







一、认识 RAG:为什么要"检索 + 生成"
1、什么是 RAG
RAG 是 Retrieval-Augmented Generation 的缩写,中文翻译为"检索增强生成"。它是一种将检索系统和生成式 AI 模型结合的技术方案,主要包含两个核心步骤:
1.检索(Retrieval):根据用户输入的问题,从知识库中检索出相关的文档或信息片段
2.生成(Generation):将检索到的相关信息作为上下文,结合用户问题,让大语言模型生成准确的回答
这种方案既能让模型基于最新的知识作答,又可以提供可溯源的参考依据,有效解决了大语言模型的知识时效性和事实准确性问题。
下面这张图展示了 RAG 在对话过程中的工作流程:
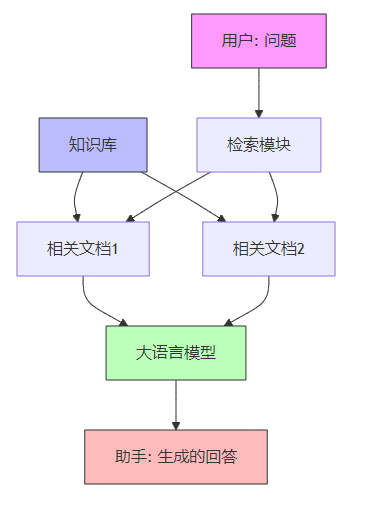
2、为什么需要 RAG
让我们对比三种问答方案的优缺点,来理解为什么 RAG 是一个更好的选择:
传统检索式问答 (Retrieval QA)
✅ 可靠性高:答案直接来自知识库,有明确的来源
✅ 知识可更新:添加新文档即可更新知识
❌ 灵活性差:只能返回知识库中已有的内容
❌ 表达生硬:难以用自然语言组织答案
纯 LLM 问答
✅ 表达自然:能用流畅的语言组织答案
✅ 灵活理解:可以理解各种表达方式的问题
❌ 知识固化:知识仅限于训练数据,无法及时更新
❌ 可靠性差:容易产生幻觉,难以验证答案准确性
RAG 方案
✅ 可靠且可溯源:答案基于检索到的具体文档
✅ 知识可更新:可以持续添加新的知识
✅ 表达自然:利用 LLM 的语言能力组织答案
✅ 灵活理解:能理解各种形式的问题
✅ 成本可控:主要消耗在必要的 API 调用上
RAG 通过将检索和生成相结合,既保留了传统检索问答的可靠性,又获得了 LLM 的灵活性和自然表达能力。它能让 AI 始终基于最新的、可信的知识来回答问题,同时保持对话的流畅自然。
3、RAG 的典型应用场景
企业知识库问答:帮助企业构建对内员工知识库或对外客户问答系统。
法律法规、论文等参考场景:需要给出权威来源或证据的回答。
任何需要"带有引用信息"的回答场景。
二、RAG 系统整体架构与数据流
1、核心组件
向量数据库:用来存储文档分块后的向量(如 ChromaDB、Qdrant)。
Embedding(文本向量化):将文本转化为可比较的数值向量,形如 [0.1, 0.2, 0.3, 0.4, 0.5]
检索 (Retrieval):根据用户查询的向量相似度,检索出最相关的文档切片。
大语言模型:将检索到的上下文与用户问题组合,再由模型 (LLM) 生成最终答案。
生成 (Generation) 与引用:如何在回答中嵌入引用链接或标注,方便用户溯源。
2、RAG 的典型工作流
1.用户输入问题。
2.将问题向量化,然后检索最相似的文档切片。
3.将检索到的上下文与问题拼接后输入 LLM。
4.LLM 输出带引用信息的回答。
5.前端渲染回答、可选地在可视化界面中展示引用详情。
下面用一张图展示各个组件的交互流程:
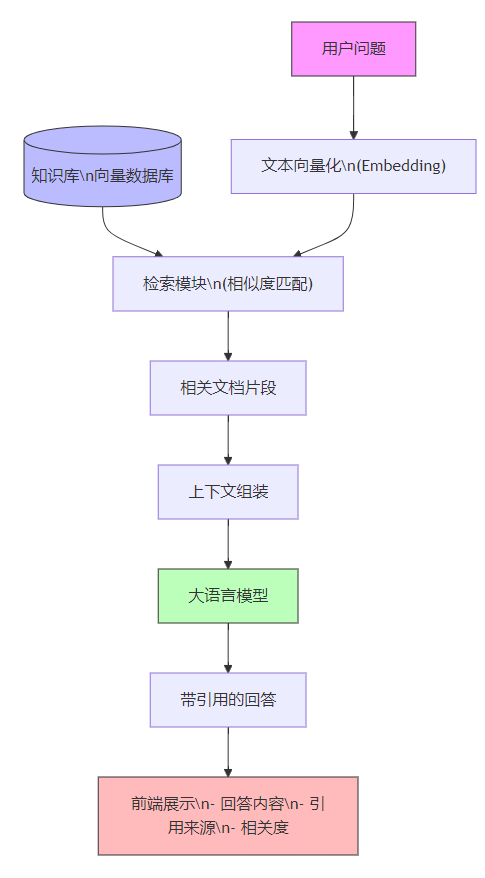
三、构建知识库:文档处理、嵌入、存储
1、文档上传与分块 (Chunking)
(1)为什么要对文档进行分块?
