










参考
系统评价——指标数据的规范化处理(一) - 郝hai - 博客园 (cnblogs.com)
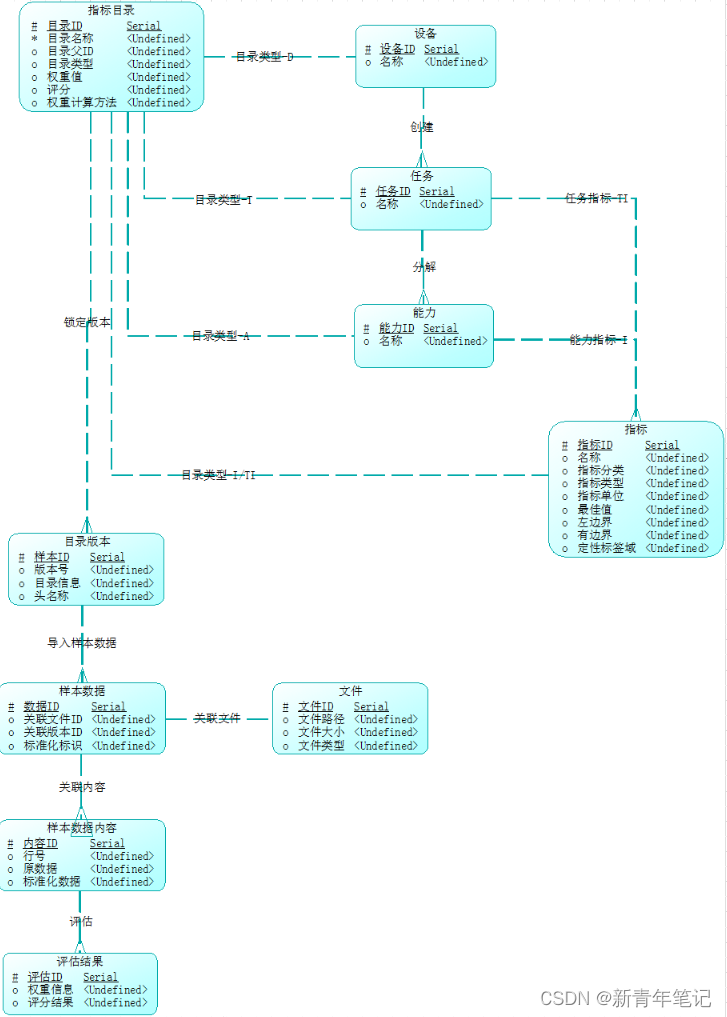
构建多层级的目录结构指标体系,从低向上的聚合计算评估。
核心业务概念模型
核心业务流程
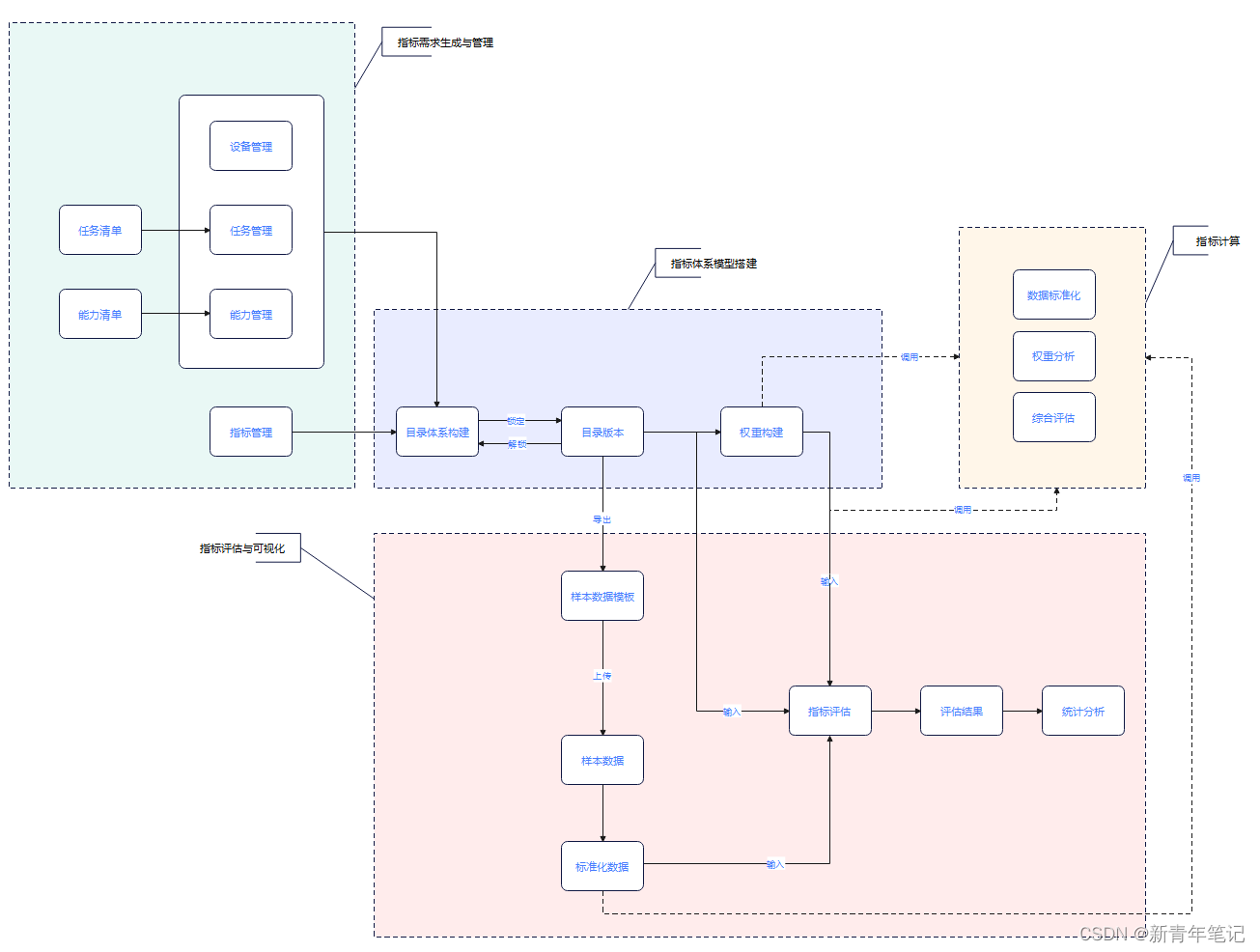
指标体系搭建
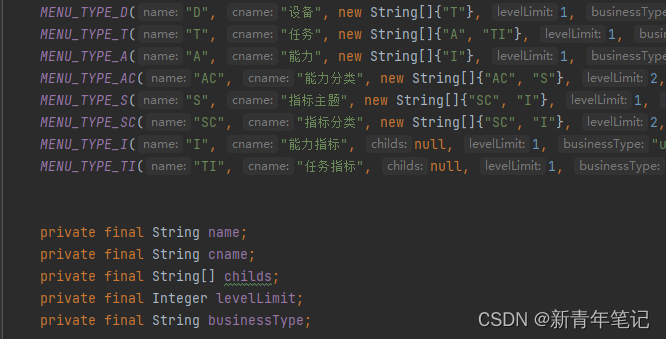
目录构建
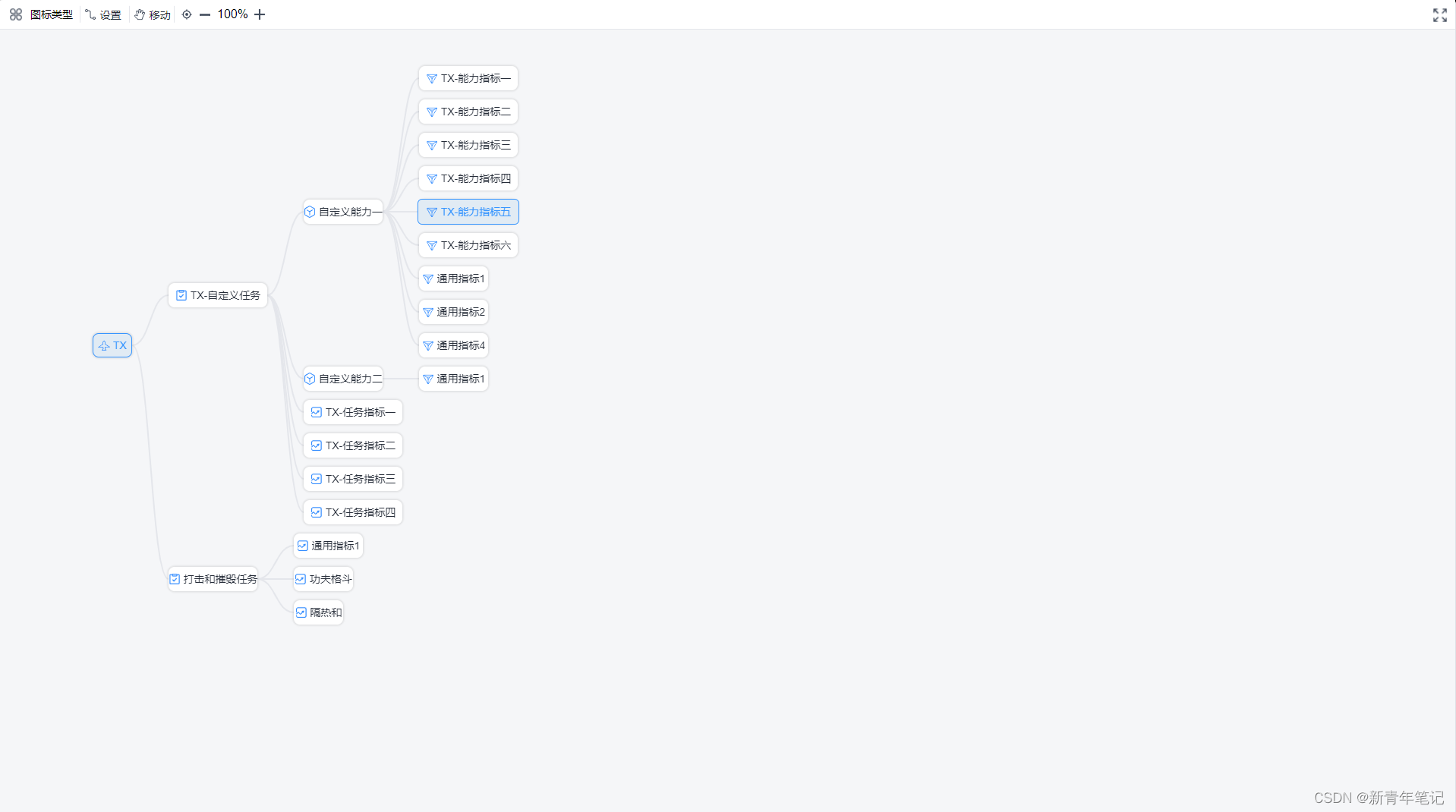
简单实现构建规则,例如下面通过枚举类实现目录构建规则的定义,层级的设置,每个层级子级的设置,以及可分解的层级限制等规则。目的是构建一棵符合规则的树形菜单结构,构建结束,锁定目录,形成稳定的指标目录--版本记录。(锁定的时候可以对整棵树默认权重)
脑图模式:
权重构建
给指标目录每个层级赋值权重,赋值权重可以根据实际情况选择不同的权重计算方法。根据实际需要实现不同的权重计算算法。目的是对整棵树全部设置权重值。

算法:
下面举例权重分析算法-ahp层次分析法的实现:
java实现:
public class AHPMethod {
public static JSONObject ahpMethod(double[][] dataset, String wd) {
// 随机一致性指标R.I.(inc_rat)
double[] inc_rat = {0, 0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51, 1.48, 1.56, 1.57, 1.59};
// 数据深复制
double[][] X = new double[dataset.length][dataset[0].length];
for (int i = 0; i < dataset.length; i++) {
X[i] = Arrays.copyOf(dataset[i], dataset[i].length);
}
// 生成权重向量
double[] weights = new double[X[0].length];
// 根据权重计算方法来确定各个权重
if (wd.equals("m") || wd.equals("mean")) { // 均值
for (int i = 0; i < X.length; i++) {
double sum = 0;
for (int j = 0; j < X[i].length; j++) {
