








文章链接:https://arxiv.org/pdf/2408.11001
项目链接:https://haoningwu3639.github.io/MegaFusion/



亮点直击
提出了一种无需调优的方法——MegaFusion,通过截断与传递策略,以粗到细的方式高效生成百万像素的高质量、高分辨率图像;
结合了膨胀卷积和噪声重新调度技术,进一步优化了预训练扩散模型对高分辨率的适应性;
证明了该方法在潜空间和像素空间扩散模型及其扩展模型中的适用性,使其能够在大约原始计算成本的40%下生成具有多种纵横比的高分辨率图像;
大量实验验证了本文所提方法在效率、图像质量和语义准确性方面的有效性和优越性;
扩散模型凭借其卓越的能力,已成为文本生成图像领域的领先者。然而,由于训练过程中图像分辨率的固定性,导致其在生成高分辨率图像时面临诸如语义不准确和物体复制等挑战。本文介绍了一种名为MegaFusion的全新方法,该方法在无需额外微调或额外适配的情况下,扩展了现有基于扩散的文本生成图像模型,实现了高效的高分辨率生成。具体而言,采用了一种创新的截断与传递策略,跨不同分辨率连接去噪过程,从而以粗到细的方式生成高分辨率图像。此外,通过集成膨胀卷积和噪声重新调度,进一步调整了模型的先验知识,以适应更高的分辨率。MegaFusion的通用性和高效性使其可以普遍应用于潜空间和像素空间的扩散模型以及其他衍生模型。大量实验结果证实,MegaFusion在仅需原始计算成本约40%的情况下,显著提升了现有模型生成百万像素及不同纵横比图像的能力。
方法
本节首先详细阐述了无需调优的MegaFusion方法中的截断与传递策略。接着,结合膨胀卷积和噪声重新调度,以进一步调整模型的先验知识,以实现更高的分辨率。最后,详细说明了该方法在潜空间和像素空间扩散模型及其扩展模型中的应用。
截断与传递策略
为了清晰起见,将以潜空间扩散模型为例来解释本文的方法。对于像素空间的扩散模型,本文的方法可以更直接和方便地应用。
使用预训练的Stable Diffusion Model(SDM)及其配备的去噪器,可以在T次去噪步骤内合成低分辨率的潜在编码,然后通过VAE解码器D解码为图像。在文本提示的条件下,目标是通过在总共T步骤内跨不同分辨率连接生成过程,生成更高分辨率的图像及其对应的潜在编码,其中。
鉴于我们的方法本质上是无需调优的,因此重点关注推理阶段。从通过T1步骤去噪进行低分辨率生成开始。

其中 ,
是预先计算的系数, 表示从标准高斯分布中采样的噪声。随后,在第 步,我们截断生成过程,并计算近似的干净潜在编码 ,该编码作为多分辨率连接的关键元素:
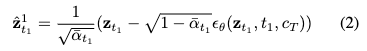
在这里, 随后被解码为图像 ,并使用非参数上采样器 上采样为更高分辨率的相对干净的图像 ,其表示为:
