








文章链接:https://arxiv.org/pdf/2407.08683
github链接:https://github.com/TencentARC/SEED-Story
亮点直击
SEED-Story,一种利用多模态大语言模型(MLLM)生成具有丰富叙述性文本和上下文相关图像的多模态故事的新方法。
提出了多模态注意力汇聚机制,以高效生成长度大于训练时使用的序列长度的长故事。
引入了StoryStream,这是一个专门为训练和基准测试多模态故事生成而设计的大规模数据集。

随着图像生成和开放形式文本生成的显著进步,生成交织图像-文本内容的领域变得越来越引人入胜。多模态故事生成,即生成叙述性文本和生动图像交织在一起的内容,已成为一个具有广泛应用的宝贵且实用的任务。然而,这一任务带来了重大挑战,因为它需要理解文本和图像之间复杂的相互作用,并具备生成长序列连贯、上下文相关的文本和视觉效果的能力。
本文提出了SEED-Story,一种利用多模态大语言模型(MLLM)的新方法来生成扩展的多模态故事。本文的模型建立在MLLM强大的理解能力之上,预测文本tokens和视觉tokens,后者随后通过改编的视觉去tokens器处理,以生成具有一致角色和风格的图像。进一步提出多模态注意力汇聚机制,以在高度高效的自回归方式下生成最多25个序列(训练时仅10个序列)的故事。此外,本文还提出了一个名为StoryStream的大规模高分辨率数据集,用于训练本文的模型并在各个方面定量评估多模态故事生成任务。



