







一、Rerank简介
1、简介
有一些专门用于做Rerank的大模型,比如bge-reranker-v2-m3适用于中英文双语rerank场景。
rerank 模型的效果排名可以参考 MTEB 排行榜。
与embedding模型不同,reranker使用问题和文档作为输入,直接输出相似度而不是embedding。
reranker是基于交叉熵损失进行优化的,因此相关性得分不受特定范围的限制。
2、为什么需要重排序
1、大模型token长度限制
由于检索得到的chunks 并没有经过细致信息的筛选,同时LLM 的输入token长度具有限制。
因此一般而言有必要使用更准确的方式对chunks与query的关系进行rerank,以此增加MMR以及命中率。
2、cross encoder 模型耗资源
一般而言 rerank 是使用 cross encoder 模型对query 和召回的 chunk 进行逐个排序。
由于cross encoder相对普通的embedding模型而言更耗资源,推理花费的时间远大于一般模型,因此通常放在最后环节,只对最终的候选 chunks 进行排名。
考虑成本,大部分cross encoder模型只能接受不超过512长度的输入。
rerank也可以使用embedding方式或者openai gpt等大语言模型方式,亦或其它简单算法模型进行重排(混合搜索中rrf排名也可以当作rerank)
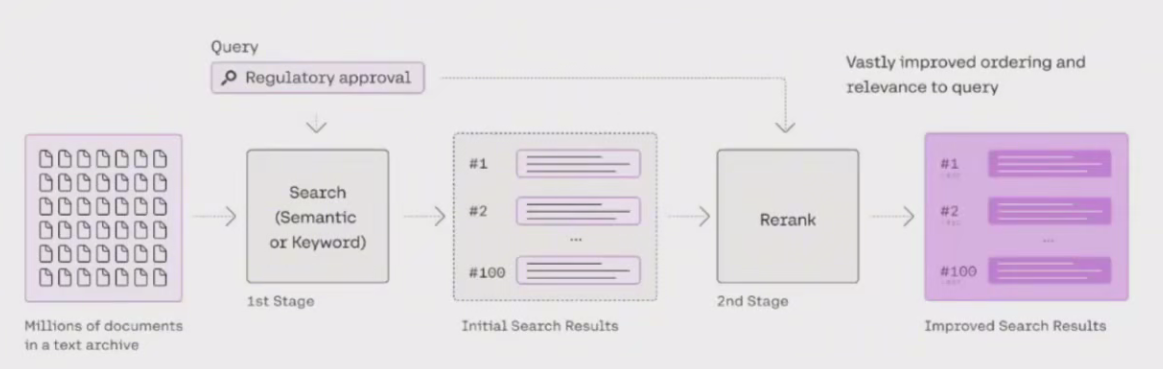
在RAG方法中,可以检索大量上下文,但并非所有上下文都与问题相关。重新排序允许对文档进行重新排序和过滤,将相关的文档放在最前面,从而提高RAG的有效性。
3、rerank 小范围内精确计算
因为搜索存在随机性,在 RAG中第一次召回的结果往往不太满意。
索引有数百万甚至千万的级别,那你只能牺牲一些精确度,换回时间。
增加top_k的大小,比如从原来的 10个,增加到 30个,然后再使用更精确的算法来做rerank,使用计算打分的方式,做好排序。比如 30次的遍历相似度计算的时间,我们还是可以接受的。
4、混合搜索时
混合检索通过融合多种检索技术的优势,能够提升检索的召回效果。
在应用不同的检索模式时,必须对结果进行整合和标准化处理。
标准化是指将数据调整到一致的标准范围或格式,以便于更有效地进行比较、分析和处理。
需要引入一个评分系统,即重排序模型(Rerank Mode1),它有助于进一步优化和精炼检索结果,当然也可以简单用(RRF)。
而是在混合搜索之后加入Rerank算法能有效提升检索效果,其中top_3的Hit Rate指标增加约4%。
3、向量数据库检索算法
近似近邻算法
Elasticsearch相似度检索算法,多数情况下score最高的chunk相关度没问题,但是top2-5的相关度就很随机了,这是最影响最终结果的。
一般相似度算法是KNN算法,但对于海量检索会使用近似近邻,在es8的相似度检索中,用的其实是基于HNSW(分层的最小世界导航算法),HNSW是有能力在几毫秒内从数百万个数据点中找到最近邻的。
HNSW带来随机性问题
Hierarchical Navigable Small World
我们想象这么一个场景:
你昨天刚在其他地方看到过一本新书,你想在图书馆找到类似的书。
K-最近邻(KNN)算法的逻辑是浏览书架上的每一本书,并将它们从最相似到最不相似的顺序排列,以确定最相似的书(最有可能是你昨天看过的那本)。
这也就是我们常说的暴力搜索,你有耐心做这么麻烦的工作吗?
