






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
1.Benchmarking Benchmark Leakage in Large Language Models
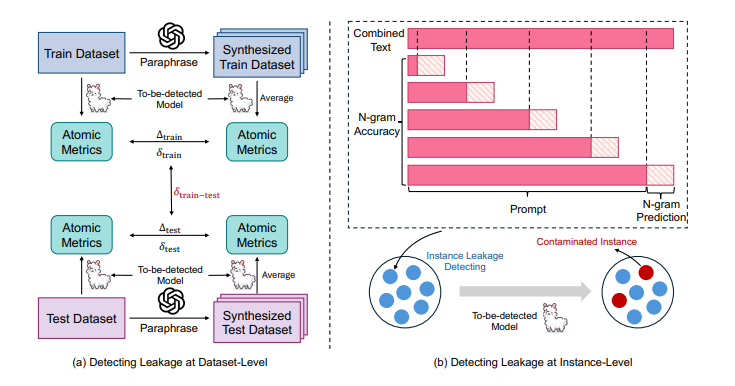
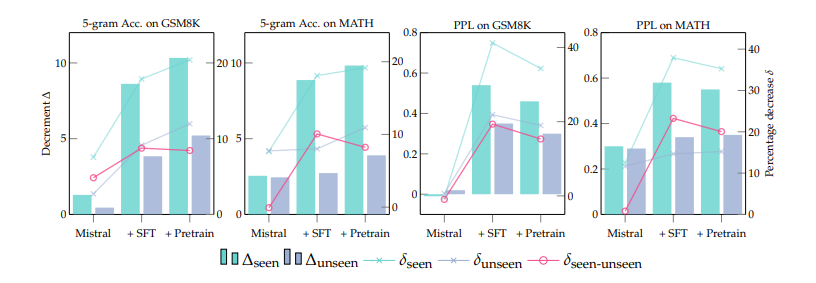
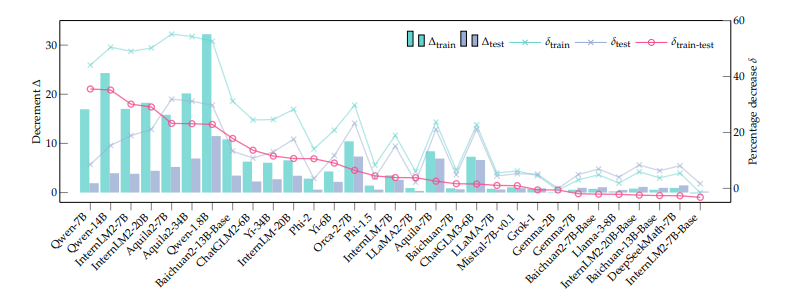
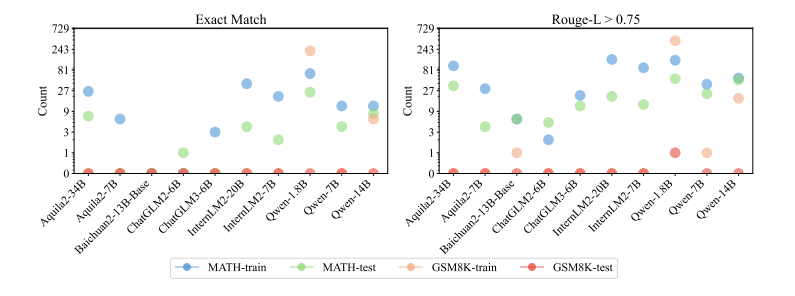
在预训练数据的使用不断扩大的背景下,基准数据集泄漏现象日益突出,这一现象加剧了当前大型语言模型(LLMs)训练过程的不透明性,以及通常情况下未披露的监督数据的纳入。这一问题扭曲了基准效果,促使潜在的不公平比较,阻碍了该领域的健康发展。为了解决这一问题,本文引入了一个检测管道,利用困惑度和N-gram准确度两个简单且可扩展的指标来衡量模型在基准上的预测精度,以识别潜在的数据泄漏。通过在数学推理的背景下分析了31个LLMs,本文揭示了训练甚至测试集滥用的重大实例,导致了潜在的不公平比较。这些发现促使作者提出了几项关于模型文档、基准设置和未来评估的建议。值得注意的是,本文提出了“基准透明度卡片”,以鼓励对基准利用的清晰文档化,促进LLMs的透明度和健康发展。