文档分块是 RAG 系统中的一个关键步骤,主要有以下几个原因:
1.向量相似度计算的精度
过长的文本会导致向量表示不够精确
较小的文本块能更好地捕捉局部语义
有助于提高检索的准确性
2.LLM 的上下文窗口限制
LLM 的输入长度是有限的 (虽然 Qwen 已经推出了 1M token 的上下文窗口 0.0)
需要将文档切分为适合 LLM 处理的大小
避免超出 token 限制导致信息丢失
3.检索效率与成本
更小的文本块便于建立细粒度的索引
只需检索最相关的片段,节省 token 用量
减少无关信息,提高回答质量
4.引用与溯源 (这个是 RAG 的特色功能)
便于定位信息的具体来源
可以给出更精确的引用范围
有助于用户验证答案的可靠性
(2)常见的分块策略
1.固定长度分块
按字符数或 token 数进行切分
实现简单,但可能切断语义完整的段落
适合结构统一的文档
2.语义分块
按段落、章节等自然语义单位切分
保持上下文的连贯性
需要考虑文档的具体结构
3.重叠分块
相邻块之间保留一定重叠
避免关键信息被切分
增加了存储和计算开销
4.递归分块
先大块后细分
保持层次结构
适合长文档处理
选择合适的分块策略需要考虑:
文档的类型和结构
向量数据库的特性
LLM 的上下文窗口大小
检索效率与成本的平衡
例如如果是 markdown,可以按段落进行分块,如果是一般文档,可以按章节进行分块。
+--------------------------------------------------+
| # Chapter 1 Title |
| Main content... |
| Main content... |
| |
| ## 1.1 Section Title |
| - List item 1 |
| - List item 2 |
| |
| ### 1.1.1 Subsection Title |
| Main paragraph... |
| |
| # Chapter 2 Title |
| Another paragraph... |
+--------------------------------------------------+
|
v
Chunking 切片
|
v
+------------------+ +-------------------+ +------------------+