int finalJ = j;
sum += X[i][j] / Arrays.stream(X).mapToDouble(row -> row[finalJ]).sum();
}
weights[i] = sum / X.length;
}
} else if (wd.equals("g") || wd.equals("geometric")) { // 几何
for (int i = 0; i < X.length; i++) {
double product = 1;
for (double value : X[i]) {
product *= value;
}
weights[i] = Math.pow(product, 1.0 / X[i].length);
}
double sum = Arrays.stream(weights).sum();
for (int i = 0; i < weights.length; i++) {
weights[i] /= sum;
}
}
// 计算特征根向量
double[] vector = new double[X.length];
for (int i = 0; i < X.length; i++) {
double sum = 0;
for (int j = 0; j < X[i].length; j++) {
sum += X[i][j] * weights[j];
}
vector[i] = sum / weights[i];
}
// 获得平均特征根
double lamb_max = Arrays.stream(vector).average().orElse(0);
// 计算一致性指标
double cons_ind = (lamb_max - X.length) / (X.length - 1);
double ri = inc_rat[X.length];
// 一致性判断
double cr = cons_ind / ri;
JSONObject data = new JSONObject();
data.put("vector", vector);
data.put("weights", weights);
data.put("lambmax", lamb_max);
data.put("ci", cons_ind);
data.put("ri", ri);
data.put("cr", cr);
return data;
}python实现:
java调用python
public JSONObject ahpWeight(double[][] data, String flags) {