文章链接:
https://arxiv.org/pdf/2404.18824
2.MANTIS: Interleaved Multi-Image Instruction Tuning
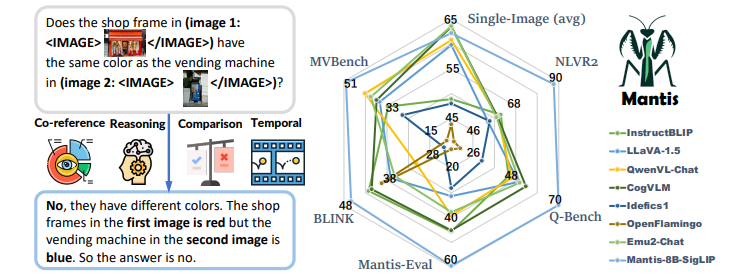
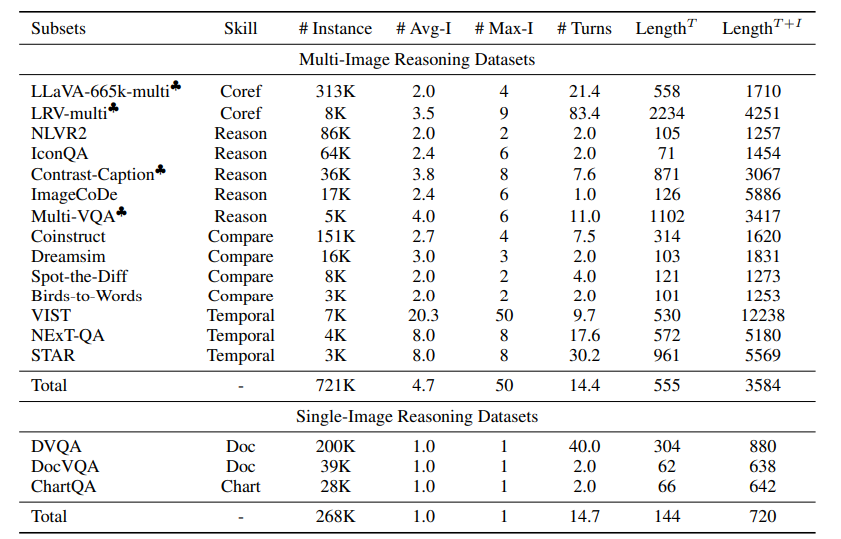
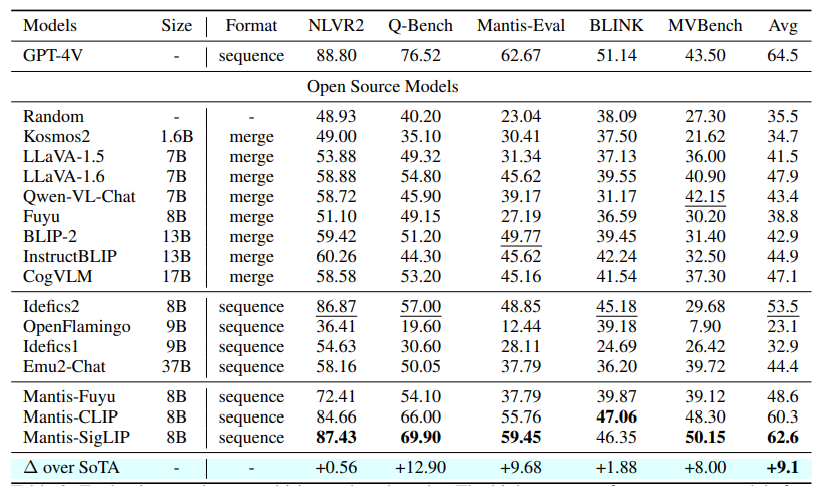
近年来,出现了大量大型多模态模型(LMMs),以有效解决单图像视觉语言任务。然而,它们解决多图像视觉语言任务的能力仍有待提高。现有的多图像LMMs(例如OpenFlamingo、Emu、Idefics等)主要通过在网络上的数亿条噪声干扰的图像文本数据进行预训练来获得其多图像能力,这既不高效也不有效。本文旨在通过使用学术级资源进行指令调整来构建强大的多图像LMMs。因此,精心构建了MANTIS-INSTRUCT,其中包含来自14个多图像数据集的721K个实例。作者设计MANTIS-INSTRUCT以涵盖不同的多图像技能,如共指、推理、比较、时间理解等。作者将MANTIS-INSTRUCT与几个单图像视觉语言数据集结合起来,训练我们的模型MANTIS以处理任何交错的图像文本输入。作者在五个多图像基准测试和八个单图像基准测试中评估了训练后的MANTIS。尽管只需要学术级资源(即在16xA100-40G上进行36小时的训练),MANTIS-8B可以在所有多图像基准测试上达到最先进的性能,并且比现有的最佳多图像LMM Idefics2-8B(预训练于1.4亿交错的图像文本数据)平均提高了9个绝对点。作者观察到,MANTIS在持有和保留的评估基准上表现相当良好,这证明了其泛化能力。值得注意的是,MANTIS在五个基准测试中仅比GPT-4V落后了平均2个绝对点。文中进一步在单图像基准测试上评估了MANTIS,并展示了MANTIS能够保持与CogVLM和Emu2相媲美的强大单图像性能。实验结果特别令人鼓舞,因为它显示了低成本指令调整在构建多图像LMMs方面确实比密集的预训练更为有效。