| Chunk 1: | | Chunk 2: | | Chunk 3: |
| # Chapter 1 | | ## 1.1 Section | | # Chapter 2 |
| Title | | Title | | Title |
| Main content... | | - List item 1 | | Another |
| Main content... | | - List item 2 | | paragraph... |
+------------------+ | | +------------------+
| ### 1.1.1 |
| Subsection Title |
| Main paragraph... |
+-------------------+
2、文本向量化 (Embedding)
文本向量化是将自然语言文本转换为高维向量空间中的数值向量的过程。这种转换使得我们可以:
用数学方法计算文本之间的语义相似度
在向量空间中进行高效的相似度搜索
保留文本的语义信息和上下文关系
常用的文本向量化模型包括:
1.OpenAI Embeddings
text-embedding-ada-002 模型
1536 维向量输出
适用于英文等多种语言
语义表达能力强
2.Sentence Transformers
开源的句子级别编码器
支持多语言
可以根据场景微调
计算效率高
3、向量数据库
在文本 Embedding 之后,需要将向量存储到向量数据库中,以便后续的检索和相似度计算。
在 RAG Web UI 中,主要是用的 ChromaDB 作为向量数据库, 同时支持使用 Factory 模式, 支持多种向量数据库,例如:
ChromaDB
Qdrant
Milvus
Faiss
Annoy
Pinecone
Zilliz
数据库除了存储向量,还要携带某些元信息(文档来源、段落位置等)方便查阅, 一般情况下,我们会存入这样的数据结构到向量数据库中:
除了向量之外, 我们还需要存入一些元数据, 例如:
{
"id": "chunk_id",
"text": "段落内容",
"metadata": {"source": "文档来源", "position": "段落位置", "hash": "段落哈希值"}
}
四、检索与重排序:用最相关的上下文喂给大模型
1、相似度检索 (Similarity Search)
