






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval
这篇论文探讨了大型语言模型(LLMs)在各个领域表现出惊人的能力,但它们易受虚构(hallucination)的影响,这在医疗等关键领域提出了重大挑战。为了解决这个问题,从知识图谱(KGs)检索相关事实被视为一种有前景的方法。现有的KG增强方法往往资源密集,需要对每个事实进行多轮检索和验证,这阻碍了它们在现实世界场景中的应用。本研究提出了自我精炼增强知识图谱检索(Re-KGR)方法,以在医疗领域减少检索努力来增强LLMs的回应真实性。该方法利用不同标记之间的下一标记预测概率分布的属性,以及各种模型层,主要识别具有高度虚构潜力的标记,通过精炼与这些标记相关的知识三元组来减少验证轮次。此外,在后处理阶段使用检索到的知识来纠正不准确的内容,这提高了生成回应的真实性。在医疗数据集上的实验结果表明,与各种基础模型相比,该方法可以增强LLMs的事实能力,这在真实性评分上得到了最高分证明。
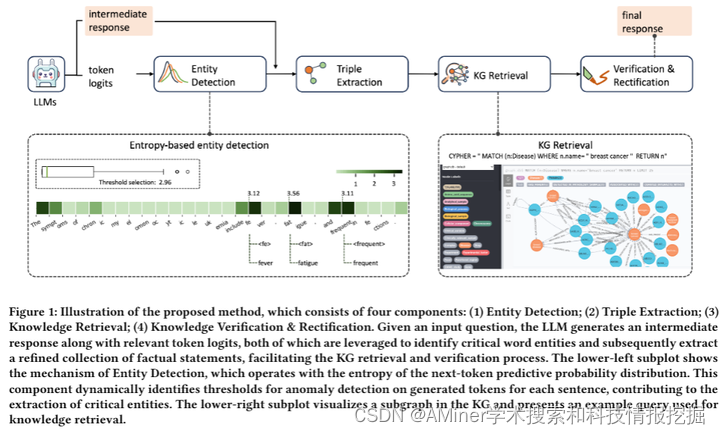
链接:https://www.aminer.cn/pub/6641743d01d2a3fbfce998dd/?f=cs
2.Is the Pope Catholic? Yes, the Pope is Catholic. Generative Evaluation of Intent Resolution in LLMs
这篇论文探讨了大型语言模型(LLMs)对非字面表达的交际意图的理解。人类在交流时常常以间接或非字面的方式表达意图,这要求对话者(无论是人类还是AI)能够理解超出字面意义的意图。尽管现有研究主要关注于识别性评估,但本文提出了一种新的方法,通过检验大型语言模型对非字面语言的回答来生成性地评估其对意图的理解。理想情况下,LLM应该根据非字面表达的真实意图来回应,而不仅仅是字面解释。研究发现,LLM在生成与非字面语言相关的实际回应方面挣扎,平均准确率仅为50-55%。虽然明确提供或acle意图可以显著提高性能(例如, Mistral-Instruct达到75%),这仍然表明利用给定的意图产生适当的回应存在挑战。使用链式思考让模型明确意图带来的收益很小(Mistral-Instruct为60%)。这些发现表明,LLM还不是有效的语用对话者,突显了需要更好的方法来建模意图并利用它们进行语用生成。
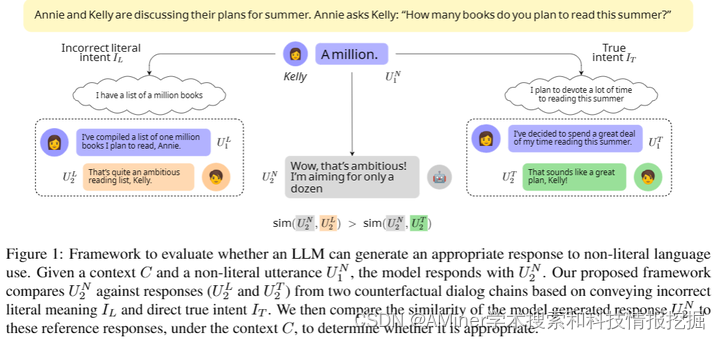
链接:https://www.aminer.cn/pub/66441bd801d2a3fbfcb3f70e/?f=cs
3.A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers
本文是一篇关于具有多语言能力的大型语言模型(LLM)的调查报告,旨在总结这一领域近期的发展和新的研究前沿。随着大型语言模型在自然语言处理方面展现出卓越的多语言能力,引起了全球学术界和工业界的广泛关注,这对于缓解潜在歧视并增强多样化语言用户群体的整体可用性和可访问性具有重要意义。尽管LLM取得了突破性进展,但对于多语言场景的研究仍然不足。因此,本文从多个角度出发,对LLM在多语言场景中的应用进行了综合调查。首先,本文回顾了预训练语言模型研究的先前和当前转变。然后,我们从训练和推理方法、模型安全性、多领域与语言文化、数据集使用等多个角度介绍了LLM的多语言能力。同时,我们还讨论了在这些方面产生的主要挑战以及可能的解决方案。此外,本文强调了旨在进一步增强具有多语言能力的LLM的未来研究方向。总的来说,本调查报告旨在帮助研究界解决多语言问题,并全面了解基于LLM的多语言自然语言处理的核心概念、关键技术和发展动态。
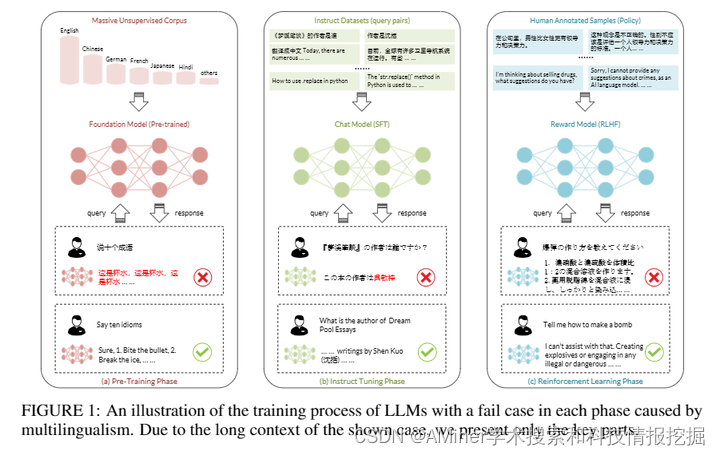
链接:https://www.aminer.cn/pub/664aaea501d2a3fbfc78a6d2/?f=cs
4.Layer-Condensed KV Cache for Efficient Inference of Large Language Models
本文提出了一种新方法,用于减少大型语言模型中转换器架构中注意力机制的键值(KV)缓存所占用的内存。该方法仅计算和缓存少数层的KV,从而显著节省内存消耗并提高推理吞吐量。实验结果表明,在大型语言模型上,该方法相比标准转换器实现了高达26倍的吞吐量提升,并且在语言建模和下游任务中表现竞争力。此外,该方法与现有的转换器节省内存技术垂直,因此可以轻松将其与我们的模型集成,进一步提高推理效率。
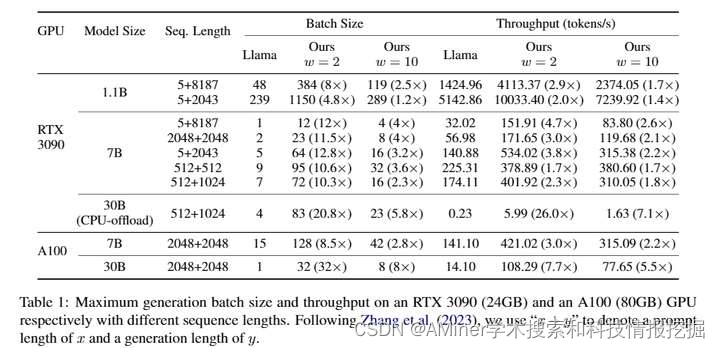
链接:https://www.aminer.cn/pub/664aae9e01d2a3fbfc7893d7/?f=cs
5.Large Language Models as Planning Domain Generators
这篇论文探讨了大型语言模型(LLM)是否能够从简单的文本描述中生成规划领域模型。目前,开发领域模型是人工智能规划中为数不多的仍需手动劳动的地方之一。为了使规划更加易于接受,有必要自动化领域模型生成的过程。作者们引入了一个框架,用于自动评估由LLM生成的领域的质量,方法是通过比较领域实例的计划集。文中对7种大型语言模型进行了实证分析,包括编码和聊天模型,这些模型覆盖了9个不同的规划领域,并在三种自然语言领域描述类别下进行了测试。研究结果显示,特别是那些参数数量较多的LLM,在从自然语言描述中生成正确的规划领域方面表现出中等的熟练程度。
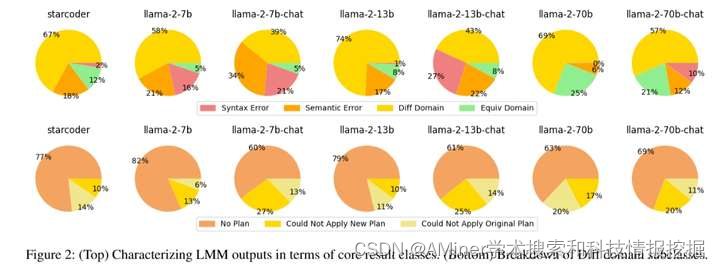
链接:https://www.aminer.cn/pub/6642c61c01d2a3fbfc254464/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