文章链接:
https://arxiv.org/pdf/2405.01483
3.PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval
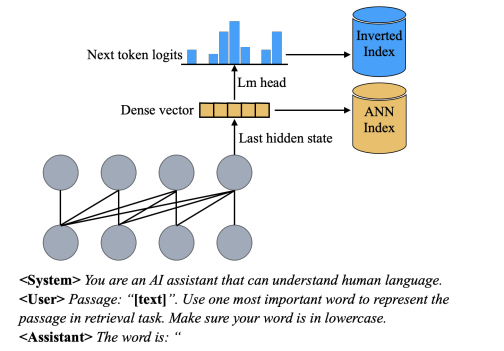
当前,大型语言模型(LLMs)用于零-shot文档排序的方法主要有两种:1)基于提示的重新排序方法,这种方法不需要进一步的训练,但由于相关的计算成本而仅适用于对少量候选文档进行重新排序;2)无监督对比训练的密集检索方法,它可以从整个语料库中检索相关文档,但需要大量配对文本数据进行对比训练。本文提出了PromptReps,它结合了两种方法的优点:无需训练和能够从整个语料库中检索。该方法只需使用提示来引导LLM生成查询和文档表示以实现有效的文档检索。具体来说,提示LLMs使用单个单词来表示给定的文本,然后使用最后一个标记的隐藏状态和与下一个标记的预测相关的对数来构建混合文档检索系统。该检索系统利用LLM提供的密集文本嵌入和稀疏词袋表示。对BEIR零-shot文档检索数据集的实验评估表明,这种简单的基于提示的LLM检索方法在使用较大的LLM时可以实现与最先进的LLM嵌入方法相似或更高的检索效果,而这些方法需要使用大量无监督数据进行训练。