![]()
然后,经过上采样的图像 通过VAE编码器 被重新编码为潜在编码 ,并在当前步骤 添加噪声,以传递生成过程。
![]()
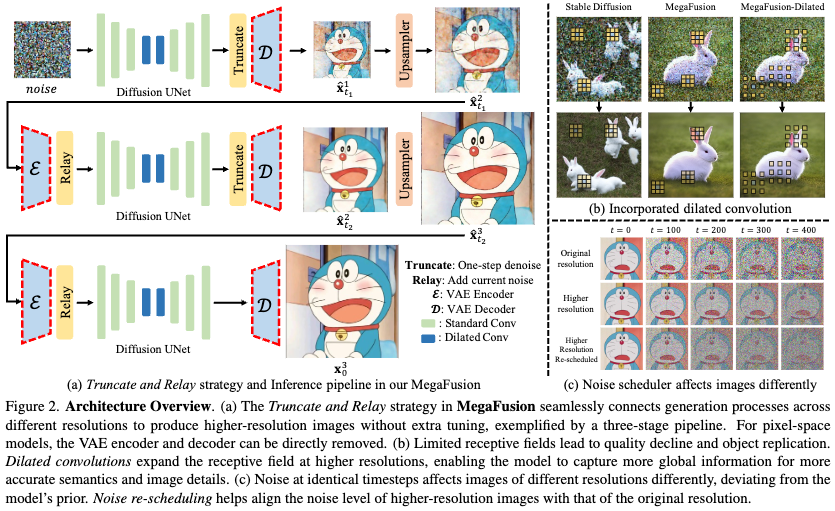
生成过程继续在更高分辨率下进行,通过重新利用方程1进行 步的去噪,依次遍历 。随后,截断与传递操作可以在步骤 处进行。如下图2(a)所示,这一迭代过程重复多次,直到生成高分辨率的潜在编码 ,然后可以解码为对应的高分辨率图像 ,达到百万像素的分辨率。
MegaFusion++
基于截断与传递策略的MegaFusion,可以进一步与现有技术,如膨胀卷积和噪声重新调度,进行正交结合,以使模型的先验知识适应更高的分辨率。
膨胀卷积。扩散模型生成的高分辨率图像中的模糊性和语义偏差可能归因于固定分辨率数据上训练的UNet层的受限感受野,这些层缺乏全面的全局信息。例如,如前面图2(b)所示,现有模型在低分辨率图像上训练时,往往会在不同局部区域内合成多个兔子,这是由于感受野不足,导致语义不准确。受ScaleCrafter的启发,修改了基于UNet的去噪器 的卷积核,结合了具有特定膨胀率 的膨胀卷积。这在无需额外调优的情况下扩大了模型的感受野,使其更好地整合全局信息。
为了简化,省略了通道维度和卷积偏置,专注于权重参数的修改,以将标准卷积分解为膨胀卷积。给定特征图 和卷积核,标准卷积可以表示为:。相比之下,相应的膨胀卷积,膨胀率为 ,可以表示为:。其中,、 和 分别表示特征图和卷积核内的空间位置。
但并不将所有卷积替换为膨胀卷积,这可能导致质量急剧下降,而是选择性地将此修改应用于UNet的中间层。
其背后的见解是:希望在瓶颈处扩大感受野以聚合全局信息,同时在更高分辨率下保留原有先验,采样附近特征以增强细节。
噪声重新调度。类似于在简单扩散和传递扩散中的发现,观察到相同的噪声水平在不同分辨率下对图像的影响不同,如前面图2(c)所示,这导致在相同时间步长下不同的信噪比 (SNR)。
根据之前工作的SNR定义:
考虑到一个低分辨率图像 和一个高分辨率图像 ,其中 且 ,如果将 下采样为 ,则在时间步 的 的SNR(记作)与的SNR(表示为 )将表现出以下关系:
假设在 分辨率下的原始噪声调度器为,则在更高分辨率 下修订后的调度器 应满足:
这得出了以下关系:
将此关系引入到高分辨率噪声调度器的初始化中,得到新的 序列。这个过程称为噪声重新调度,调整噪声水平以更好地适应高分辨率图像生成,从而提高合成质量和保真度。
在其他模型上的进一步应用
像素空间扩散模型。与潜空间模型类似,MegaFusion同样适用于像素空间扩散模型,例如Floyd。主要区别在于直接在像素空间执行截断和传递操作。这意味着方程2、3和4可以调整为如下形式:
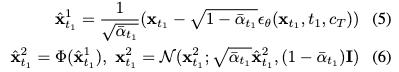
