






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
MMInstruct: A High-Quality Multi-Modal Instruction Tuning Dataset with Extensive Diversity
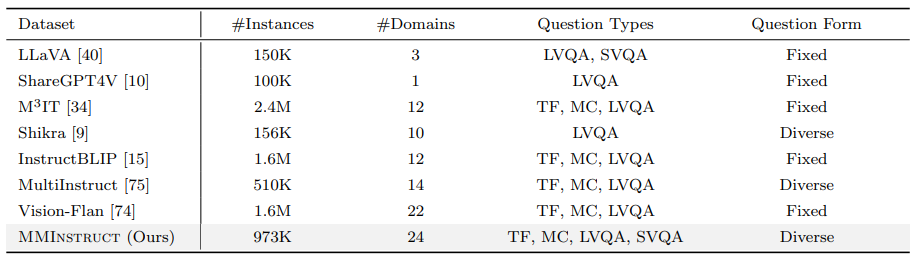
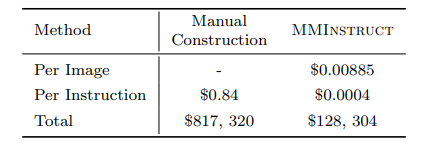
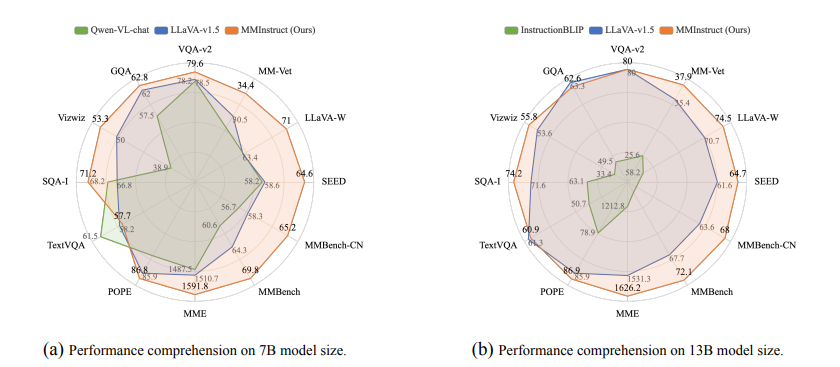
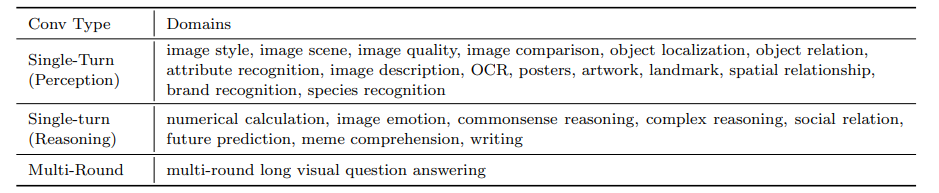
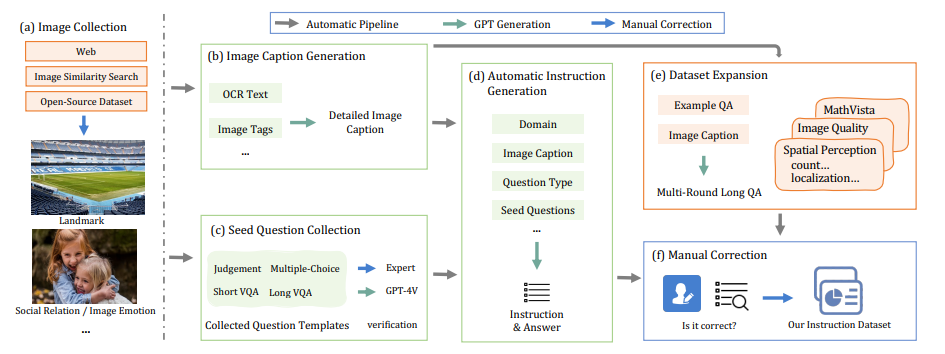
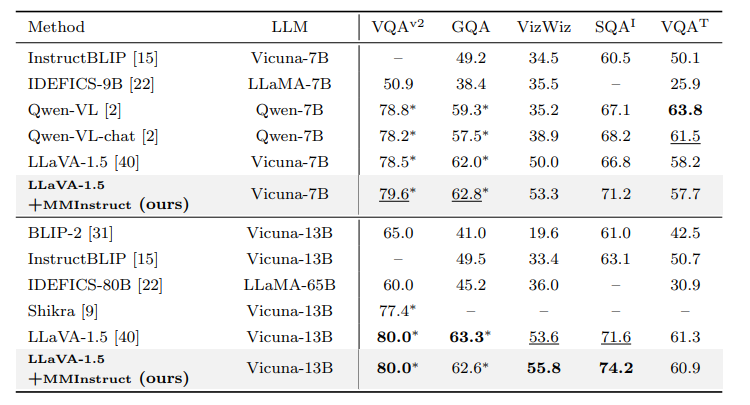
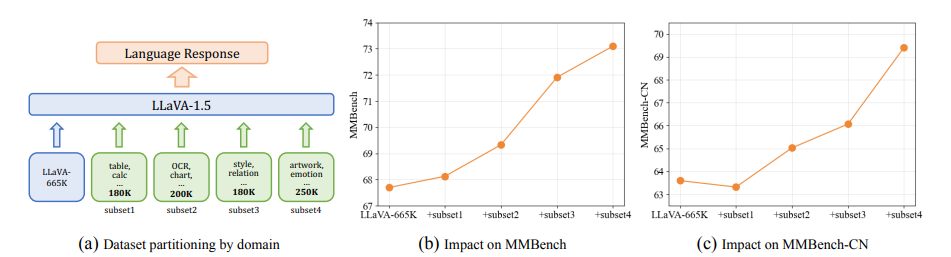
尽管视觉-语言监督微调在提升大型视觉语言模型(VLLMs)性能方面表现出有效性,但现有的视觉指令调整数据集存在一些限制:(1)指令注释的质量:尽管现有的VLLMs展现出强大的性能,但它们生成的指令可能仍然存在不准确的问题,例如幻觉现象。(2)指令和图像的多样性:指令类型的范围有限以及图像数据的多样性不足,可能会影响模型生成更多样化且更接近现实世界场景的输出。为了应对这些挑战,研究者构建了一个高质量、多样化的视觉指令调整数据集MMInstruct,该数据集包含了来自24个领域的973K条指令。数据集中包含四种指令类型:判断、多项选择、长视觉问答和短视觉问答。