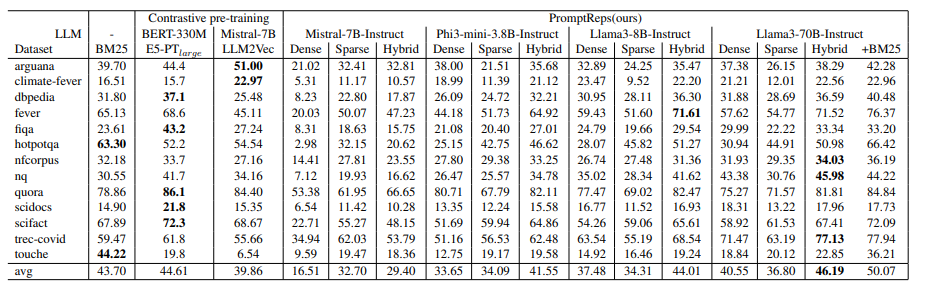
文章链接:
https://arxiv.org/pdf/2404.18424
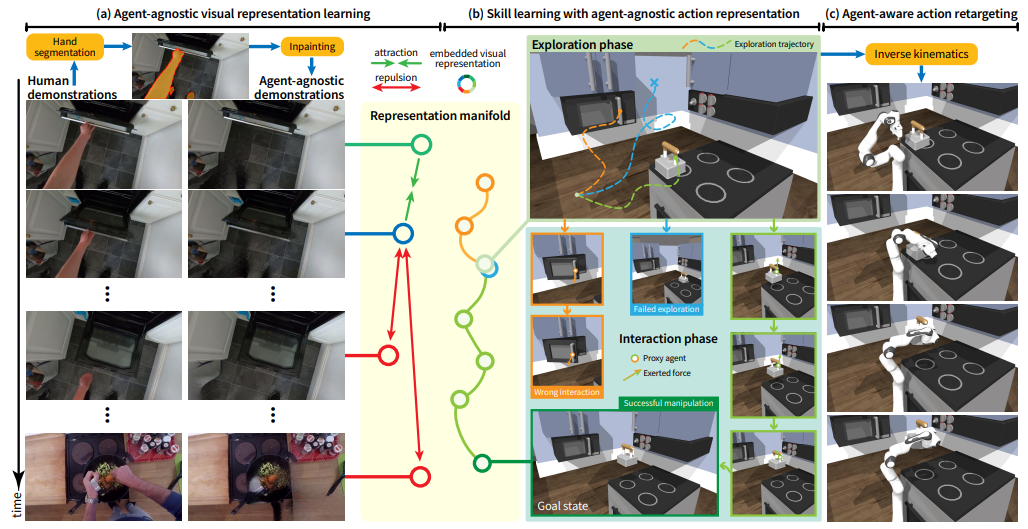
4.Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
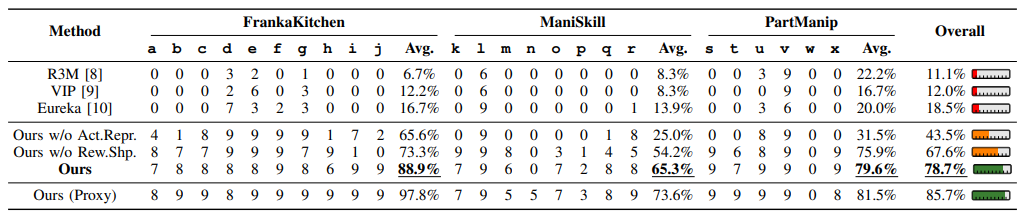
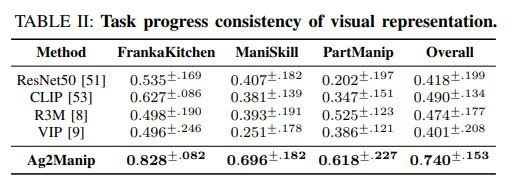
Ag2Manip:通过两项关键创新——源自人类操纵视频的新型与代理无关的视觉表示,其具体实现被模糊化以增强泛化能力;以及将机器人的运动学抽象为通用代理人代理的与代理无关的动作表示——旨在克服这些挑战。Ag2Manip的实证验证覆盖了FrankaKitchen、ManiSkill和PartManip等模拟基准,显示了325%的性能提升,而无需领域特定的演示。消融研究强调了视觉和动作表示对此成功的重要贡献。将评估扩展到真实世界,Ag2Manip将模仿学习的成功率从50%提高到77.5%,展示了其在模拟和实际环境中的有效性和泛化能力。
文章链接:
https://arxiv.org/pdf/2404.17521