flags = StringUtils.isEmpty(flags) ? "m" : flags;
if (remoteSwitch) {
try {
JSONObject reqData = new JSONObject();
reqData.put("data", data);
reqData.put("flags", flags);
log.info("reqData:{}", JSONObject.toJSONString(reqData));
String res = HttpUtils.sendPost(remoteServerUrl + BizConstants.PYTHON_AHP_WEIGHT, JSONObject.toJSONString(reqData));
log.info("resData:{}", res);
return JSONObject.parseObject(res);
} catch (Exception e) {
throw new ServiceException("服务异常");
}
}
//指定命令、路径、传递的参数
String[] arguments = new String[]{"python",
localPath + "/" + "ahp_weight.py",
transforString(data),
flags};
return callPython(arguments);
}private JSONObject callPython(String[] arguments) {
log.info("算法执行入参:{}", JSONObject.toJSONString(arguments));
StringBuilder sbrs = null;
StringBuilder sberror = null;
try {
ProcessBuilder builder = new ProcessBuilder(arguments);
Process process = builder.start();
BufferedReader in = new BufferedReader(new InputStreamReader(process.getInputStream(), "utf-8"));//获取字符输入流对象
BufferedReader error = new BufferedReader(new InputStreamReader(process.getErrorStream(), "utf-8"));//获取错误信息的字符输入流对象