为了构建MMInstruct,研究者提出了一个指令生成数据引擎,该引擎利用了GPT-4V、GPT-3.5以及手动校正。这一指令生成引擎支持半自动化、低成本且跨领域的指令生成,其成本仅为手动构建的六分之一。通过广泛的实验验证和消融实验,研究表明MMInstruct能够显著提升VLLMs的性能,例如,在MMInstruct上进行微调的模型在12个基准测试中的10个上实现了新的最先进性能。

文章链接:
https://arxiv.org/pdf/2407.15838
02
Answer, Assemble, Ace: Understanding How Transformers Answer Multiple Choice Questions
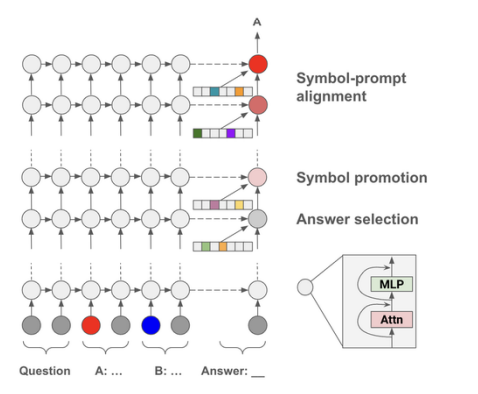
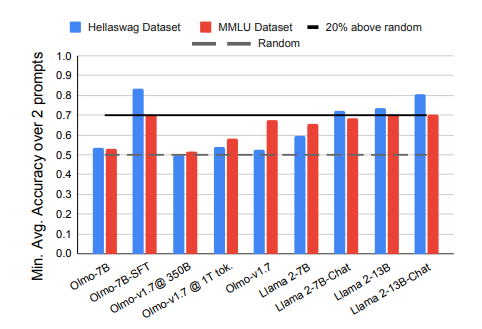
多项选择题回答(MCQA)是主流基准测试中评估高效变换器语言模型的关键能力。然而,最新证据显示,模型的性能可能存在较大差异,尤其是在任务格式略有变化时,例如通过改变答案选项的顺序。在这项研究中,探讨了成功模型在格式化MCQA任务中的表现。研究采用了词汇投影和激活补丁方法来定位编码预测正确答案的关键隐藏状态。研究发现,对特定答案符号的预测在因果上归因于单个中间层,特别是其多头自注意力机制。研究显示,后续层在词汇空间中增加了预测答案符号的概率,并且这种概率的增加与具有独特作用的一组稀疏注意力头有关。此外,研究还揭示了不同模型对不同符号的调整方式存在差异。最后,研究展示了一个合成任务可以分离模型错误来源,以确定模型何时真正掌握了格式化MCQA,并指出在词汇空间中无法区分答案符号是那些无法执行格式化MCQA任务模型的一个特征。