方法
使用多模态大语言模型进行故事生成
视觉Tokenization和De-tokenization 本文的方法概述如下图2所示。为了有效扩展视觉故事,本文的模型必须理解并生成图像和文本。借鉴最近在统一图像理解和生成的生成性多模态大语言模型(MLLM)方面的进展,研究者们开发了一种多模态故事生成模型。
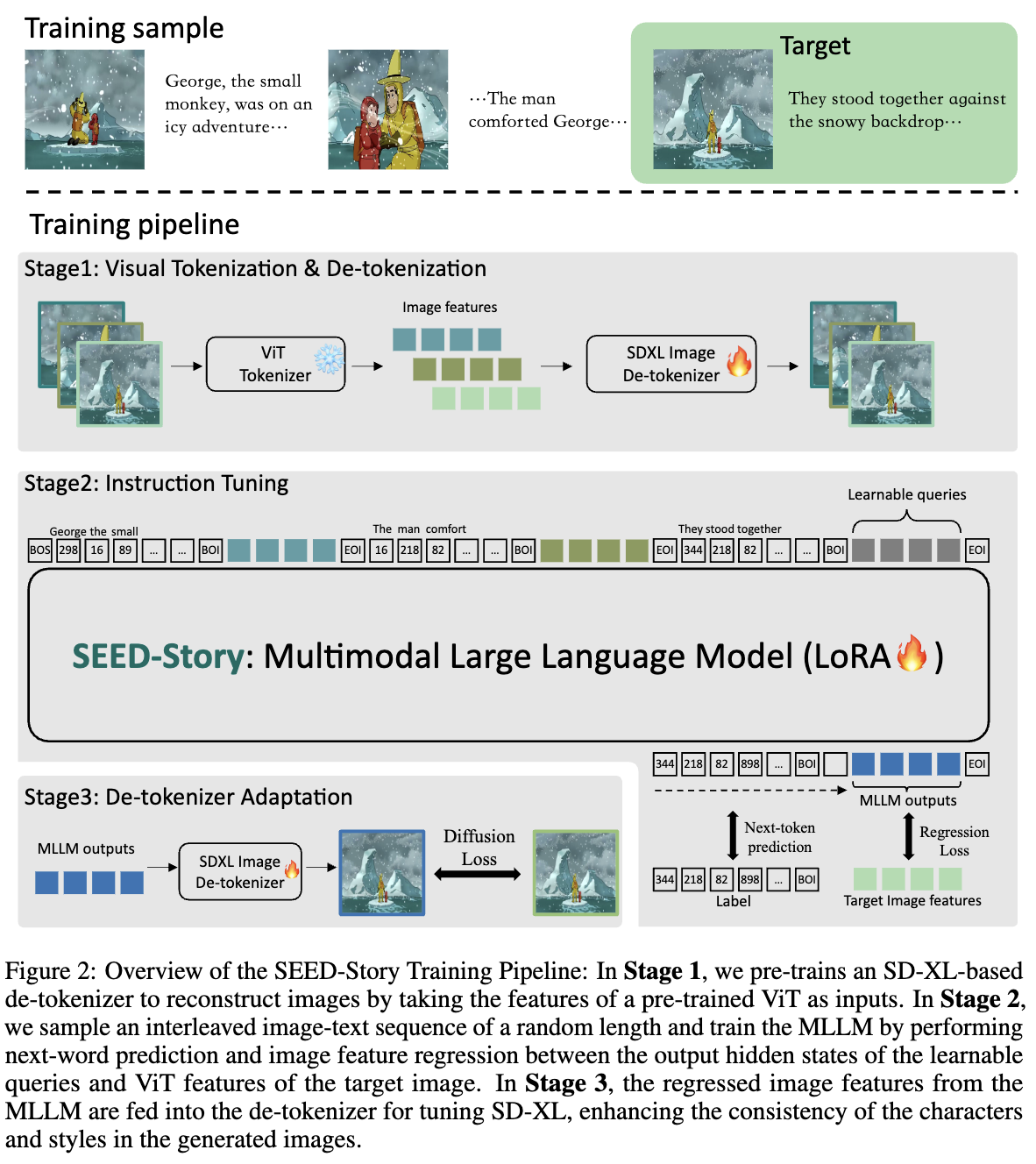
本文的模型使用预训练的Vision Transformer(ViT)作为视觉分词器,并使用预训练的扩散模型作为视觉去分词器,通过使用ViT的特征作为输入来解码图像。具体而言,来自ViT分词器的视觉embeddings被输入到一个可学习模块中,然后作为预训练的SD-XL的U-Net的输入。这个过程用视觉embeddings替代了原始的文本特征。在这一阶段,参数使用开放世界的文本-图像对数据以及故事数据进行优化,以增强模型的编码-解码能力。在这一训练阶段之后,期望视觉分词器和去分词器模块能够在特征空间中尽可能多地保留图像信息。
故事指令调优 在故事生成指令调优过程中,每次迭代随机抽取一个故事数据点的随机长度子集。模型的任务是预测故事文本的下一张图片和下一句句子。在MLLM中,所有图像都使用预训练的ViT分词器转换为图像特征。对于目标文本tokens,进行下一个token预测,并使用交叉熵损失来训练这个离散目标。对于目标图像特征,模型使用一系列可学习的查询作为输入,并连续输出一系列潜在embeddings。然后,计算MLLM输出与目标图像特征之间的余弦相似度损失。在这一阶段,使用LoRA模块微调SEED-Story模型。
去分词器适应 在指令调优之后,SEED-Story MLLM有效地生成了语义正确的故事图像,但缺乏风格一致性和细节。将这个问题归因于MLLM输出的潜在空间与图像特征之间的不对齐。为了解决这个问题,对去分词器进行了风格和纹理对齐的适应。在这个阶段,仅训练SD-XL图像去分词器。在MLLM输出embeddings的条件下,期望SD-XL生成与真实图像在像素级别对齐的图像。去分词器的单独训练有两个主要优势。首先,它避免了LLM与去分词器之间的优化冲突。其次,它节省了内存,使得这一过程可以在内存有限的GPU上执行。