String line = null;
sbrs = new StringBuilder();
sberror = new StringBuilder();
//记录输出结果
while ((line = in.readLine()) != null) {
sbrs.append(line);
}
//记录错误信息
while ((line = error.readLine()) != null) {
sberror.append(line);
}
in.close();
process.waitFor();
} catch (Exception e) {
e.printStackTrace();
}
if (sberror.length() > 0) {
log.error("算法执行异常:{}", sberror);
throw new ServiceException("算法执行异常:" + sberror);
}
log.info("算法执行结果:{}", JSONObject.toJSONString(sbrs));
JSONObject result = JSONObject.parseObject(sbrs.toString());
return result;
}本地python
import sys
import json
import ast
import numpy as np
from functools import reduce
def ahp_method(dataset, wd = 'm'):
# 随机一致性指标R.I.(inc_rat)
inc_rat = np.array([0, 0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51, 1.48, 1.56, 1.57, 1.59])
# 数据深复制
X = np.copy(dataset)
# 生成权重向量
weights = np.zeros(X.shape[1])
# 根据权重计算方法来确定各个权重
if (wd == 'm' or wd == 'mean'): #均值
weights = np.mean(X/np.sum(X, axis = 0), axis = 1)
elif (wd == 'g' or wd == 'geometric'): #几何
for i in range (0, X.shape[1]):
weights[i] = reduce( (lambda x, y: x * y), X[i,:])**(1/X.shape[1])
weights = weights/np.sum(weights)
