








常用医学数据增强算法
数据增强是对训练样本的各种有章法的变换,这就使得模型能够学到图像更本质的特征,增强模型对样本细微变换的适应性,减弱对变化的敏感。
传统数据增强算法
通过对图片进行针对图像整体的物理几何变换:翻转、平移、放大、缩小等。
还有针对图像像素增加噪声的增强方法:高斯噪声、椒盐噪声等。
这些传统数据增强算法作用有限,尤其是针对复杂模型,收效甚微。
mix up数据增强
该算法由Facebook人工智能研究院于2018年提出,发表在《mixup:beyond empirical risk minimization》文章中。主要内容是利用线性特征向量的混合导致相关目标的线性混合的先验原理,采用线性插值的方法的到新样本数据。很简单,说白了就是从训练样本中随机抽取两个样本进行简单的随机加权求和,同时样本的标签也对应加权求和,然后预测结果与加权求和之后的标签求损失,再反向求导更新参数。
1.随机取一个batch,将image的index打乱,对整个batch中的image进行加权求和。同时标注1为原始标注,标注2为与随机打乱后的image对应的标注。
2.将随机打乱的image输入到网络的到输出
3.pred = mixup_criterion对两个标注进行加权求和
4.最后根据loss函数计算(outputs,pred)的损失进行反向传播。
单个dataloader与两个式等效的。
对这种方法由两种理解:
1.label是用one-hot vector编码,可以理解为对K个类别的每个类给出样本属于该类的概率。加权后变成了类似于“two-hot”的信息,这可以认为样本同属于混合前的两个类别中。
2.不混合label,而是用加权的输入在两个label上分别计算cross-entropy loss,最后把两个loss加权作为最终的loss。
Samplepairing
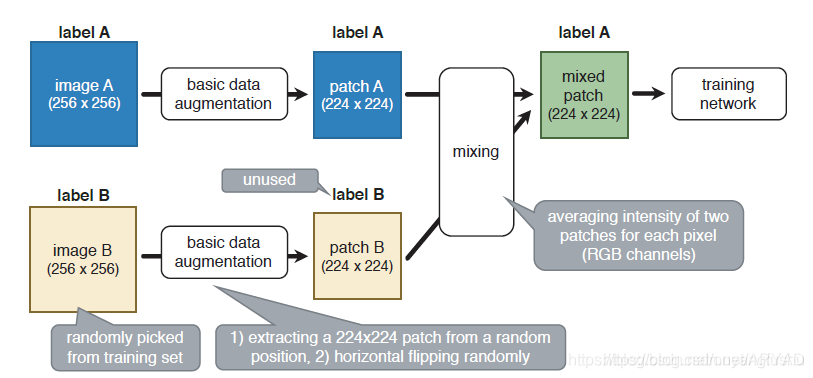
训练过程中:
1)首先仅仅用普通的数据增强(如随机裁剪和左右镜像)训练(无SamplePairing data augmentation)。
2)在没有SamplePairing情况下训练1个epoch或100个epoch之后,开启SamplePairing,即对成对样本求均值。
3)间歇性开启与关闭SamplePairing,直到训练稳定以后关闭SamplePairing,用普通数据增强进行funtune训练,微调模型。

















 5886
5886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