使用多模态注意力汇聚生成长故事
生成长篇视觉故事在教育和娱乐等各种应用中具有巨大的潜力。然而,用多模态大语言模型(MLLM)创建这些故事面临重大挑战。延长、交织故事的数据集不仅稀缺,而且由于其复杂性会阻碍训练过程。为了解决这个问题,采用了“短期训练,长期测试”的方法,在较短的叙事上训练模型,并在推理过程中扩展到较长的生成。
此外,在推理过程中,生成比训练数据显著更长的故事常常导致模型退化,产生质量较低的图像,如下图10第一行所示。这个过程还需要大量的tokens使用来确保连续性和连贯性,这反过来增加了内存和计算需求。
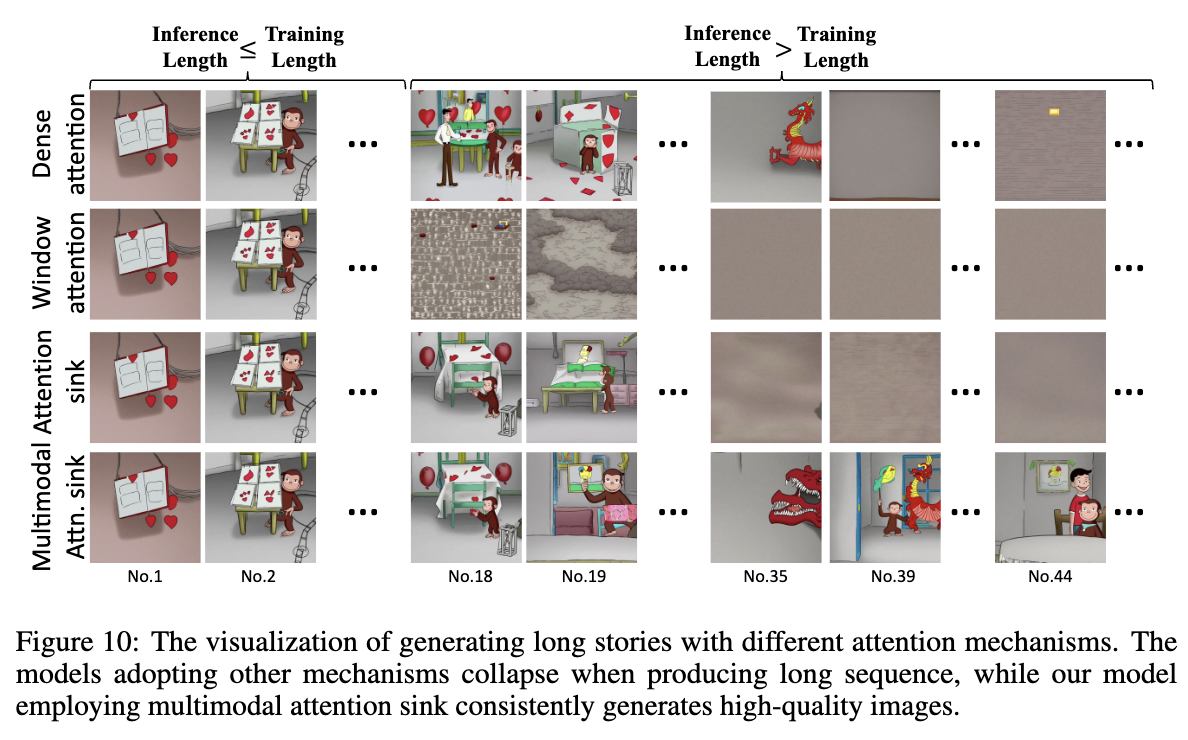
一个简单的解决方案是使用滑动窗口技术,如下图3右(b)所示。然而,这种方法会破坏Key-Value(KV)缓存中的tokens关系,导致生成结果不理想,如StreamingLLM所示。为了克服这一问题,StreamingLLM引入了一种注意力汇聚机制,可以保留初始tokens,从而在不损害质量的情况下高效处理长生成。虽然这种方法在语言模型中有效,但在多模态上下文中的效果减弱,如图3右(c)所示。
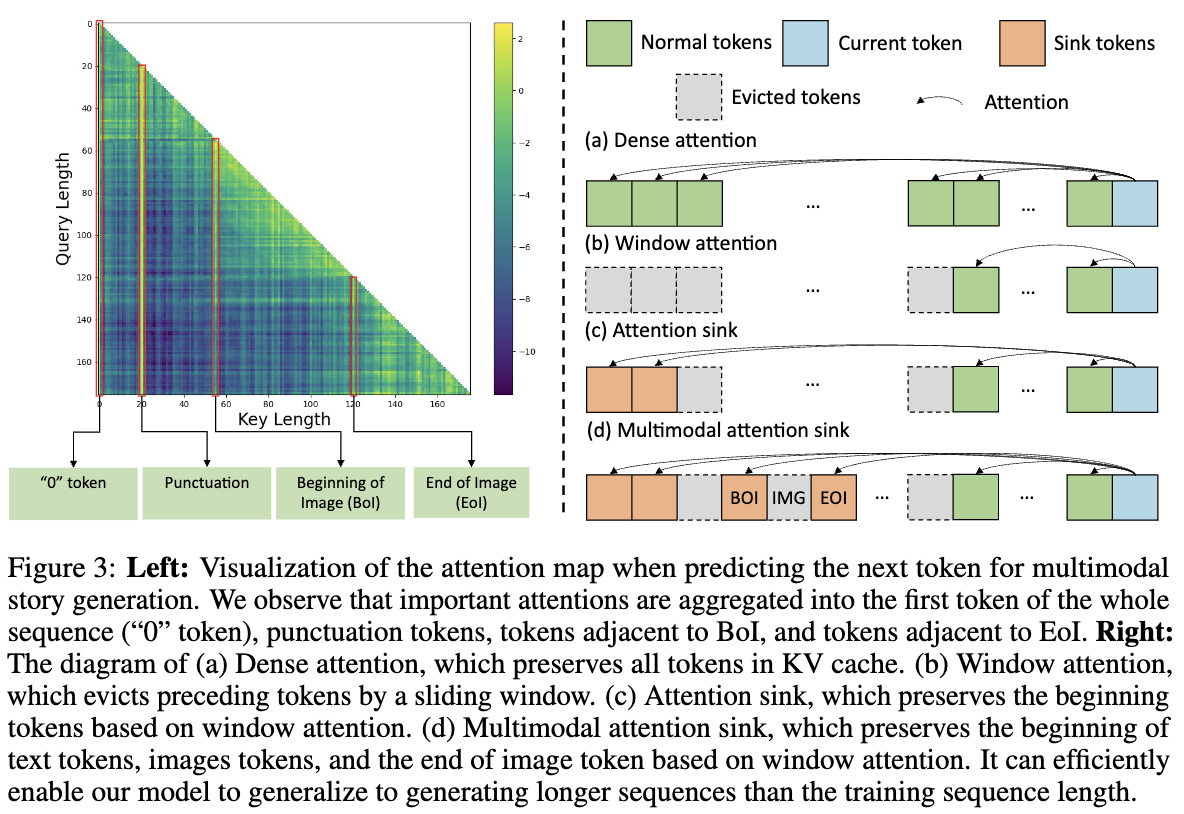
为了增强多模态长生成,重新审视了MLLM的注意力图。在对各种模型和案例进行了大量实验后,分析了不同层和头部的注意力图。分析表明,大多数查询主要集中在四种类型的tokens上:
-
起始tokens
-
标点符号tokens
-
图像开始(BoI)tokens
-
图像结束(EoI)tokens
与仅限语言的模型不同,MLLM对特定的图像tokens,尤其是BoI和EoI附近的图像tokens给予了大量关注,如上图3左所示。
基于这些见解,本文提出了一种新的MLLM扩展生成机制,称为多模态注意力汇聚。在生成过程中,始终保留起始tokens和BoI及EoI相邻的图像tokens。尽管标点符号tokens接收到高关注值,但它们的潜在值规范最小,对最终输出贡献不大,因此不保留它们,如[13]所指出。本文提出的机制使本文的模型能够在保持较低计算负担的同时生成高质量的图像。

