







目录
1.前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
2. 设计思路
2.1 课题背景与意义
动车交通安全是一个日益重要的问题,而佩戴头盔是降低事故风险的有效措施。通过使用深度学习技术,该系统能够准确地检测和识别电动车驾驶员是否佩戴头盔。相较于传统方法,该系统具有更高的检测精度和实时性能。这一创新性的研究方向为电动车交通安全提供了一种新的解决方案,有助于提升交通安全意识和预防交通事故的发生。
2.2 算法理论原理
2.2.1 YOLOv5算法
YOLOv5s是YOLOv5系列中最小的网络模型,它在算法和网络结构上做了一些改进。下面是对YOLOv5s的改进进行总结和扩展的内容:
-
数据增强方式:YOLOv5s采用了Mosaic-9数据增强方式。Mosaic数据增强是一种将多张图片合成一张的方法,通过随机裁剪、缩放和平移等操作,生成更多样化和丰富的训练数据。这种数据增强方式能够提升模型的鲁棒性和泛化能力。
-
图片尺寸处理:YOLOv5s对输入的图片尺寸进行处理。它通过设定初始锚框并自动计算最佳锚框值,将输入图片尺寸变化为固定大小。这种处理方式有助于减少输入图片的尺寸变化对模型输出的影响,并提供一致的输入大小,方便网络模型的训练和推理。
-
锚框训练:YOLOv5s使用初始锚框进行训练,并与真实框进行比较。通过计算它们之间的差值,采用反向迭代的方式更新模型参数,使模型能够更好地预测目标的位置和大小。这种锚框训练策略可以提高目标检测的准确性和稳定性。
-
实时推理速度:为了提高实际检测时的推理速度,YOLOv5s通过训练检测模型来优化推理过程。通过对网络结构和参数的调整和优化,YOLOv5s在保持较高检测精度的同时,实现了更快的推理速度。这对于实时应用和大规模场景中的目标检测任务非常重要。
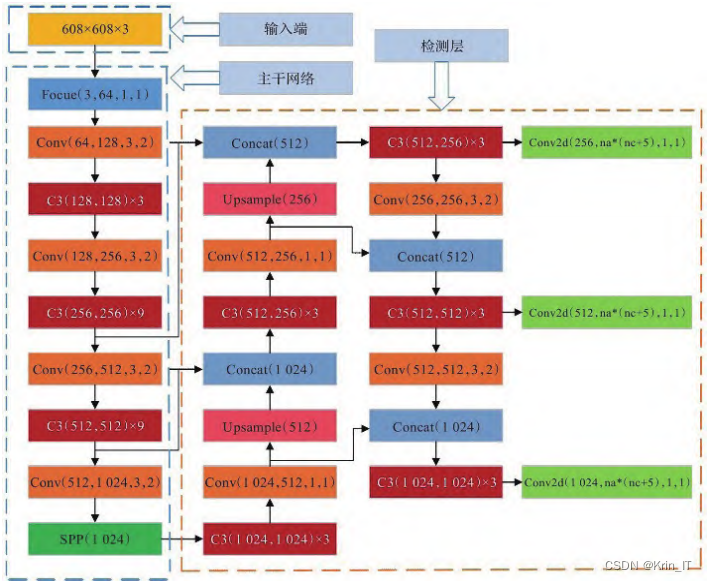
在YOLOv5中,经过Focus、切片和卷积操作处理后,保留了完整的图片信息,以实现特征提取。使用空间金字塔池化(SPP)技术融合多尺度信息,进一步增强了特征表达能力。在Neck部分,保留了空间信息,有助于提高检测性能。
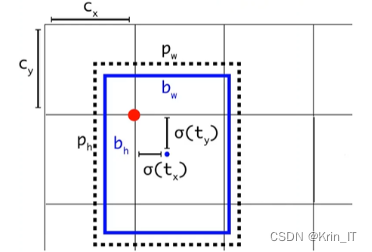
为了提高目标定位精度,YOLOv5引入了CIoU损失函数来评估目标框与检测框之间的重叠情况和中心距离。CIoU损失函数不仅考虑了框的重叠度(IOU),还引入了惩罚项,以缓解两个框不相交的问题,从而更准确地反映了预测框与真实框的相交情况。此外,在训练时采用动态调整策略,有助于进一步提高模型的性能和鲁棒性。
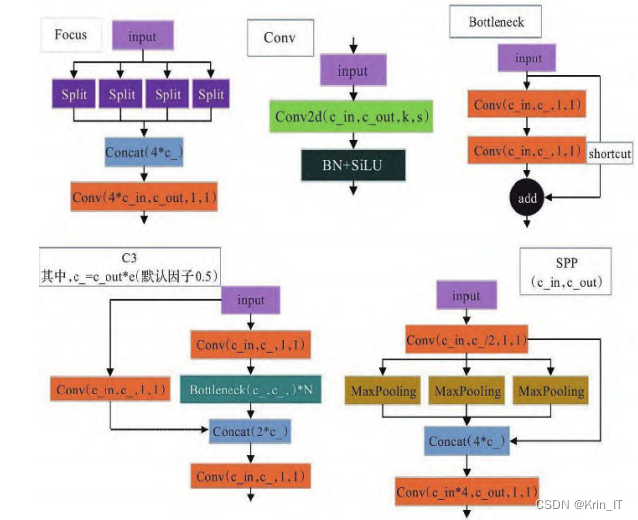
2.2.2 跨领域网格匹配策略
跨领域网格匹配策略是一种应用于目标检测任务的技术,旨在提高模型的准确性和鲁棒性。该策略的核心思想是将目标检测网络的特征图分割为多个不同尺度的网格,并将每个目标与最匹配的网格进行关联。
通过将特征图划分为多个尺度的网格,跨领域网格匹配策略能够更好地捕捉目标在不同尺度下的特征信息,并提供更精确的定位和上下文感知能力。通过将目标与最匹配的网格进行关联,可以有效减少误检率,提高目标检测的准确性。
相关代码:
def match_grid_strategy(targets, anchors, grid_size):
# 初始化匹配结果列表
match_results = []
# 遍历目标列表
for target in targets:
# 计算目标的宽度和高度
target_width = target.width
target_height = target.height
# 初始化最佳匹配的anchor和最佳匹配的IoU
best_anchor = None
best_iou = 0
# 遍历所有的anchors
for anchor in anchors:
# 计算anchor的宽度和高度
anchor_width = anchor.width
anchor_height = anchor.height
# 计算anchor和目标的IoU
intersection = min(target_width, anchor_width) * min(target_height, anchor_height)
union = target_width * target_height + anchor_width * anchor_height - intersection
iou = intersection / union
# 更新最佳匹配的anchor和最佳匹配的IoU
if iou > best_iou:
best_anchor = anchor
best_iou = iou
# 将最佳匹配的anchor添加到匹配结果列表中
match_results.append(best_anchor)
# 根据网格大小调整anchor的位置
adjusted_anchors = adjust_anchors(match_results, grid_size)
return adjusted_anchors
def adjust_anchors(anchors, grid_size):
# 初始化调整后的anchor列表
adjusted_anchors = []
# 遍历所有的anchors
for anchor in anchors:
# 计算调整后的anchor的中心坐标
adjusted_center_x = (anchor.center_x - anchor.grid_x) * grid_size
adjusted_center_y = (anchor.center_y - anchor.grid_y) * grid_size
# 创建调整后的anchor对象
adjusted_anchor = Anchor(adjusted_center_x, adjusted_center_y, anchor.width, anchor.height)
# 将调整后的anchor添加到列表中
adjusted_anchors.append(adjusted_anchor)
return adjusted_anchors2.3 检测的实现
2.3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己进行数据收集,并制作一个全新的数据集,专门用于电动车头盔的检测研究。为了获取大量的样本和多样性的场景,我采用了网络爬取的方式。通过网络爬取,我可以获取来自各种来源的电动车图片,涵盖不同的环境、角度和光照条件。我特别关注电动车驾驶员佩戴头盔的情况,并努力收集那些头盔佩戴正确和不正确的示例。此外,我还收集了一些其他相关安全设施的图片,例如手套、护目镜等。