# 计算特征根向量
vector = np.sum(X*weights, axis = 1)/weights
# 获得平均特征根
lamb_max = np.mean(vector)
# 计算一致性指标
cons_ind = (lamb_max - X.shape[1])/(X.shape[1] - 1)
ri=inc_rat[X.shape[1]]
# 一致性判断
cr = cons_ind/ri
return vector,weights,lamb_max,cons_ind,ri,cr
def create_json_response(vector,weights,lamb_max,cons_ind,ri,cr):
data = {
"vector": vector.tolist(),
"weights": weights.tolist(),
"lambmax": lamb_max,
"ci": cons_ind,
"ri": ri,
"cr": cr,
}
json_data = json.dumps(data) # 将Python对象转换为JSON格式的字符串
return json_data
# 从命令行参数中获取字符串表示的二维数组
dataset_str = sys.argv[1]
dataset = ast.literal_eval(dataset_str)
# 将Python列表转换为NumPy数组
dataset = np.array(dataset)
wd = sys.argv[2]
vector,weights,lamb_max,cons_ind,ri,cr = ahp_method(dataset, wd)
# weightslist=weights.tolist()
response = create_json_response(vector,weights,lamb_max,cons_ind,ri,cr)
print(response)
远程api接口(python)
@app.route('/ahp_weight', methods=['POST'])
def ahp_weight():
json_data = request.get_json()
data = json_data.get('data')
flags = json_data.get('flags')
return aw.ahp_method(np.array(data),flags)
import sys
import json
import ast
import numpy as np
from functools import reduce