带有额外条件的扩散模型。超出了文本生成图像基础模型的范围,本文的方法论可以扩展到包含额外输入条件的扩散模型,例如ControlNet和 IP-Adapter。这些模型使用文本条件 和图像条件 作为输入。因此,方程1可以被重新制定以适应这两种条件。
![]()
实验
本节首先概述了实验设置。随后,通过定量指标和人工评估对现有模型进行比较。接着,展示了应用我们方法到各种扩散模型的定性结果。最后呈现了消融研究,以验证我们提出的组件的有效性。
实验设置
实现细节。在潜空间(SDM 1.5 和 SDXL)和像素空间(Floyd)中评估文本生成图像扩散模型。除非另有明确说明,所有模型使用DDIM 进行50步的采样。由于SDM是在固定分辨率512 × 512下训练的,选择生成1024 × 1024的高分辨率图像以进行定量比较。
具体而言,在k = 3个分辨率下进行生成:512、768和1024,分别对应的去噪步骤为、和。此外,MegaFusion可以应用于SDM生成2048 × 2048甚至更高分辨率的图像,以进行定性评估。SDXL默认生成1024 × 1024的图像,考虑到计算成本的平衡,舍弃了Refiner模块,采用两阶段生成:1024和2048,分别对应的去噪步骤为和。
另一方面,Floyd是一个三阶段的级联模型,依次将图像从64 × 64上采样到256 × 256,最终生成1024 × 1024的图像。由于计算限制,实验中仅使用Floyd的前两个阶段。第一阶段需要100步DDIM采样( = 80生成64 × 64图像,= 20生成128 × 128图像),第二阶段需要50步( = 40生成256 × 256图像, = 10生成512 × 512图像)。
默认情况下,使用双三次插值作为非参数上采样器 。对于膨胀卷积,设置膨胀率 ,并选择超参数 进行噪声重新调度。所有实验在单个Nvidia RTX A40 GPU上进行,SDM和SDXL使用float16半精度,Floyd使用float32全精度。
评估数据集。在MS-COCO数据集上评估了本文的方法和基准模型,该数据集总共有大约12万张图像,每张图像配有5个字幕。由于高分辨率生成的计算成本,从MS-COCO中随机抽取了1万张图像,并为每张图像分配了固定的字幕作为输入。为了确保比较的一致性,对不同方法中的每张图像使用相同的随机种子,从而消除随机性。对于定性人工评估,使用来自互联网的常用提示作为文本条件,并使用原始代码库提供的条件图像作为IP-Adapter和ControlNet的额外输入。