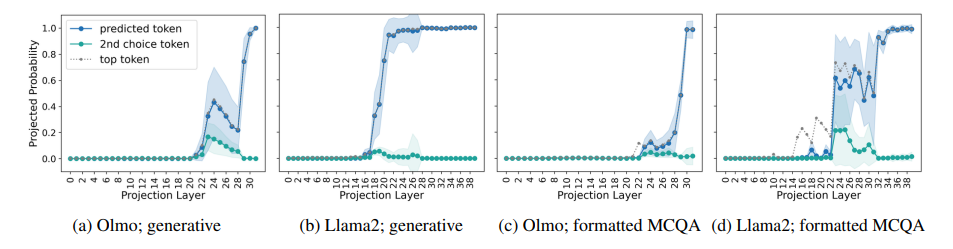
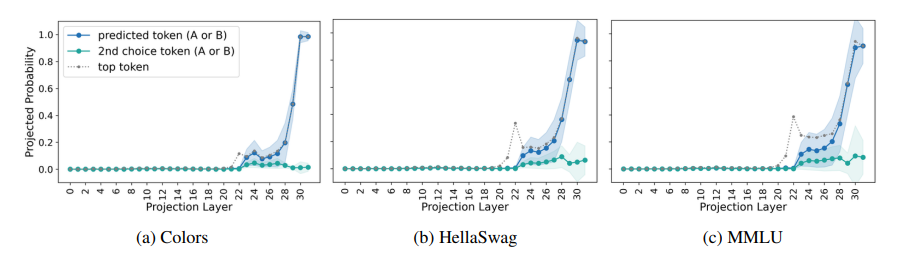
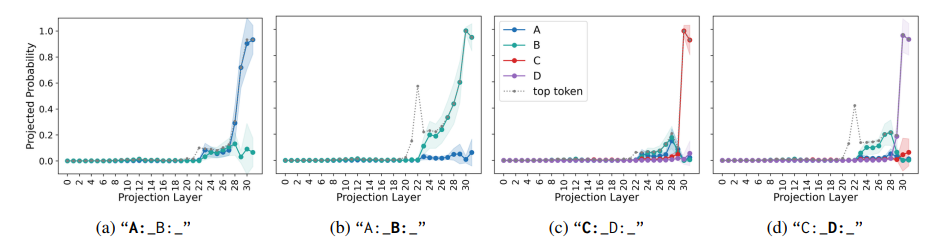
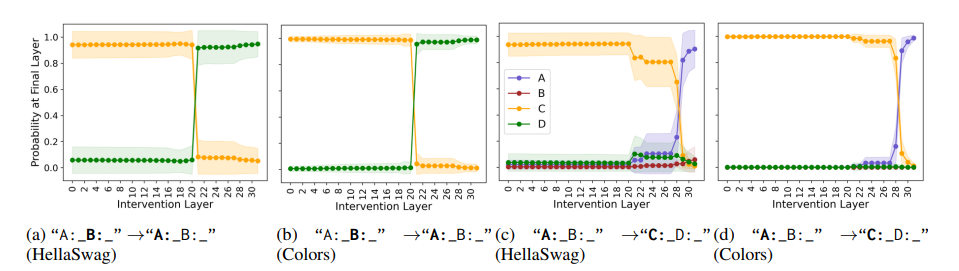
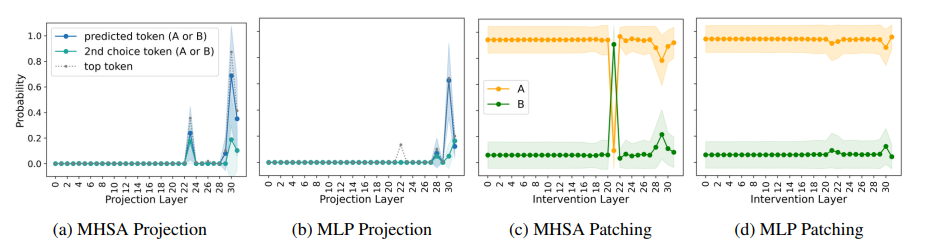
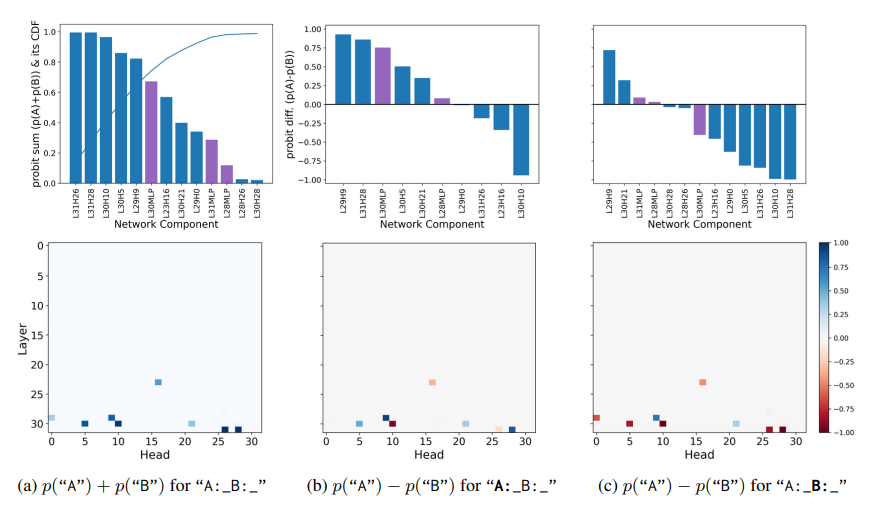
文章链接:
https://arxiv.org/pdf/2407.15018
03
Demystifying Verbatim Memorization in Large Language Models
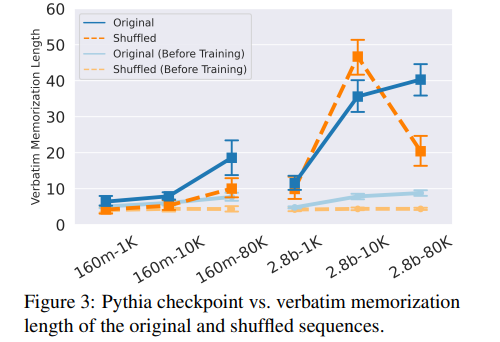
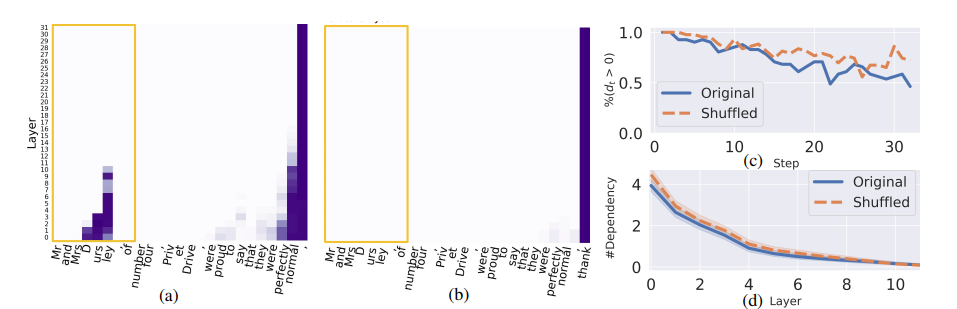
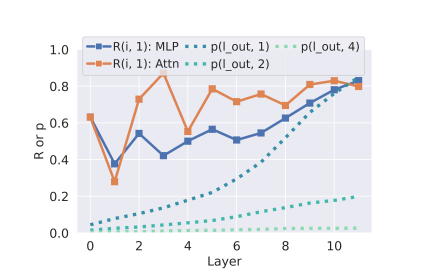
大型语言模型(LLMs)经常逐字记忆长序列,这往往带来严重的法律和隐私问题。为了补充使用观察数据研究这种逐字记忆的先前工作,研究者开发了一个框架,通过从Pythia检查点继续预训练并注入序列,在受控环境中研究逐字记忆。研究发现:(1) 需要一定量的重复才能实现逐字记忆;(2) 较晚的(可能性能更好的)检查点更有可能逐字记忆序列,即使是对于分布外的序列;(3) 记忆序列的生成是由编码高级特征的分布式模型状态触发的,并且大量利用了通用语言建模能力。