






1 介绍
在过去的一年中,多模态大型语言模型(MM-LLMs)取得了实质性的进步,通过成本效益良好的训练策略增强了现成的LLMs,以支持MM输入或输出。由此产生的模型不仅保留了LLM固有的推理和决策能力,还为各种不同的MM任务提供了动力。
在本文中,我们提供了一个全面的调查报告,旨在促进MM-LLMs的进一步研究。首先,我们概述了模型架构和训练流水线的通用设计制定。随后,我们介绍了一个包括122个MM-LLM的分类,每个都以其特定的制定而著称。此外,我们审查了选定的MM-LLM在主流基准上的性能,并总结了增强MM-LLM潜力的关键训练配方。最后,我们探讨了MM-LLMs的未来发展方向,同时保持一个实时跟踪网站1来追踪该领域的最新发展。我们希望这份调查报告能为MM-LLMs领域的持续进步做出贡献。

图1 MM-LLMs的时间轴
2 模型体系结构
本节介绍了构成通用模型架构的五个组件,如图2,包括模式编码器、LLM主干、模式生成器、输入和输出投影器。其中,MM-LLM仅包括前三个组件,并强调了投影器是轻量级的组件,MM-LLM可以高效地训练以支持各种MM任务。总体参数数量取决于使用的核心LLM的规模。
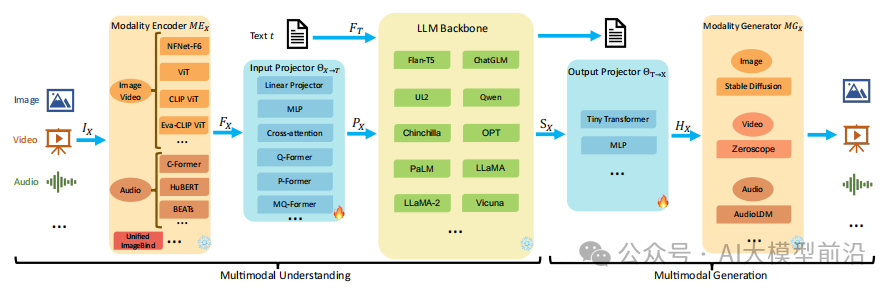
图2 MM-LLMs的一般模型架构以及每个组件的实现选择。
2.1 模态编码器
模态编码器负责将不同模态的输入编码为相应的特征,针对不同的模态,存在多种预训练的编码器选项。视觉模态可以使用多种编码器,如NFNet-F6、ViT等。音频模态通常使用CFormer、HuBERT等编码器。三维点云模态通常使用ULIP-2和PointBERT等编码器。此外,还介绍了一些MM-LLMs,特别是ImageBind,这是一种涵盖多种模态的统一编码器。
2.2 输入投影器
输入投影器负责将其他模态编码特征与文本特征空间对齐,作为提示被馈送到LLM主干中。有多种实现方式,如线性投影器、多层感知器、交叉注意等。Q-、P-、MQ-Former需要对PT过程进行初始化。这些方法的目标是尽可能地最小化X-条件下的文本生成损失。
2.3 LLM主干
MM-LLM是一种基于LLM的模型,继承了LLM的一些显著属性,如零样本泛化、少数样本ICL、思维链(CoT)和指令遵循。它能够处理各种模态的表示,参与语义理解、推理和输入的决策,并产生直接的文本输出和来自其他模态的信号标记。一些工作还引入了参数高效的微调方法,如前缀微调、LoRA和层规范微调。MM-LLM中常用的LLM包括Flan-T5、ChatGLM等。