实验
故事可视化
以往的故事生成方法主要利用扩散模型,侧重于故事图像的可视化。这些模型以前一张图像和文本作为输入,然后根据当前的文本提示生成下一张图像。为了公平比较,研究者们将本文的模型调整为仅可视化格式。对于StoryGen,也对其进行训练,使其使用前面的图像和文本生成图像。对于LDM,仅提供文本-图像对。视觉结果如下图5所示。

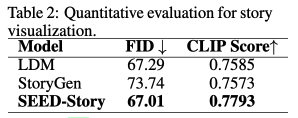
与baseline相比,SEED-Story模型显示了更好的风格和角色一致性以及更高的质量。下表2中进行了定量评估,以展示有效性。
多模态故事生成
为了进行比较分析,现有的多模态故事生成方法相对较少。为了建立比较基准,在数据集上微调了最近开发的MM-interleaved模型。下图6中详细介绍了比较结果。使用FID评估生成图像的视觉质量。
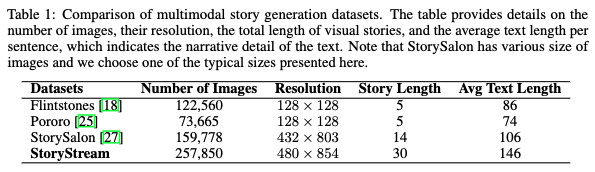
此外,GPT-4V在多个维度上比较并选择MM-interleaved和SEED-Story生成结果中的优选项:风格一致性,评估不同图像之间的风格一致性;故事吸引力,衡量叙述吸引和保持观众兴趣的能力;以及图像-文本一致性,评估图像与其伴随文本之间的对齐和相关性。
为了进行定性展示,展示了SEED-Story如何有效地帮助用户控制故事情节。下图7显示,使用相同的起始图像但不同的初始文本,叙述分支成两个不同的故事情节。