评估指标。为了评估生成图像的质量,采用了几个广泛使用的指标,包括Fréchet Inception Distance (FID),Kernel Inception Distance (KID) 和CLIP 文本-图像相似度 (CLIP-T)。参考之前的工作,考虑两种类型的FID和KID: (i) 和 ,用于衡量生成图像相对于真实图像的质量和多样性, (ii) 和 ,用于评估在基础训练分辨率下合成样本与高分辨率下样本之间的差异。这些后者的指标反映了模型在不熟悉的分辨率下保持生成能力的能力。
为了评估生成内容的语义准确性,采用MiniGPT-v2 对图像进行字幕生成,并计算这些字幕与原始输入文本之间的几个语言学指标。具体而言,报告了常用的CIDEr、Meteor 和ROUGE 。此外,还详细介绍了在单个A40 GPU上测量的GFlops和推理时间,以进行效率比较。
定量结果
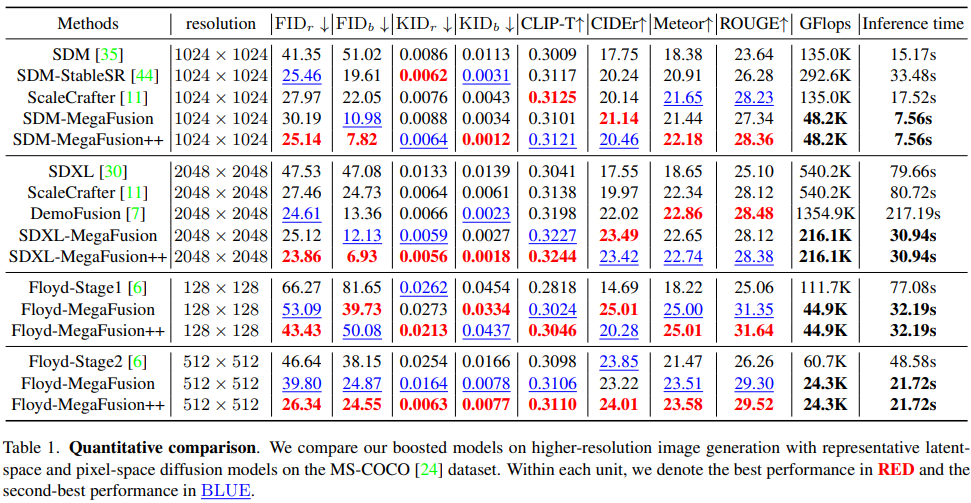
客观指标。在MS-COCO数据集上比较了通过MegaFusion提升的潜空间和像素空间扩散模型的性能与其基线模型。这里,[model-MegaFusion] 指代采用截断和传递策略以跨多分辨率生成图像的模型,而 [model-MegaFusion++] 则表示结合了膨胀卷积和噪声重新调度的高级模型。还与几种现有的最先进方法进行了比较,如带有StableSR的SDM、ScaleCrafter 和DemoFusion,这些方法仅限于特定的潜空间模型且效率较低。
下表1的结果显示,MegaFusion在所有指标上均显著提升,包括图像质量、语义准确性,特别是计算效率。这表明MegaFusion有效地扩展了现有扩散模型的生成能力,使其能够合成具有正确语义和细节的高分辨率图像,同时计算成本仅为原来的40%左右。此外,结合膨胀卷积和噪声重新调度进一步提升了如FID_r、KID_r、CLIP-T和ROUGE等指标的性能,反映了生成多样性和与真实图像及文本条件的一致性有了改进。
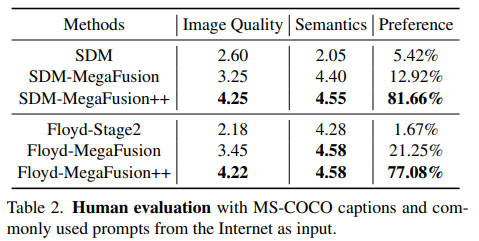
人工评估。为了补充客观分析,进行了一项以人为中心的评估,重点关注图像质量和语义完整性。具体而言,利用相同的文本和随机种子作为输入,通过标准模型(SDM和Floyd)和其MegaFusion增强版本合成高分辨率图像。参与者被要求根据图像质量和语义准确性为输出打分,范围从1到5(分数越高表示越好)。此外,他们还需要从选项中选择他们最喜欢的图像进行偏好评分。
下表2的结果确认了我们的MegaFusion显著提高了高分辨率图像生成的图像质量和语义准确性。此外,高级MegaFusion++显示出更大改进的潜力。这些证据突显了MegaFusion提升预训练模型的能力,使其能够生成质量更高且语义准确的高分辨率图像。
定性结果
文本到图像基础模型的比较。下图3展示了在潜空间和像素空间中高分辨率图像生成的可视化结果。这些结果确认,MegaFusion可以与现有的扩散模型无缝集成,生成具有准确语义的百万像素图像,而以前的基线模型未能做到这一点。此外,结合膨胀卷积和噪声重新调度进一步提升了图像细节。