在这些发现的指导下,研究者开发了压力测试来评估遗忘方法,并发现这些方法通常无法移除逐字记忆的信息,同时还可能降低语言模型的性能。总体来看,这些发现挑战了逐字记忆仅由特定模型权重或机制引起的假设。相反,逐字记忆与语言模型的通用能力密切相关,因此很难在不降低模型质量的情况下进行隔离和抑制。

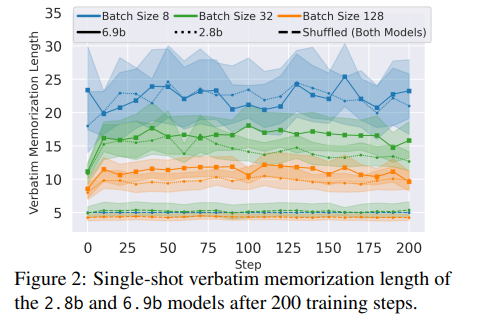
文章链接:
https://arxiv.org/pdf/2407.17817
04
Harmonizing Visual Text Comprehension and Generation
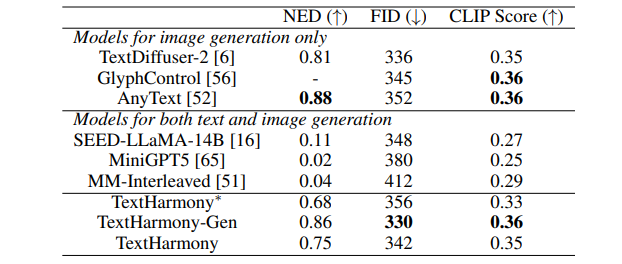
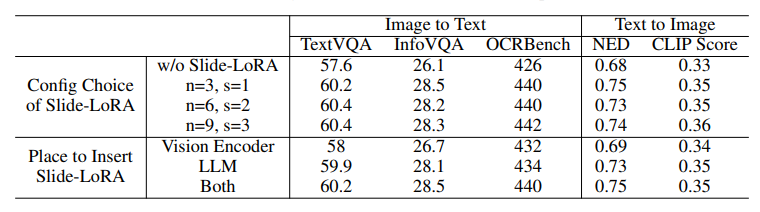
这项工作介绍了TextHarmony,这是一个统一且多功能的多模态生成模型,擅长理解并生成视觉文本。同时生成图像和文本通常会导致性能下降,因为视觉和语言模态之间存在固有的不一致性。为了克服这一挑战,现有方法依赖于特定模态的数据进行监督微调,需要不同的模型实例。提出了Slide-LoRA,它动态聚合了特定模态和非特定模态的LoRA专家,部分解耦了多模态生成空间。Slide-LoRA在一个单一的模型实例中协调视觉和语言的生成,从而促进了更加统一的生成过程。此外,开发了一个高质量的图像标题数据集DetailedTextCaps-100K,使用复杂的闭源MLLM合成,以进一步提升视觉文本生成能力。在各种基准测试中的全面实验证明了所提出方法的有效性。