2.4 输出投影仪
输出投影器将信号令牌表示映射到可被模式生成器理解的特性中,通过最小化HX与MGX的文本表示之间的距离,促进映射特性与文本表示的对齐。优化仅依赖于字幕文本,不利用任何音频或视觉资源。输出投影器由具有可学习解码器特征序列或MLP的可调谐微缩器实现。
2.5 模式生成器
模式生成器MGX负责生成不同模式的输出,输出投影器映射的特征HX作为条件输入用于噪声消除过程中的MM内容生成。在训练期间,首先通过预训练VAE将地面真实内容转换为潜在特征z0,然后向z0中添加噪声以获得噪声的潜在特征zt,并使用预训练的Unet计算条件LDM损失LX-gen。
3 训练管道
MM-LLMs训练流程可以被划分为两个主要阶段:MM PT和MM IT。
3.1 MM PT
在PT阶段,利用XText数据集训练输入和输出投影器,以实现不同模式之间的对齐。MM理解模型仅优化公式(2),而MM生成模型则优化公式(2)、(4)和(5),后者还包括真实信号标记序列。X-Text数据集包括图像、视频和音频文本,图像文本有两种类型:图像文本对和交错的图像文本语料库。详细信息见附录G中的表3。
3.2 MM IT
MM IT是一种使用指令格式化的数据微调预训练的MM-LLMs的方法,通过这个过程,MM-LLMs可以泛化到未见过的任务,从而提高零击性能。MM IT包括监督微调(SFT)和人类反馈驱动的强化学习,旨在与人类意图对齐并增强MM-LLMs的交互能力。SFT将PT阶段数据的一部分转换为指令感知格式,而RLHF涉及进一步的微调模型,依赖于有关MM-LLMs响应的反馈。现有的MM-LLMs在MM PT和MM IT阶段使用的数据集是多样的,但它们都是附录G表3和表4中数据集的子集。
4 SOTA MM-LLM
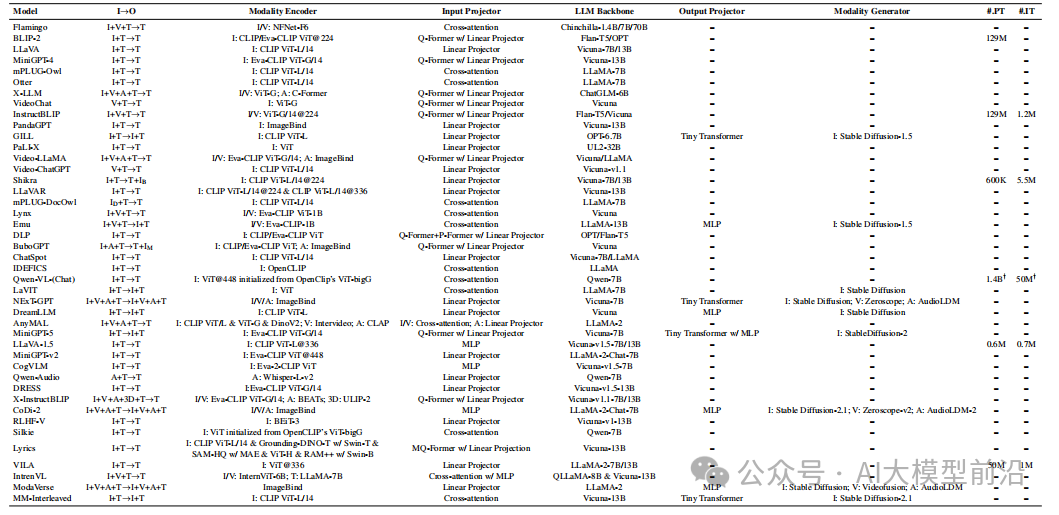
图3从功能和设计角度对SOTA MM-LLM进行了分类,并全面比较了43个架构和训练数据集规模,如表1。总结了MM-LLM的现有趋势,包括从专注于MM理解到特定模式的生成,从MM预训练到SFT和RLHF,并采用更有效的模型架构。同时,也纳入了更高质量的训练数据集和多样化的扩展模式。这些趋势表明MM-LLM在不断改进和演进,以更好地适应人类意图并增强模型的会话交互能力。