常用的相似度度量:余弦相似度、向量距离 (欧几里得距离) 等。
ChromaDB 支持多种相似度计算方法:
1.Cosine Similarity (余弦相似度)
计算两个向量夹角的余弦值
值域范围为 [-1,1],越接近 1 表示越相似
不受向量长度影响,只关注方向
计算公式: cos(θ) = (A·B)/(||A||·||B||)
2.L2 Distance (欧氏距离)
计算两个向量间的直线距离
值越小表示越相似
受向量长度影响
计算公式: d = √(Σ(ai-bi)²)
3.IP (Inner Product, 内积)
两个向量对应位置相乘后求和
值越大表示越相似
受向量长度影响
计算公式: IP = Σ(ai×bi)
ChromaDB 默认使用 Cosine Similarity,这也是最常用的相似度计算方法,因为:
计算简单高效
不受向量绝对大小影响
对于文本语义相似度计算效果好
结果容易解释和标准化
在实际使用中,可以根据具体场景选择合适的相似度算法:
如果向量已归一化,三种方法等价
对向量长度敏感时选择 Cosine
关注绝对距离时选择 L2
需要快速计算时可用 IP
2、重排序 (Re-ranking) 重要吗?
重排序是一个重要的步骤,可以显著提升检索结果的质量。其工作原理如下:
1.初步检索
首先使用向量相似度搜索召回一批候选文档(如前20-100条)
这一步计算快速但可能不够精确
2.Cross-Encoder 重排序
对召回的候选文档进行更精细的相关性打分
Cross-Encoder 会同时看到 query 和文档内容,计算它们的匹配度
相比向量相似度,能更好地理解语义关联
但计算开销较大,所以只用于重排少量候选
3.应用场景
多路召回:不同检索方式召回的结果需要统一排序
高精度要求:需要更准确的相关性排序
复杂查询:简单向量相似度可能不足以理解查询意图
4.常见实现
使用预训练的 Cross-Encoder 模型(如 BERT)
可以针对具体任务进行微调
输出相关性分数用于重新排序
虽然重排序会增加一定延迟,但在对准确度要求较高的场景下,这个成本通常是值得的。
3、拼接上下文与用户问题
在检索到相关文档片段后,需要将它们与用户问题拼接成合适的 prompt,以供 LLM 生成回答。
用户问题 + 检索到的上下文 = Prompt,最终由 LLM 输出回答。
以下是一些常见的拼接策略:
1.基本结构
System: 系统指令,说明 AI 助手的角色和任务