得益于Slide-LoRA,TextHarmony在参数仅增加2%的情况下,达到了与特定模态微调结果相当的性能,并在视觉文本理解任务中平均提高了2.5%,在视觉文本生成任务中提高了4.0%。这项工作描绘了在视觉文本领域内采用集成方法进行多模态生成的可行性,为后续的研究奠定了基础。
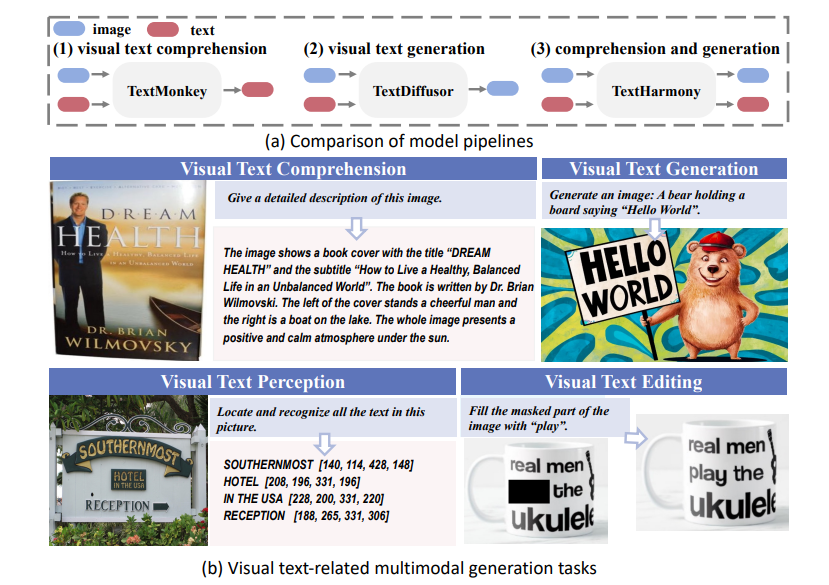
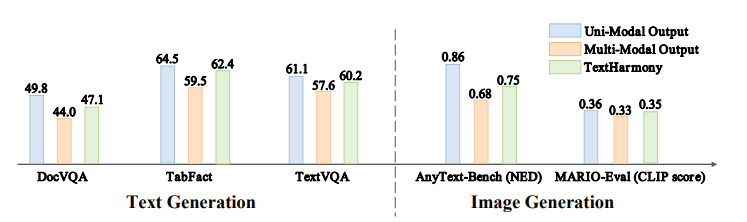
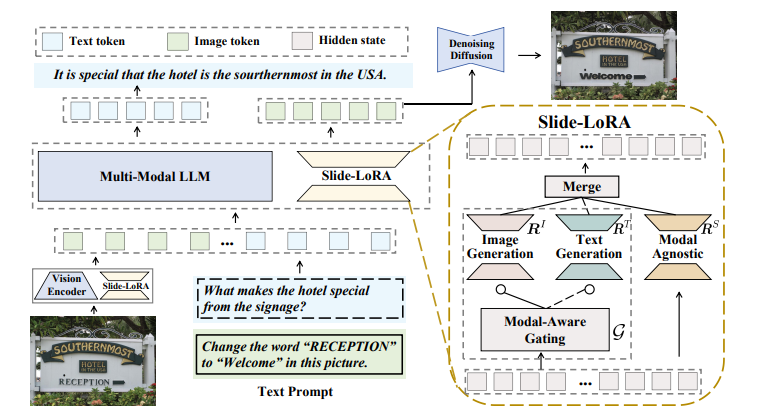
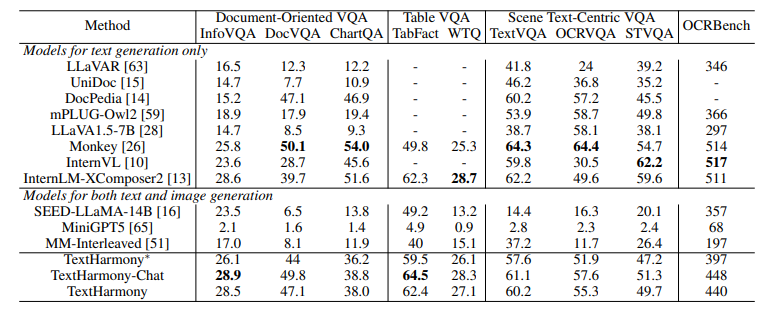
文章链接:
https://arxiv.org/pdf/2407.16364
05
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval
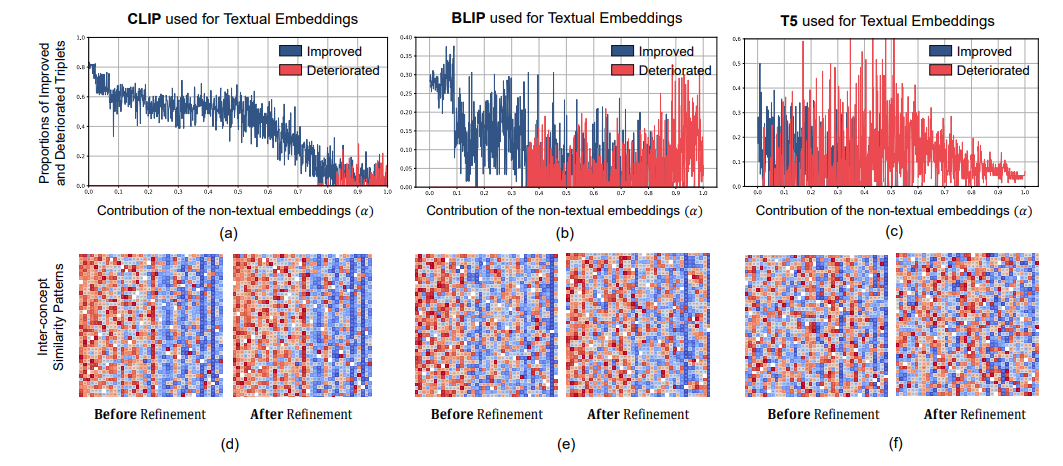
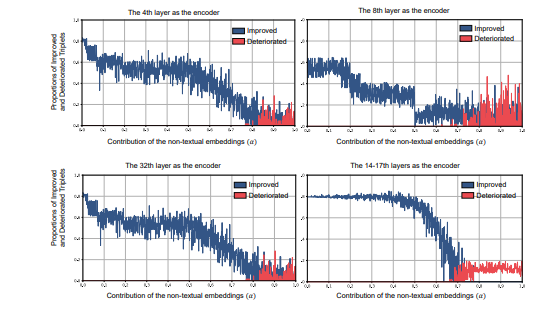
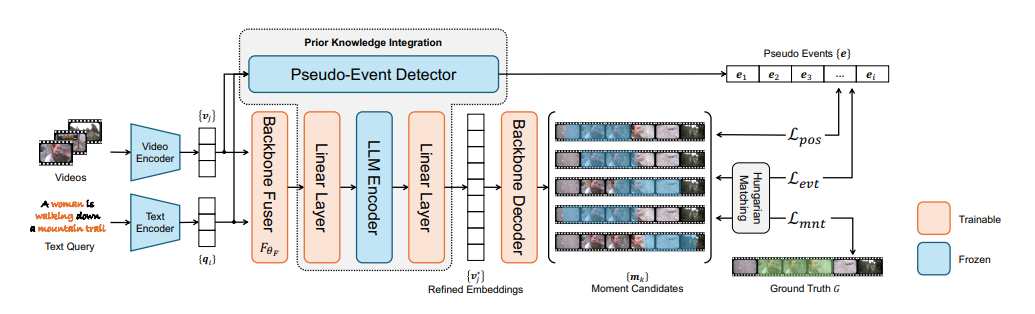
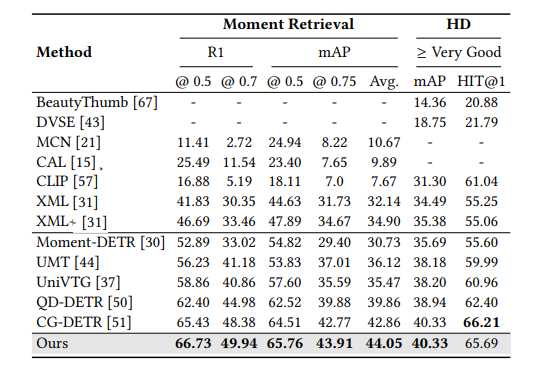
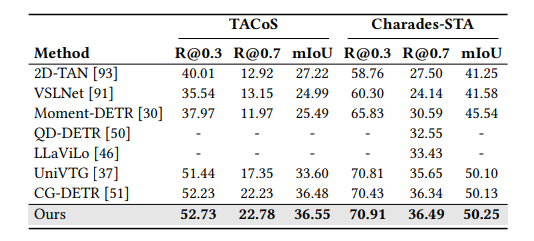
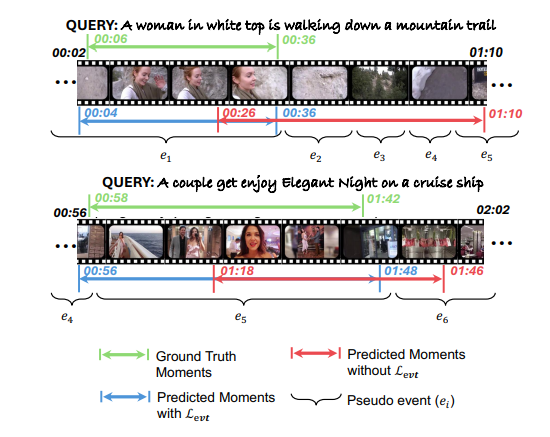