def ahp_method(dataset, wd = 'm'):
# 随机一致性指标R.I.(inc_rat)
inc_rat = np.array([0, 0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51, 1.48, 1.56, 1.57, 1.59])
# 数据深复制
X = np.copy(dataset)
# 生成权重向量
weights = np.zeros(X.shape[1])
# 根据权重计算方法来确定各个权重
if (wd == 'm' or wd == 'mean'): #均值
weights = np.mean(X/np.sum(X, axis = 0), axis = 1)
elif (wd == 'g' or wd == 'geometric'): #几何
for i in range (0, X.shape[1]):
weights[i] = reduce( (lambda x, y: x * y), X[i,:])**(1/X.shape[1])
weights = weights/np.sum(weights)
# 计算特征根向量
vector = np.sum(X*weights, axis = 1)/weights
# 获得平均特征根
lamb_max = np.mean(vector)
# 计算一致性指标
cons_ind = (lamb_max - X.shape[1])/(X.shape[1] - 1)
ri=inc_rat[X.shape[1]]
# 一致性判断
cr = cons_ind/ri
data = {
"vector": vector.tolist(),
"weights": weights.tolist(),
"lambmax": lamb_max,
"ci": cons_ind,
"ri": ri,
"cr": cr,
}
json_data = json.dumps(data) # 将Python对象转换为JSON格式的字符串
return json_data目录体系
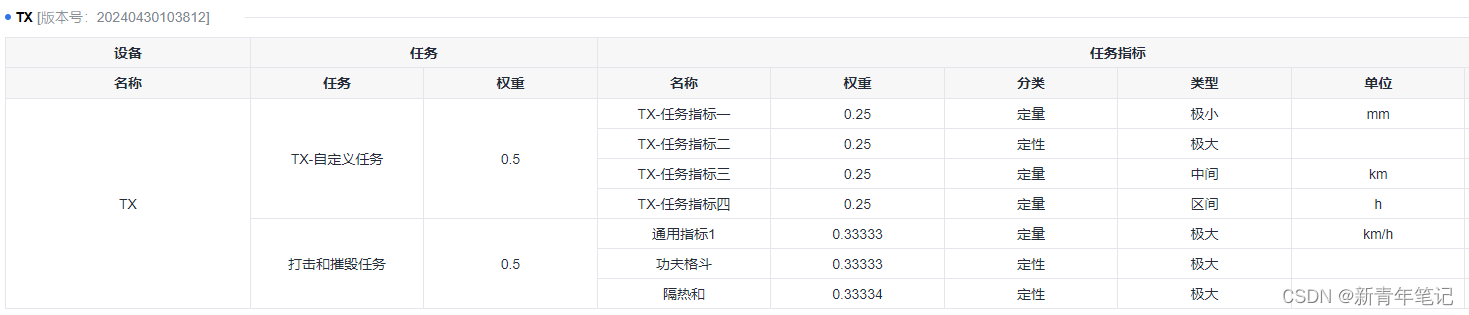
评估
目录系统形成后,可以上传样本数据,上传完成后可以对样本数据进行标准化处理-统一量纲。便于进行科学评估。
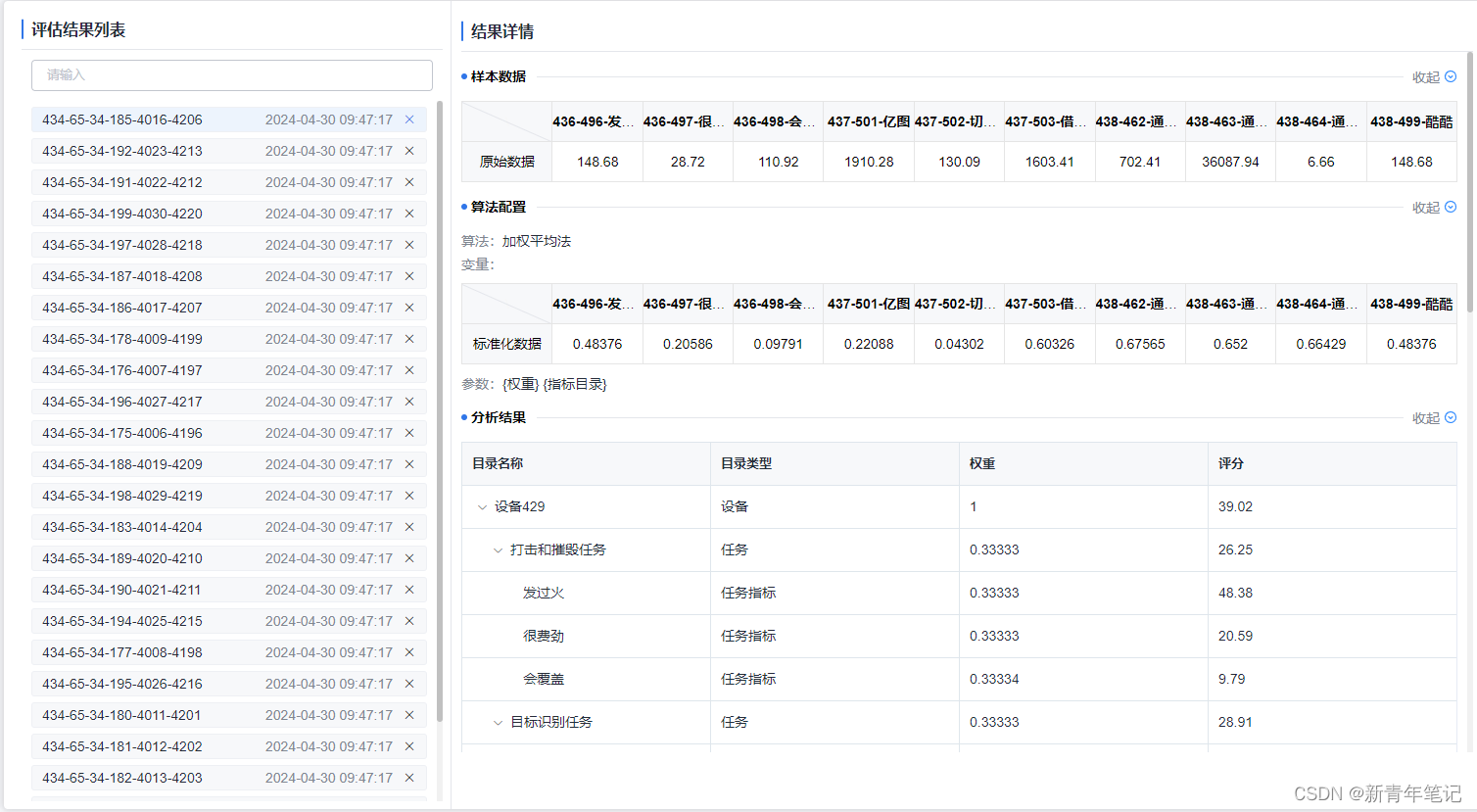















 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