Context: 检索到的相关文档片段
Human: 用户的实际问题
Assistant: AI 的回答
2.拼接技巧
我们在项目中做了一个有意思的事情,就是可以使用 [[citation:1]] 这样的格式来引用检索到的上下文。
然后用户可以在前端通过 Markdown 的格式来展示引用信息, 并且通过弹窗来展示引用详情。
五、实际落地
这个项目中,用的都是目前最为流行的技术栈, 例如:
前端:React(Nextjs) + TailwindCSS + AI SDK
后端:FastAPI + LangChain + ChromaDB/Qdrant + MySQL + MinIO
部署:Docker + Docker Compose
让我们通过一个完整的工程实现示例,来理解 RAG 在知识库问答中的具体应用流程。我们将按照数据流的顺序,逐步解析关键代码的实现。
1、文档上传 → 异步处理
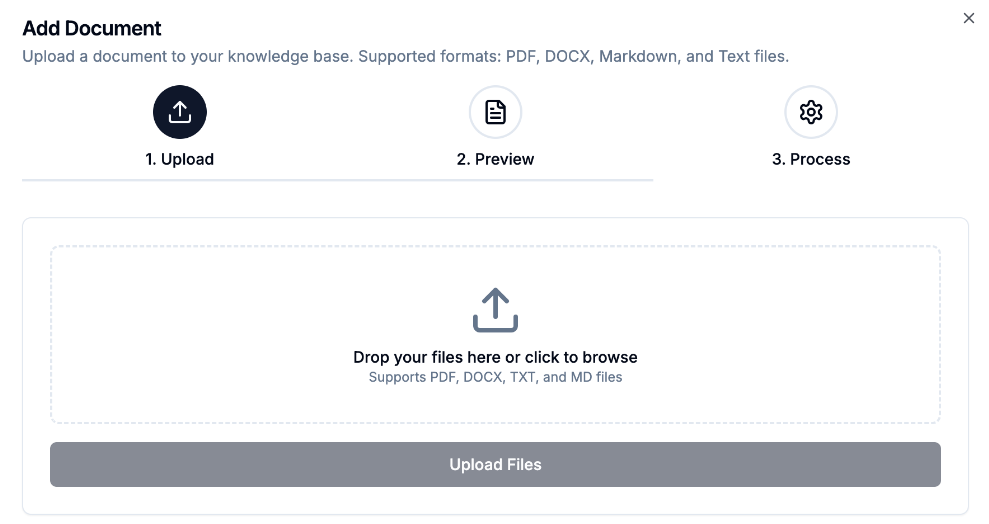
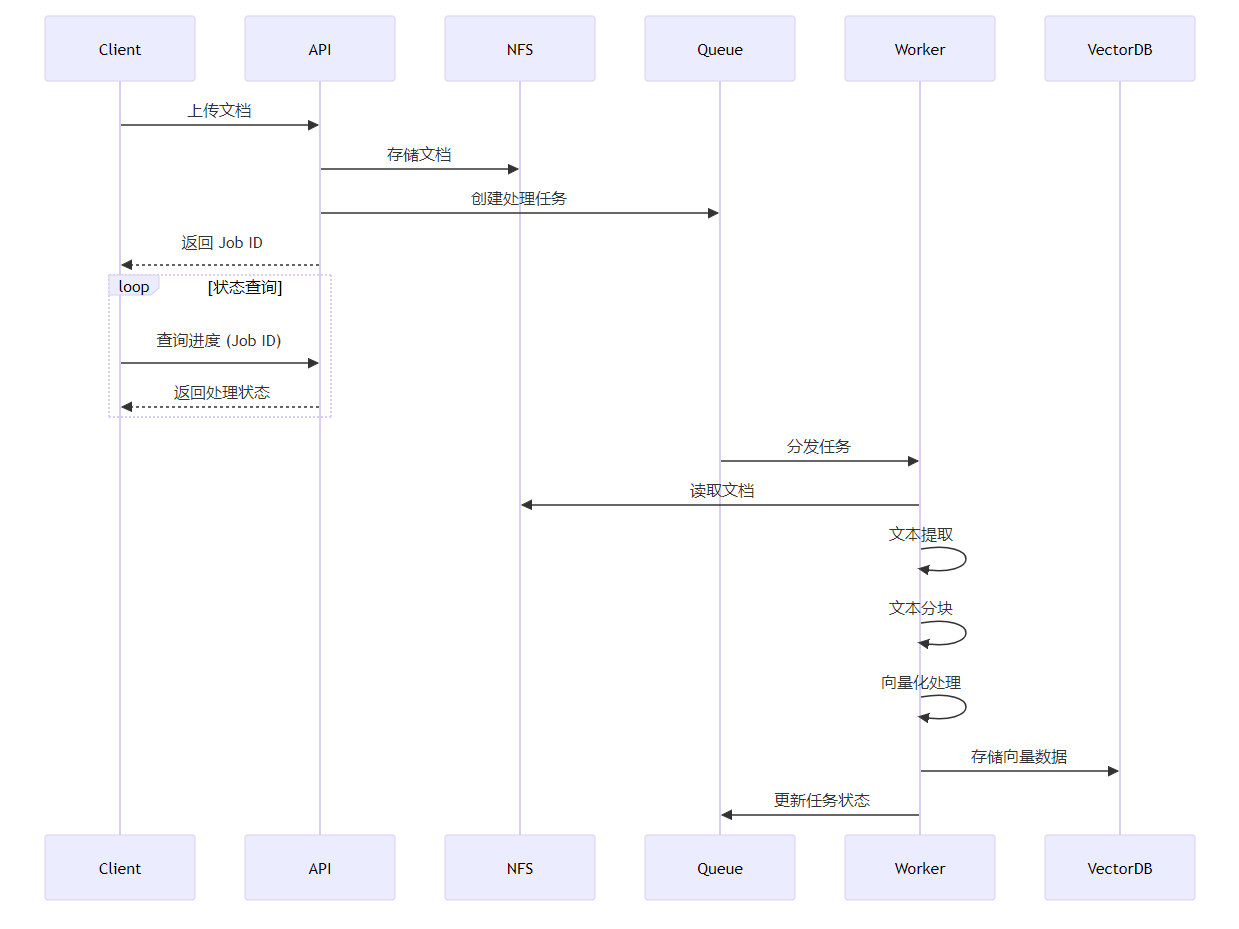
1.用户上传文档 (PDF/MD/TXT/DOCX)
客户端发起文档上传请求
文档被临时存储到 NFS (Network File System)
系统生成并返回一个 Job ID 给客户端
2.异步处理流程启动
文档预处理:提取文本、清洗数据
文本分块:按照设定的策略进行分段
向量化:通过 Embedding 服务将文本转换为向量
存储:将向量数据保存到向量数据库
3.状态查询
客户端通过 Job ID 轮询任务状态
系统返回当前进度 (Processing/Completed/Failed)
这种异步处理的设计有以下优点:
支持大文件处理:不会因处理时间过长导致请求超时
提升用户体验:用户可以实时查看处理进度
系统解耦:文档处理与存储服务可以独立扩展
错误处理:失败任务可以重试,不影响其他上传
在代码实现中,主要涉及以下几个关键组件:
文件上传接口
任务队列系统
异步处理服务
状态查询接口
这种设计让整个文档处理流程更加健壮和可扩展。
当然这里也设计也有设计到一些小细节,例如在处理文档的时候,可能很多系统都会选择先删后增,但是这样会导致向量数据库中的数据被删除,从而导致检索结果不准确。所以我们这里会通过一个临时表来实现这个功能,确保新的文件被处理后,旧的文件才被删除。