自制的数据集将包含大量的电动车图片,其中将标注每个图像中的头盔位置和其他安全设施的信息。这样的数据集将为电动车头盔检测算法的研究提供准确、可靠的数据基础。
数据标注扩展是通过数据增强、伪标签、迁移学习和弱监督学习等方法,提高标注数据集的数量和多样性,以提升模型的泛化能力和性能。数据增强通过对原始数据进行变换和处理来生成新样本,而伪标签利用未标注数据的预测结果作为扩展的标注样本。迁移学习将源领域中学习到的知识迁移到目标领域中,而弱监督学习则利用部分标注和辅助信息来训练模型。这些方法可以有效利用有限的标注数据,扩展样本的范围和多样性,从而提高模型的性能和应用效果。

随机透视变换是一种常用的数据增强方法,通过应用旋转、缩放、平移、错切/非垂直投影和透视变换等单独的变换矩阵,使数据在图像空间中发生变化。

2.3.2 实验环境搭建

2.3.3 实验及结果分析
模型训练的消融实验是一种通过逐步去除或修改系统的组件来评估它们对模型性能的影响的方法。通过对数据集、数据增强、模型结构、损失函数和优化算法进行消融实验,可以了解各个组件的重要性和贡献,并优化系统设计以提高电动车佩戴头盔识别系统的性能。
在训练过程中,可以使用验证集对模型进行评估,计算模型在新数据上的性能指标,如准确率、精确率、召回率等。根据评估结果,可以进行模型调优,如调整超参数、增加训练迭代次数或采用正则化等技术来提高模型的性能。
在完成模型训练和调优后,使用独立的测试集对模型进行最终的评估。测试集应该是未参与模型训练和验证的数据,以评估模型在真实场景中的泛化能力。如果模型达到预期的性能要求,可以将其部署到实际应用中,用于进行推断和预测。
相关代码示例:
import torch
import torchvision.transforms as transforms
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from PIL import Image
# 加载预训练模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
# 替换模型的分类器
num_classes = 2 # 包括“带头盔”和“未带头盔”两个类别
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 加载模型权重
model.load_state_dict(torch.load('path_to_model_weights.pth'))
model.eval()
# 设置转换器
transform = transforms.Compose([transforms.ToTensor()])
# 加载并预处理图像
image = Image.open('path_to_image.jpg').convert('RGB')
image_tensor = transform(image)
# 添加批次维度
image_tensor = image_tensor.unsqueeze(0)
# 模型推理
with torch.no_grad():
predictions = model(image_tensor)
# 解析预测结果
scores = predictions[0]['scores']
labels = predictions[0]['labels']
boxes = predictions[0]['boxes']
# 阈值过滤和绘制边界框
threshold = 0.5 # 置信度阈值
for score, label, box in zip(scores, labels, boxes):
if score > threshold and label == 1: # 检测到未带头盔的骑电动车行人
x_min, y_min, x_max, y_max = box
print("未带头盔的骑电动车行人坐标:", (x_min.item(), y_min.item(), x_max.item(), y_max.item()))
# 显示图像
image.show()创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