在本文中,研究者探讨了利用大型语言模型(LLMs)整合通用知识,并将伪事件作为先验信息,用于视频片段检索(VMR)模型中时间内容分布的可行性。这项研究的动机源于使用LLMs作为解码器生成离散文本描述的局限性,这阻碍了它们直接应用于连续输出,如显著性得分和捕捉帧间关系的帧间嵌入。为了克服这些限制,提出了使用LLM编码器代替解码器。通过可行性研究,展示了LLM编码器即使没有在文本嵌入上训练,也能有效地提炼多模态嵌入中的概念间关系。研究还表明,LLM编码器的提炼能力可以转移到其他嵌入,如BLIP和T5,只要这些嵌入展现出与CLIP嵌入相似的概念间相似性模式。提出了一个将LLM编码器整合到现有VMR架构中的通用框架,特别是在融合模块中。LLM编码器提炼概念关系的能力可以帮助模型平衡对前景概念(例如,人物、面孔)和背景概念(例如,街道、山脉)的理解,而不是只关注视觉上占主导地位的前景概念。此外,引入了通过事件检测技术获得的伪事件概念,以指导在事件边界内预测时刻,而不是跨越它们,这可以有效地避免相邻时刻的干扰。使用LLM编码器进行语义提炼和伪事件调节的整合被设计为插件组件,可以整合到现有VMR方法的通用框架中。通过实验验证,通过实现VMR领域最先进的性能,展示了所提出方法的有效性。
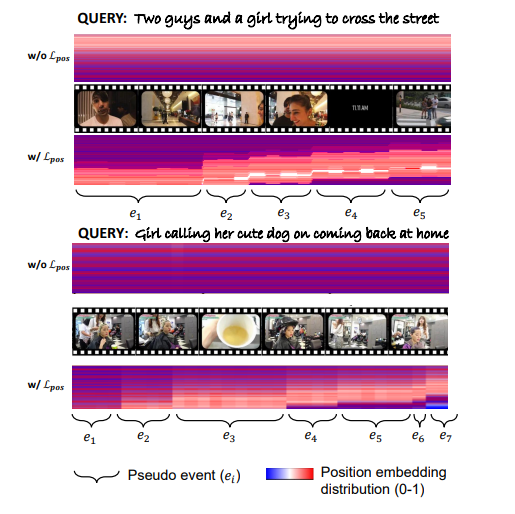
文章链接:
https://arxiv.org/pdf/2407.15051
06
DOPRA: Decoding Over-accumulation Penalization and Re-allocation in Specific Weighting Layer