图3 MM-LLM的分类。I:图像,V:视频,A/S:音频/语音,T:文本。ID:文档理解,IB:输出框边界,IM:输出分割掩模,IR:输出检索图像。
表1 43个主流MM-LLM的总结。I→O:输入到输出模态,I:图像,V:视频,A:音频,3D:点云,T:文本。在 Modality Encoder 中,“-L”表示 Large,“-G”表示 Giant,“/14”表示 patch 大小为 14,“@224”表示图像分辨率为 224 × 224。#.PT 和 #.IT 分别表示 MM PT 和 MM IT 期间数据集的规模。† 包括不可公开访问的内部数据。
5 基准和性能
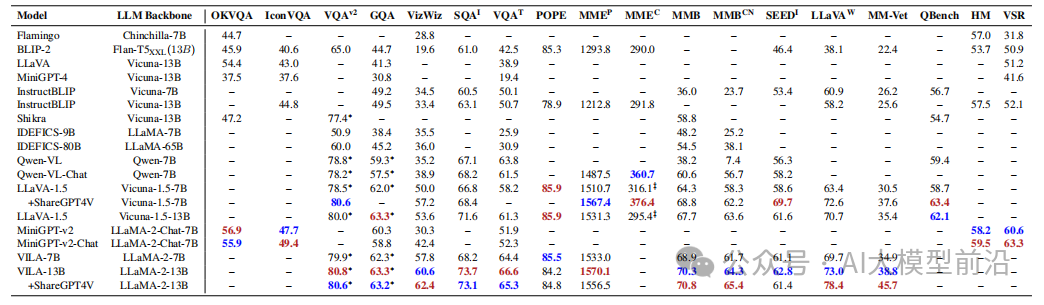
为了提高MMLLMs的有效性,可以从训练配方中提取一些关键点。首先,更高的图像分辨率可以提供更多的视觉细节,但需要权衡分辨率和成本。其次,高质量的SFT数据可以提高特定任务的性能。此外,一些模型还发现交错的图像-文本数据是有益的,而单独的图像文本对是不够理想的。最后,在SFT期间重新混合仅包含文本指令数据与图像文本数据可以提高VL任务的准确性。这些见解可以帮助优化MMLLMs的性能。
表2 主流MM-LLMs在18个VL基准上的比较。红色表示最高结果,蓝色表示第二高结果。‡表示ShareGPT4V(Chen等人,2023f)重新实现的测试结果,这些结果在基准或原始论文中缺失。*表示在训练过程中观察到训练图像。
6 未来方向
在这一部分,我们探讨MM-LLMs在以下方面的有前途的未来发展方向:
增强MM-LLMs的力量的四个关键领域:(1)扩展模式:当前的MMLLM主要支持图像、视频、音频、3D和文本等模式,但现实世界涉及更广泛的各种模式,将MM-LLMs扩展到其他模式将增加其通用性和普遍适用性;(2)多样化的LLM:整合各种类型和大小的LLM为从业人员提供了选择最合适的LLM的灵活性;(3)提高MM IT数据集质量:当前MM IT数据集存在改进和扩展空间,多样化的指令范围可提高MM-LLMs在执行用户命令方面的有效性;(4)加强MM生成能力:大多数MMMLLM主要关注MM理解,但一些模型已纳入MM生成能力,探索整合基于检索的方法可能增强模型的整体性能。
更具挑战性的基准**:**现有基准可能不足以挑战MM-LLMs的能力,因为许多数据集在PT或IT集合中已出现。此外,当前基准主要集中在VL子领域。为MM-LLMs开发更具挑战性的更大规模的基准,包括更多模式并使用统一的评估标准是至关重要的。例如,GOAT-Bench用于评估MM-LLMs在meme中识别社会虐待的能力,MathVista评估数学推理能力,MMU和CMMMU分别为英语和中文设计了多学科MM理解与推理基准。BenchLMM评估跨风格视觉能力,Liu等人研究了光学字符识别能力。
**移动/轻量级部署:**在资源受限平台上部署MM-LLM并实现最佳性能至关重要。轻量级实现如MobileVLM通过降低规模和提高计算速度实现无缝部署。其他研究如TinyGPT-V、Vary-toy、Mobile-Agent、MoE-LLaVA和MobileVLM V2也致力于有效计算和推理。然而,这一领域仍需进一步探索。实体智能是一种使机器人能像人类一样感知和交互环境的技术。它涉及理解环境、识别对象、评估空间关系并制定任务计划。实体AI任务如实体规划、实体视觉问答和实体控制,让机器人能自主执行扩展计划。该领域的研究如PaLM-E和EmbodiedGPT,在增强机器人与现实世界的互动能力方面取得了进展。
持续学习对于更新MMLLMs并赋予它们新技能至关重要。然而,由于训练成本高昂,需要高效的方法来利用新数据,同时避免重新训练的成本。CL分为持续的PT和IT两个阶段,并面临灾难性遗忘和负向正向转移等挑战。
减轻幻觉是提高MMLLMs输出的重要问题。幻觉可能源于训练数据中的偏见和注释错误。目前的方法包括利用自我反馈作为视觉线索来减轻幻觉。然而,仍需区分准确和幻觉输出,并在训练方法上取得进展以提高输出可靠性。
7 结论
本文全面调查了MM-LLMs的最新进展,提供了模型架构的通用设计配方和训练管道的详细概述,并介绍了各种SOTA模型。同时,我们也展望了该领域的未来发展,并建立了一个专门的网站进行实时跟踪(https://mm-llms.github.io)。虽然受限于篇幅限制,我们无法深入探讨所有技术细节,但我们的概述为研究人员提供了一些启示,并有望为MM-LLMs领域的发展做出贡献。我们将继续密切关注并不断加强相关细节,随着新见解的出现而不断充实。
随着大模型的不断爆火,每个行业都在开发搭建自己的私有化大模型,时代急需大量大模型人才,也会带来大批量的就业岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下最大的风口,是一个可以改变自身的机会,就看我们怎么把握住。
那么,我们如何去学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习计划

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

以上的AI大模型学习资料,都已上传至CSDN,需要的小伙伴可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