5.When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
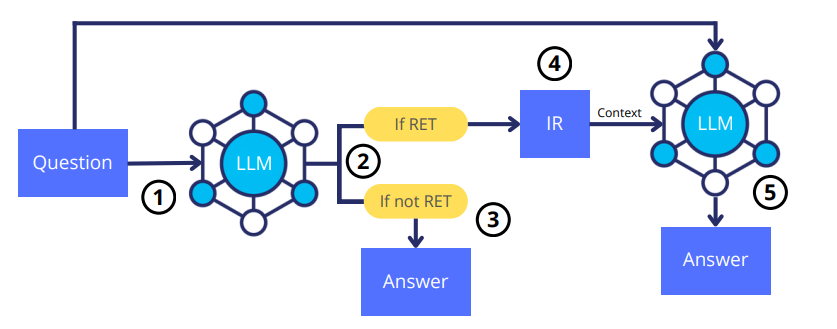
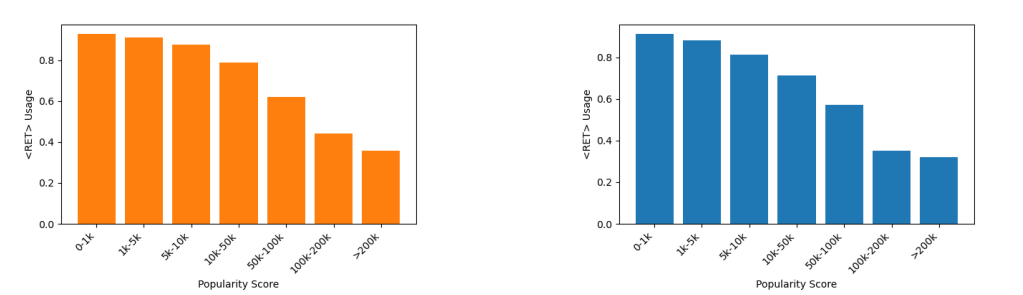
本文展示了大型语言模型(LLMs)如何在需要额外上下文来回答给定问题时,有效地学习使用现成的信息检索(IR)系统。鉴于IR系统的性能,最佳的问答策略并不总是涉及外部信息检索;相反,它通常涉及利用LLM自身的参数化记忆。先前的研究在PopQA数据集中确定了这一现象,在该数据集中,使用LLM的参数化记忆可以有效地回答最受欢迎的问题,而不那么受欢迎的问题则需要使用IR系统。在此基础上,作者提出了一种针对LLMs的定制训练方法,利用现有的开放领域问答数据集。在这种方法中,LLMs在不知道如何回答问题时被训练生成一个特殊的标记⟨RET⟩。作者在PopQA数据集上对自适应检索LLM(ADAPT-LLM)进行了评估,展示了在三种配置下ADAPT-LLM相对于相同LLM的改进:(i)为所有问题检索信息,(ii)始终使用LLM的参数化记忆,以及(iii)使用流行度阈值来决定何时使用检索器。通过分析,作者证明了当ADAPT-LLM确定无法回答问题时能够生成⟨RET⟩标记,表明需要IR,而当它选择仅依赖于自己的参数化记忆时,它能够实现显著高的准确率水平。