这项研究介绍了DOPRA,这是一种新颖的方法,旨在减轻多模态大型语言模型(MLLMs)中的幻觉现象。与通常需要昂贵的补充训练数据或整合外部知识源的现有解决方案不同,DOPRA通过解码特定加权层的惩罚和重新分配,创新地解决了幻觉问题,提供了一种无需额外资源的经济有效解决方案。DOPRA基于对MLLMs内部控制幻觉的内在机制的深入理解,尤其是模型倾向于过度依赖自注意力矩阵中的一小部分摘要标记,而忽略了关键的与图像相关的信息。这种倾向在某些层中尤为显著。为了对抗这种过度依赖,DOPRA采用了在解码过程中对特定层(如第12层)应用加权叠加惩罚和重新分配的策略。此外,DOPRA还包括一个回顾性分配过程,这个过程重新检查生成的标记序列,允许算法重新分配标记选择,以更好地与实际图像内容对齐,从而减少自动生成的字幕中幻觉描述的发生。总体而言,DOPRA通过在解码过程中进行有针对性的调整,系统地减少幻觉,代表了提高MLLMs输出质量的重要进步。
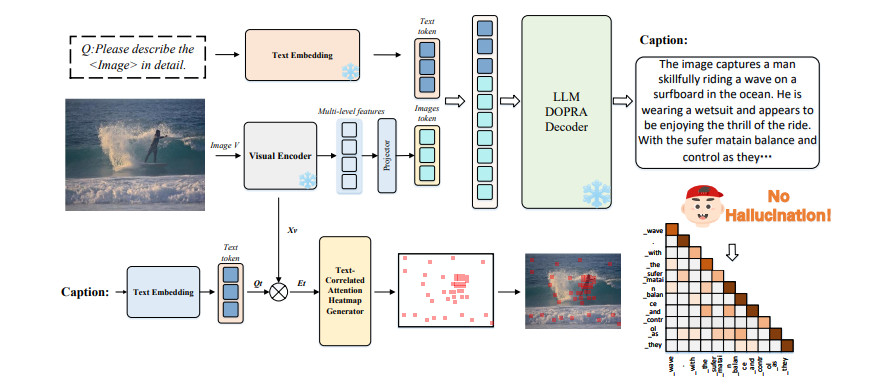
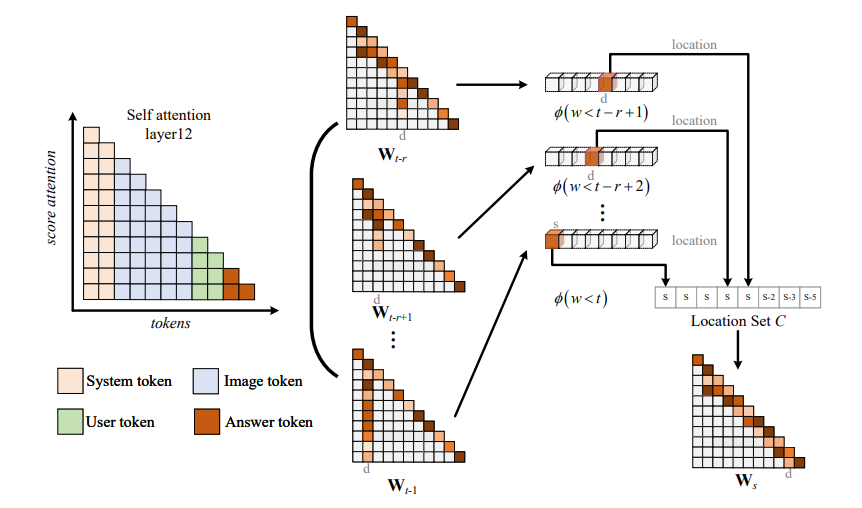
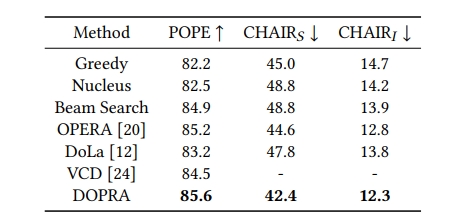
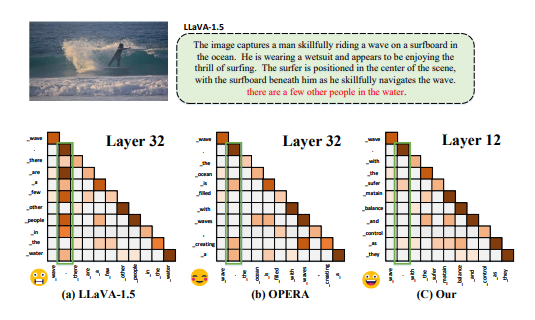
文章链接:
https://arxiv.org/pdf/2407.15130
07
Unveiling In-Context Learning: A Coordinate System to Understand Its Working Mechanism