2、用户提问 → 检索 + LLM 生成
从前端使用 AI SDK 发送到后台,后台接口接收后会进行,用户 Query 的处理流程如下:
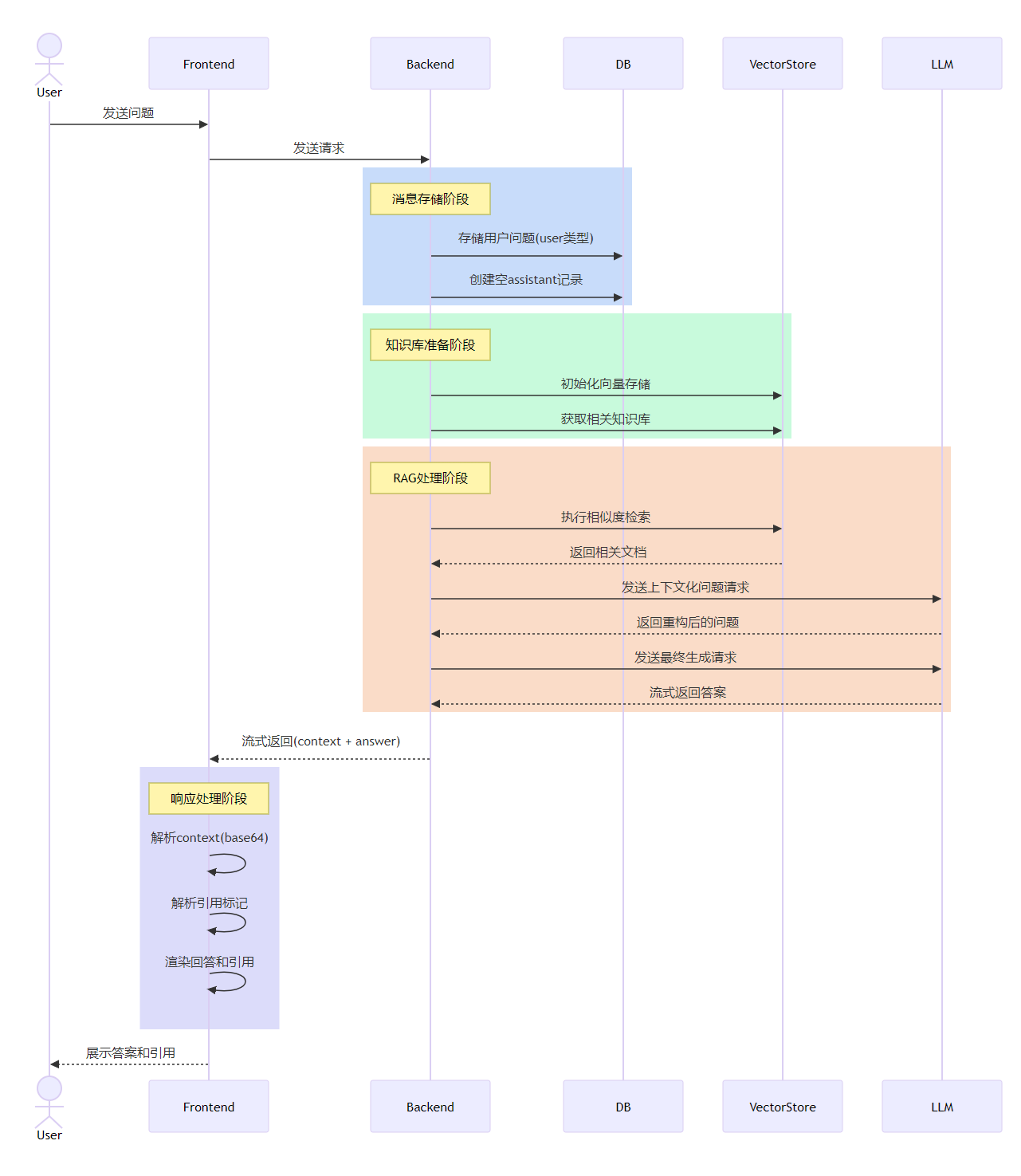
1.消息存储
将用户的提问内容保存为 user 类型的消息记录
创建一个空的 assistant 类型消息记录作为占位符
2.知识库准备
根据传入的 knowledge_base_ids 获取相关知识库
初始化 OpenAI Embeddings
为每个知识库创建对应的向量存储 (Vector Store)
3.检索增强生成 (RAG) 处理
使用向量存储创建检索器 (Retriever)
构建两个关键提示词模板:
contextualize_q_prompt: 用于理解聊天历史上下文,重新构造独立的问题
qa_prompt: 用于生成最终答案,包含引用格式要求和语言适配等规则
4.响应生成
处理历史聊天记录,构建对话上下文
使用流式响应逐步生成内容
响应内容包含两部分:
相关文档上下文 (base64 编码)、LLM 生成的回答内容
5.结果处理
实时返回生成的内容片段
更新数据库中的 assistant 消息记录
完整响应格式: {context_base64}__LLM_RESPONSE__{answer}
6.异常处理
捕获并记录生成过程中的错误
更新错误信息到消息记录
确保数据库会话正确关闭
前端接收到后台返回的 stream 返回以后,可开始解析这个 stream 后, 除了正常和其他 QA 聊天工具一样, 这里还多了一个引用信息, 所以需要解析出引用信息, 然后展示在页面上。
他是怎么运作的呢?这里前端会通过 __LLM_RESPONSE__ 这个分隔符来解析, 前面一部分是 RAG 检索出来的 context 信息(base64 编码, 可以理解为是检索出来的切片的数组),后面是 LLM 按照 context 回来的信息, 然后通过 [[citation:1]] 这个格式来解析出引用信息。

参考资料
https://github.com/rag-web-ui/rag-web-ui/blob/main/docs/tutorial/README.md


















 5940
5940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