下图8和图9中提供了更多案例,以证明本文多模态长故事生成的能力。SEED-Story可以生成带有引人入胜的情节和生动图像的长序列。


长故事生成
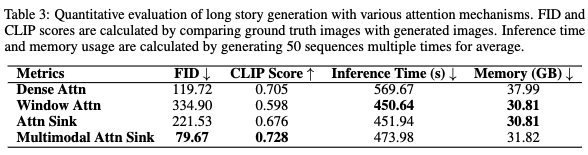
为了验证在长故事生成方面的有效性,本文进行了一项实验,使用SEED-Story模型可视化一个长故事,但采用不同的注意力机制。将数据分成长度为10的故事,以考虑训练效率。将窗口大小设置为与训练长度相同。下图10中的定性结果显示,当推理长度超过训练长度时,窗口注意力迅速崩溃。尽管密集注意力和注意力汇聚方法表现更好,但随着推理序列的加长,仍未能生成有意义的图像。相比之下,多模态注意力汇聚始终生成高质量的图像。

在效率方面,多模态注意力汇聚相较于密集注意力表现出显著的改进,与窗口注意力和普通注意力汇聚相比,仅有适度的时间和内存成本增加。这些额外的成本来自在KV缓存中保留额外的图像tokens。下表3中的定量结果证实了上述结论。
结论
本文介绍了SEED-Story,这是一种利用多模态大语言模型生成具有丰富叙述文本和上下文相关图像的多模态长故事的开创性方法。提出了一种多模态注意力汇聚机制,使本文的模型能够高效地生成长序列。此外,还提出了一个名为StoryStream的高质量数据集,用于有效地训练和基准测试多模态故事生成任务。

参考文献
[1] SEED-Story: Multimodal Long Story Generation with Large Language Model















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