大型语言模型(LLMs)展现出了显著的上下文学习能力(ICL)。然而,ICL的内在工作机制尚不清楚。近期研究对ICL提出了两种相互矛盾的观点:一种观点认为ICL归功于LLMs固有的任务识别能力,认为标签的正确性和示例的展示次数并不关键;另一种观点则强调示例中类似例子的影响,强调标签正确性和更多示例展示的必要性。在这项研究中,提出了一个二维坐标系统,将这两种观点整合到一个系统化的框架中。该框架通过两个正交变量来解释ICL的行为:LLMs是否能够识别任务,以及示例中是否呈现了类似的例子。研究中提出了峰值逆排名度量标准来检测LLMs的任务识别能力,并研究了LLMs对不同相似性定义的反应。在此基础上,进行了广泛的实验,阐明了ICL在多个代表性分类任务的每个象限中是如何运作的。最后,研究还将分析扩展到了生成任务,表明这个坐标系统也可以有效地用于解释生成任务中的ICL。
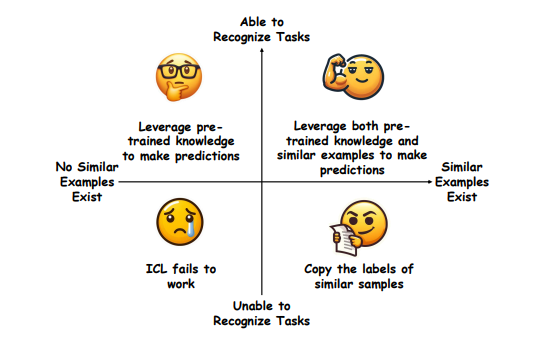
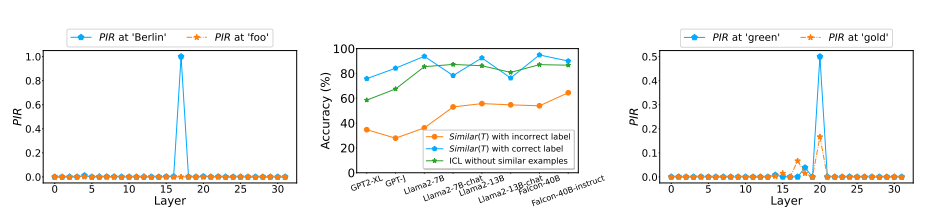
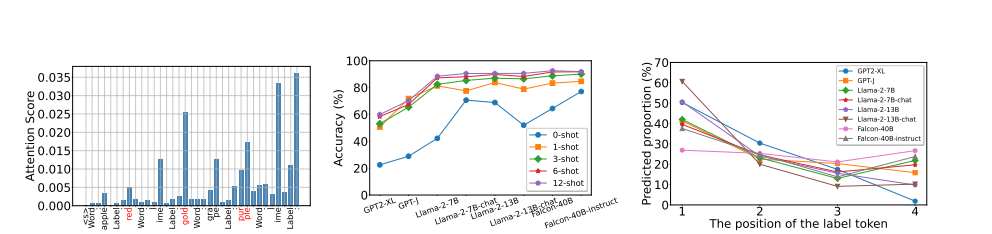
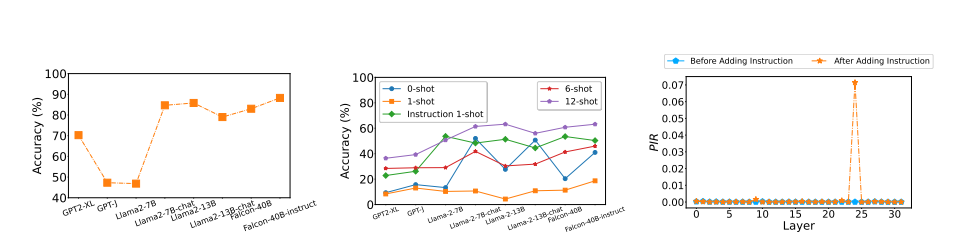
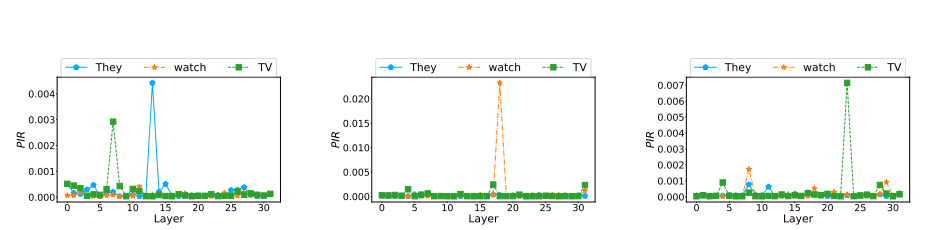
文章链接:
https://arxiv.org/pdf/2407.17011
本期文章由陈研整理
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!
















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