文章链接:
https://arxiv.org/pdf/2404.19705
6.StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
在最近基于扩散的生成模型中,尤其是那些包含主题和复杂细节的生成图像序列中,保持一致的内容呈现了一个重大挑战。本文提出了一种新的自注意力计算方式,称为一致性自注意力,显著提高了生成图像之间的一致性,并以零-shot方式增强了流行的预训练基于扩散的文本到图像模型。为了将所提方法扩展到长距离视频生成,进一步引入了一种新颖的语义空间时间运动预测模块,命名为语义运动预测器。它被训练用于在语义空间中估计两个给定图像之间的运动条件。该模块将生成的图像序列转换为具有平滑过渡和一致主题的视频,其稳定性明显优于仅基于潜在空间的模块,特别是在长视频生成的背景下。通过合并这两个新颖的组件,该框架被称为StoryDiffusion,可以描述一个基于文本的故事,并且包含着丰富多样的内容的一致图像或视频。

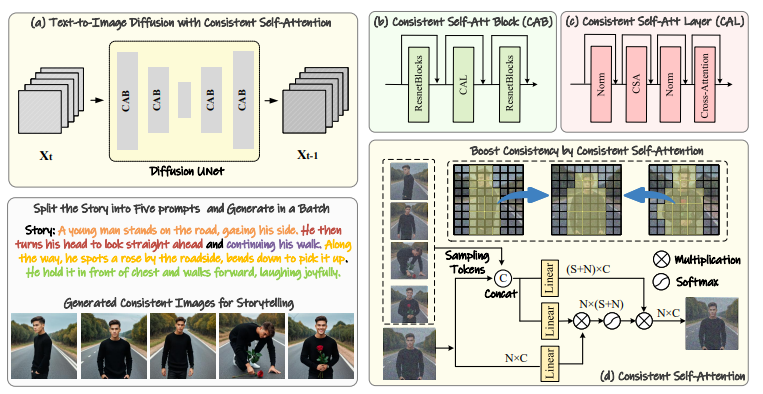

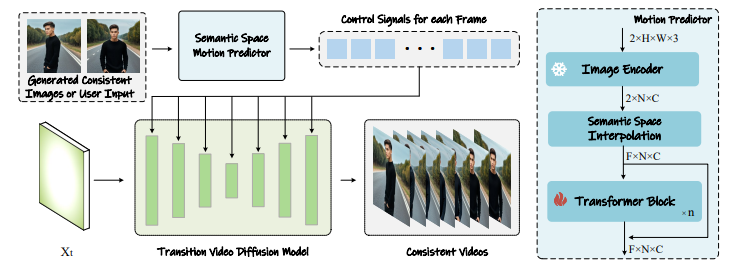

文章链接:
https://arxiv.org/pdf/2405.01434
7.FLAME: Factuality-Aware Alignment for Large Language Models
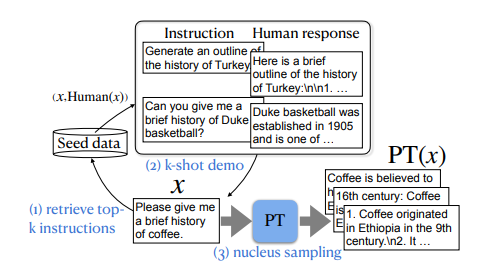
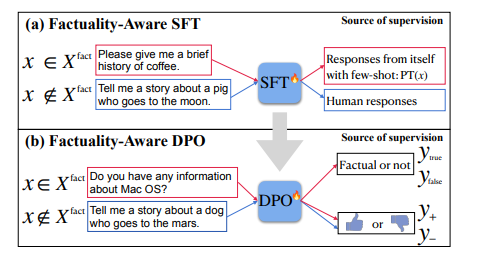
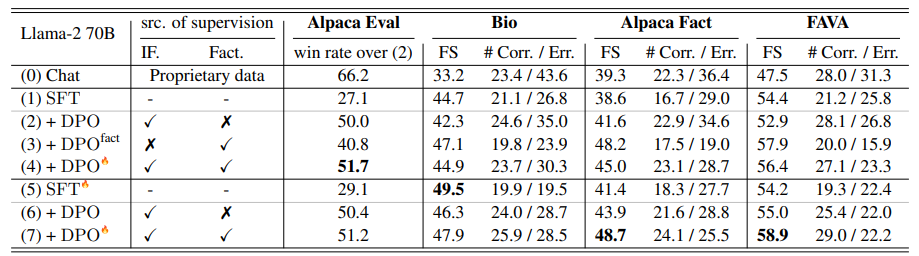
对于预训练的大型语言模型(LLMs),对其进行标准的对齐过程是一种常见的操作,以使其遵循自然语言指令并充当有用的人工智能助手。然而,作者观察到,传统的对齐过程未能提升LLMs的事实准确性,通常会导致更多虚假事实的生成(即幻觉)。本文研究如何使LLMs的对齐过程更具事实性,首先识别导致幻觉的因素,包括两个对齐步骤:监督微调(SFT)和强化学习(RL)。特别是,训练LLMs的新知识或陌生文本可能会促使幻觉。这使得SFT的事实性降低,因为它在可能对LLMs而言是新的人类标记数据上进行训练。此外,标准RL中使用的奖励函数也可能会鼓励幻觉,因为它指导LLMs对各种指令提供更有帮助的响应,通常更喜欢更长、更详细的响应。基于这些观察结果,作者提出了基于事实性感知的对齐(FLAME),包括基于事实性感知的SFT和基于事实性感知的RL,通过直接偏好优化。实验证明,作者提出的基于事实性感知的对齐方法引导LLMs输出更具事实性的响应,同时保持了遵循指令的能力。
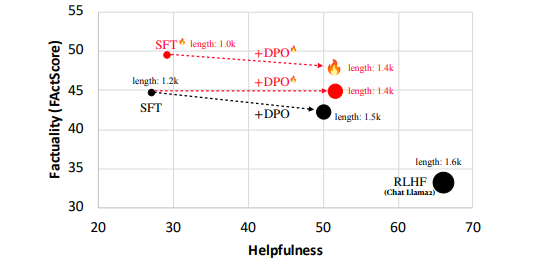
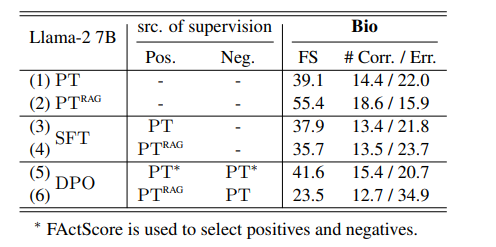

文章链接:
https://arxiv.org/abs/2405.01525
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!















 20
20











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









