






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
本研究提出了一种名为Web2Code的新基准,用于评估多模态大型语言模型(MLLM)在理解网页快照和生成相应HTML代码的能力。尽管MLLM在图像、视频和音频等多种模态的任务中取得了令人印象深刻的成功,但它们在理解网页快照和生成相应的HTML代码方面却表现得很差。为解决这一问题,研究者们构建了一个包含大规模网页-到-代码数据集的基准,以及一个用于评估MLLM的网页理解和HTML代码转换能力的评估框架。数据集构建过程中,研究者利用预训练的LLM来增强现有的网页-到-代码数据集,并生成一组多样化的新的网页图像。具体而言,输入是网页图像和指令,输出是网页的HTML代码。此外,研究者还在输出中包括了关于网页内容的不同自然语言问答对,以实现对网页内容的更全面理解。为了评估模型在这些任务上的性能,研究者开发了一个用于测试MLLM在网页理解和网页-到-代码生成能力的评估框架。广泛的实验表明,研究者提出的大规模数据集不仅对所提出的任务有益,而且在一般的视觉领域也更为有效,而之前的数据集则导致性能更差。研究者希望他们的研究工作将有助于开发出适用于网页内容生成和任务自动化的通用MLLM。

链接:https://www.aminer.cn/pub/66820d5301d2a3fbfcd40354/?f=cs
2.Investigating How Large Language Models Leverage Internal Knowledge to Perform Complex Reasoning
本文研究了大语言模型(LLM)如何利用内部知识进行复杂推理的问题。尽管取得了重大进展,但对于LLM如何利用知识进行推理的理解仍然有限。为了解决这个问题,研究者提出了一种方法,将复杂的现实世界问题分解成图形,将每个问题表示为一个节点,其父节点表示解决该问题所需的背景知识。研究者开发了DepthQA数据集,将问题分解为三个层次:(i)回忆概念性知识,(ii)应用程序性知识,以及(iii)分析策略性知识。基于层次图,研究者量化了前向不一致性,即LLM在简单子问题与复杂问题上的表现不一致性。研究者还测量了后向不一致性,即LLM能够回答复杂问题,但在简单问题上却遇到困难。分析结果显示,小型模型的不一致性比大型模型更多。此外,通过多轮互动将模型从简单问题引导到复杂问题,可以改善小型和大型模型的性能,这突显了在知识推理中设置有结构的 intermediate步骤的重要性。这项工作加深了我们对LLM推理的理解,并提出了改进它们问题解决能力的途径。
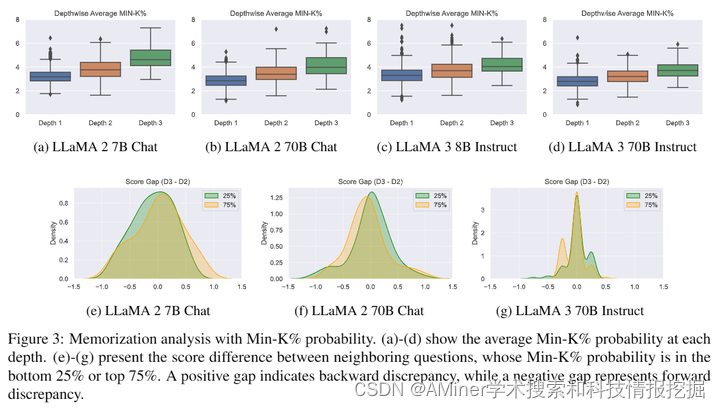
链接:https://www.aminer.cn/pub/66820d2901d2a3fbfcd3c26a/?f=cs
3.Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation
本文介绍了一种新兴的技术,即黑盒微调,它可以让用户根据自己的需求调整最先进的语言模型。但这种技术也可能被恶意用户利用,从而威胁到模型的安全性。为了展示保护微调接口的挑战,作者提出了一个隐蔽的恶意微调方法,这种方法可以通过微调来破坏模型安全性,同时又能避开检测。该方法构建了一个恶意数据集,其中每个数据点看起来都是无害的,但通过对这个数据集进行微调,可以让模型学会对编码的有害请求作出编码的有害响应。当这种方法应用于 GPT-4 模型时,得到的微调模型在执行有害指令时,成功率高达 99%,并能避开诸如数据集检查、安全性评估和输入/输出分类器等防御机制的检测。本文的研究结果质疑了黑盒微调访问是否能够抵御复杂对手的安全性。
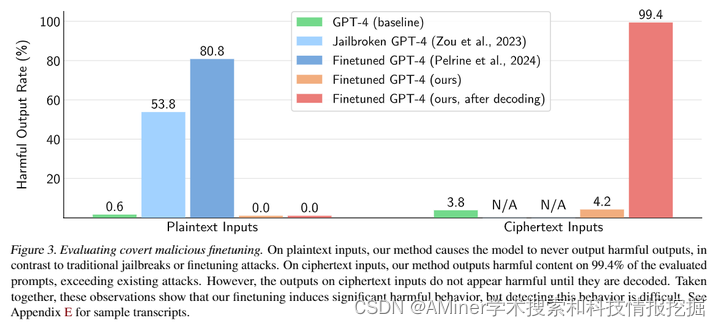
链接:https://www.aminer.cn/pub/667a992001d2a3fbfcccf5f5/?f=cs
4.SAIL: Self-Improving Efficient Online Alignment of Large Language Models
本文介绍了一种名为SAIL的方法,旨在有效在线对大型语言模型(LLM)进行对齐。目前,用于与人类偏好对齐的强化学习方法(RLHF)存在一些问题。一方面,现有的离线对齐方法(如DPO、IPO和SLiC)依赖于固定的偏好数据集,可能导致性能不佳。另一方面,虽然最近的研究关注于设计在线RLHF方法,但仍然缺乏统一的理论框架,并受到分布偏移问题的困扰。为了解决这个问题,本文提出了一个观点,即在线LLM对齐是基于双层优化的。通过将这个公式简化为一个高效的单层一阶方法(使用奖励-策略等价性),本文的方法通过探索响应和调整偏好标签来生成新样本,并迭代优化模型对齐。这样做使对齐方法能够以在线和自我改进的方式运行,并将先前的在线RLHF方法视为特例。与最先进的迭代RLHF方法相比,本文的方法在对开源数据集进行对齐时,性能显著提高,且计算开销最小。
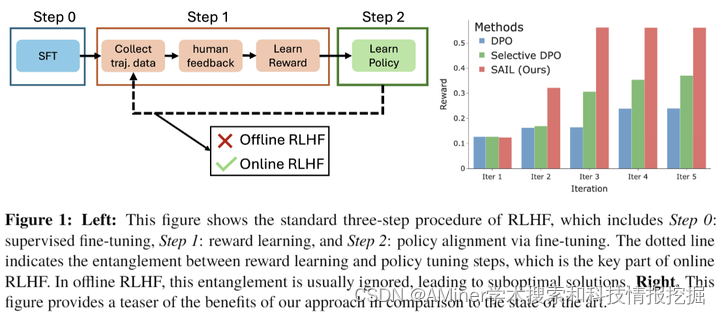
链接:https://www.aminer.cn/pub/667a250f01d2a3fbfc706a3c/?f=cs
5.Large Language Models Assume People are More Rational than We Really are
本文研究了大型语言模型(LLMs)在模拟和预测人类决策时所隐含的内部决策模型。尽管之前的研究表明这些内部模型是准确的,即LLMs能够可信地代表人类行为,但在本研究中,通过将LLM行为和预测与大量人类决策数据进行比较,我们发现实际情况并非如此:一系列尖端LLMs(包括GPT-4o 4-Turbo、Llama-3-8B 70B和Claude 3 Opus)在模拟和预测人们的选择时,都假设人们比实际更理性。具体来说,这些模型与人类行为偏离,更符合经典的理性选择模型——期望价值理论。有趣的是,人们在解释他人的行为时也倾向于认为他人是理性的。因此,当我们将LLMs和人类从他人的决策中得出的推论与另一个心理学数据集进行比较时,我们发现这些推论高度相关。因此,LLMs所隐含的决策模型似乎与人类的期望相符,即认为其他人会理性行动,而不是与人们实际的行为相符。
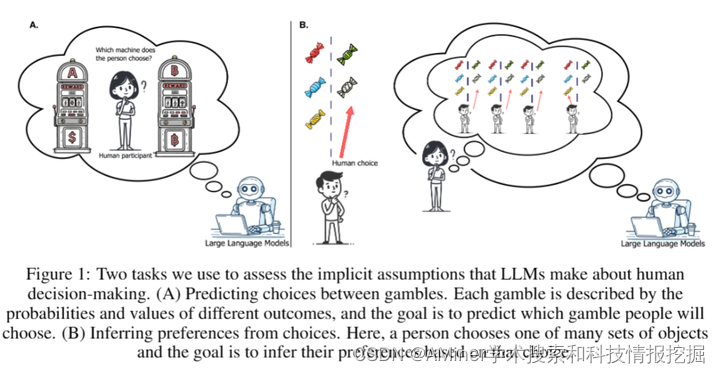
链接:https://www.aminer.cn/pub/667b75df01d2a3fbfc7fc6b0/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