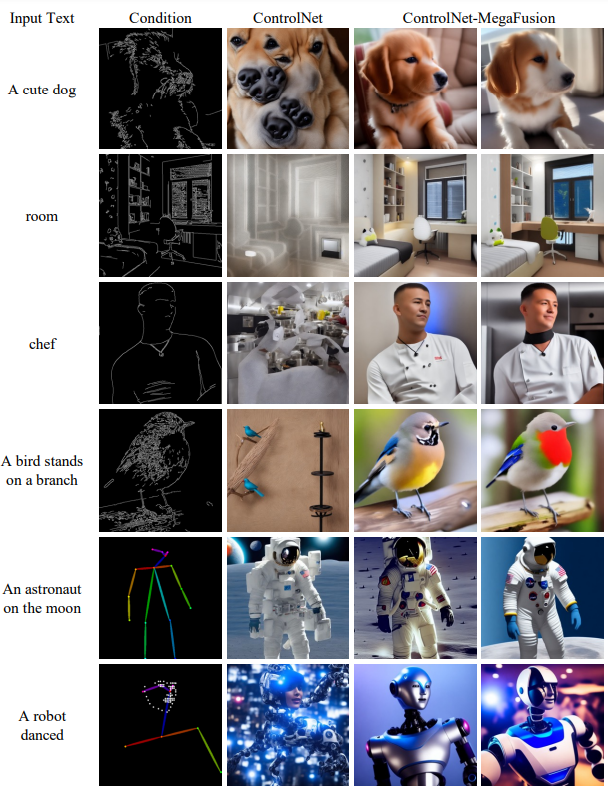
具有额外条件的模型比较。进一步将MegaFusion应用于配有额外输入条件的扩散模型,如IP-Adapter和ControlNet,如下图4所示。MegaFusion展现了普遍适用性,显著扩展了各种扩散模型合成高质量高分辨率图像的能力,这些图像不仅符合输入条件,还保持了语义完整性。

消融研究
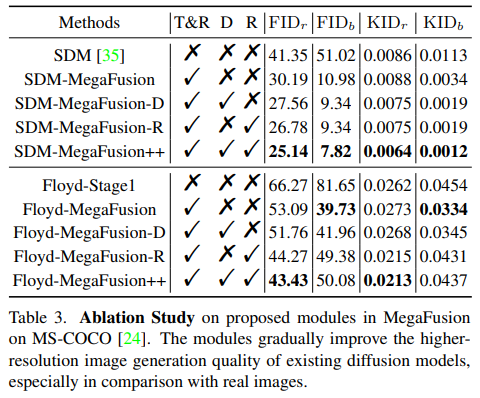
提出的策略与模块。为了评估本文提出的策略和组件的有效性,在潜空间和像素空间中评估了几种模型变体。在这里,“T&R”、“D”和“R”分别表示截断和传递策略、膨胀卷积和噪声重新调度。下表3的结果显示,本文的策略和模块显著提升了基础生成模型如SDM(1024 × 1024)和Floyd(128 × 128)生成内容的质量和多样性,特别是改善了与真实图像的质量和一致性。
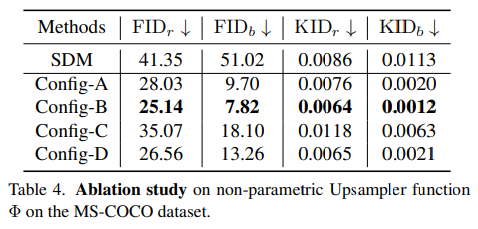
上采样器 。在截断和传递策略中,非参数上采样器在跨不同分辨率的生成过程中起着关键作用。为了确定最佳选择,在MS-COCO数据集上评估了SDM-MegaFusion++模型的几种配置。这些变体包括Config-A(双线性上采样)、Config-B(双三次上采样)、Config-C(双三次上采样配合5 × 5高斯滤波器)和Config-D(双三次上采样配合3 × 3边缘增强内核)。如下表4所示,SDM-MegaFusion++在Config-B配置下在FID和KID指标上表现最佳。因此,将双三次上采样指定为默认选择。
结论
本文介绍了MegaFusion,这是一种无调优的方法,旨在解决合成高分辨率图像所面临的挑战,有效地解决了语义不准确和物体复制的问题。我们的方法采用了一种创新的截断和传递策略,优雅地连接了不同分辨率之间的生成过程,以高效的粗到细方式合成高质量的高分辨率图像,适用于各种长宽比。通过结合正交的膨胀卷积和噪声重新调度,进一步将模型先验适应到更高的分辨率。MegaFusion的多功能性和有效性使其能够普遍适用于潜空间和像素空间的扩散模型及其带有额外条件的扩展。大量实验验证了MegaFusion的优越性,展示了它能够在仅使用原始计算成本约40%的情况下生成高分辨率图像的能力。



参考文献
[1] MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning
更多精彩内容,请关注公众号:AI生成未来
















 4006
4006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









