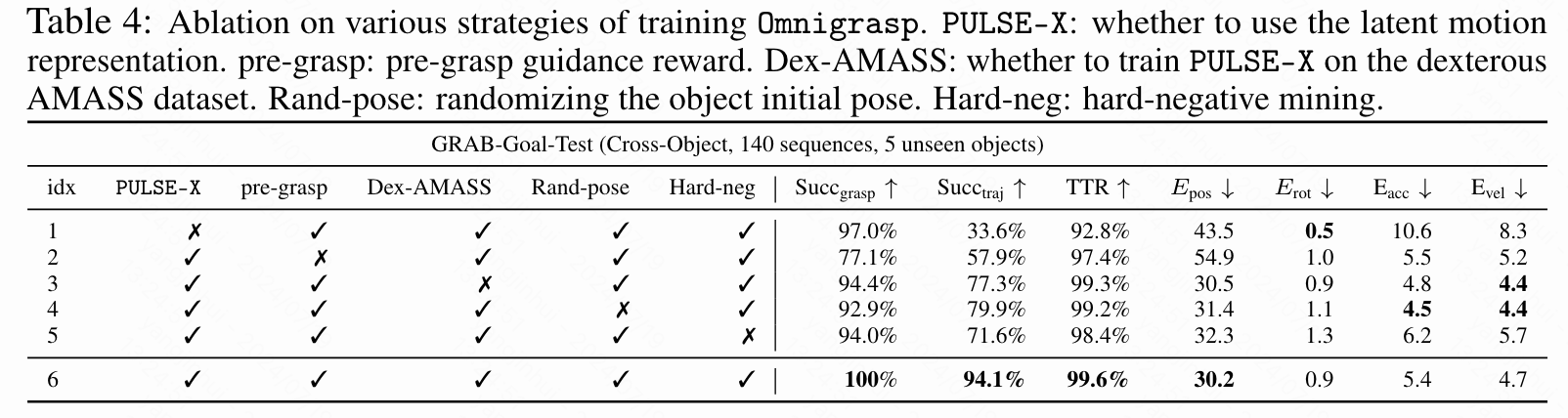
首先,本文比较了在有(第6行)和没有(第1行)PULSE-X动作空间的情况下训练本文的方法。使用相同的奖励和状态设计,可以看出使用通用运动先验显著提高了成功率。经过检查,使用PULSE-X还产生了类似人类的运动,而不使用则导致不自然的运动。
第2行与第6行的对比表明,预抓取指导对于学习稳定的抓取动作至关重要,但没有它,某些物体仍然可以成功抓取。
第3行与第6行的对比显示了灵巧AMASS数据集的重要性:如果没有在包含多样手部运动和全身运动的数据集上进行训练,策略可以学会拾取物体(高抓取成功率),但在轨迹跟踪方面会有困难。这是预期的,因为运动先验可能缺乏“移动时持物”的动作。
第4行和第5行表明,物体位置随机化和硬负挖掘对于学习稳健和成功的策略至关重要。
分析:多样化的抓取策略。 在下图4中,本文可视化了本文方法所使用的抓取策略。可以看到,根据物体的形状,本文的策略在轨迹跟踪过程中使用了多样化的抓取方式。基于轨迹和物体的初始姿态,Omnigrasp为同一物体发现了不同的抓取姿态,这展示了使用模拟和物理定律进行抓取生成的优势。本文还注意到,对于较大的物体,本文的策略会采用双手和非抓握式的运输策略。这种行为是从GRAB中的预抓取学习到的,GRAB使用双手进行物体操作。

限制、总结和未来工作
限制
尽管Omnigrasp展示了控制模拟人形机器人抓取各种物体并在保持物体的同时跟随全方向轨迹的可行性,但仍然存在许多限制。例如,尽管输入和奖励中提供了6自由度(6DoF)输入,系统在旋转误差方面仍需进一步改进。Omnigrasp尚未支持精确的手内操作。轨迹跟随的成功率可以提高,因为物体可能会掉落或无法被拾起。另一个改进领域是实现对物体的特定类型抓取,这可能需要额外的输入,例如所需的接触点和抓取方式。即使在模拟中,实现人类水平的灵巧度仍然具有挑战性。有关失败案例的可视化,请参见补充网站。
结论与未来工作
总之,本文展示了Omnigrasp,这是一种能够抓取超过1200种物体并在保持物体的同时跟随轨迹的人形机器人控制器。它可以推广到类似尺寸的未见过的物体,利用双手技能,并支持拾取较大的物体。本文证明,通过使用预训练的通用人形机器人运动表示,可以通过简单的奖励和状态设计来学习抓取。未来的工作包括提高轨迹跟随的成功率,提高抓取的多样性,并支持更多的物体类别。此外,改进人形机器人运动表示也是一个有前途的方向。虽然本文使用了一个简单但有效的统一运动潜在空间,将手和身体的运动表示分开可能会带来进一步的改进。有效的物体表示也是一个重要的未来方向。如何制定一种不依赖于标准物体姿势且能够推广到基于视觉系统的物体表示,将有助于模型推广到更多物体。
参考文献
[1] Grasping Diverse Objects with Simulated Humanoids















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