对图书馆中的图书进行预排序和索引,要找到与你昨天看过的新书相似的书,就是去正确的楼层,正确的区域,正确的通道找到相似的书。
不需要对前10本相似的书进行精确排名,比如100%、99%或95%的匹配度,而是通通先拿回来,这就是近似近邻(ANN)的思想。
这里已经出现了一些随机性一一不做匹配分数的排名。但是这些准确度上的损失是为了让检索效率更快。
为了显著降低计算成本,它恓牲了找到绝对最近邻的保证,这算是在计算效率和准确性之间取得平衡。
ANN算法目前主要有三种:
1、基于图的算法创建数据的图表示,最主要的就是分层可导航小世界图算法(HNSW)。
2、基于哈希的算法:流行的算法包括,位置敏感哈希(LSH)、多索引哈希(MIH)。
3、基于树的算法:流行的是kd树、球树和随机投影树(RP树)。对于低维空间(≤10),基于树的算法是非常有效的。
HNSW算法:
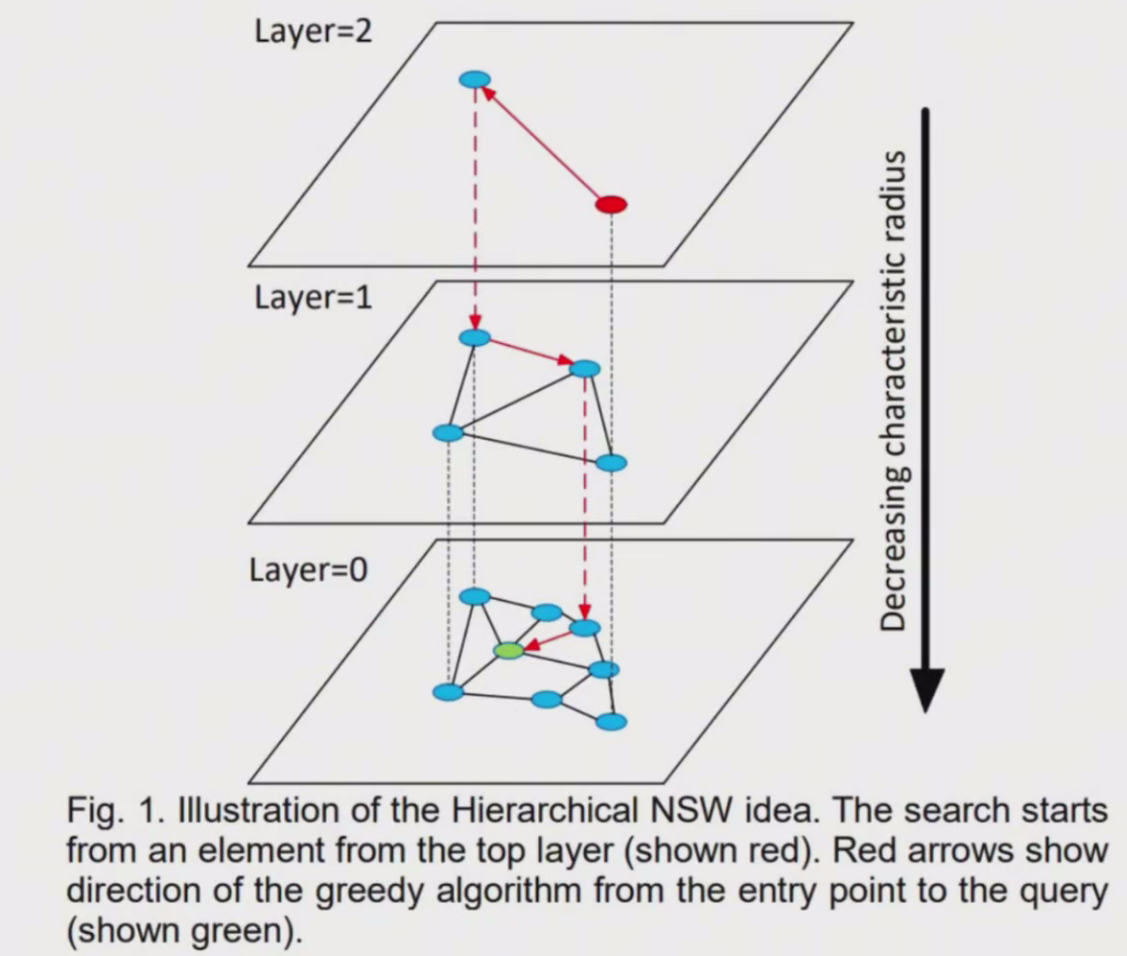
第0层中包含图中所有节点。
向上节点数依次减少,遵循指数衰减概率分布。
建图时新加入的节点由指数衰减概率函教得出该点最高投影到第几层。
从最高的投影层向下的层中该点均存在。
搜索时从上向下依次查询。
4、Rerank模型原理
早期交互模型(例如Cross-encoders)和后期交互模型(例如ColBERT)采用嵌入包方法。
ColBERT是一种多向量排序横型,因为引入了延迟交互机制(late interaction architecture)相比与cross-encoder效率提升了很多。
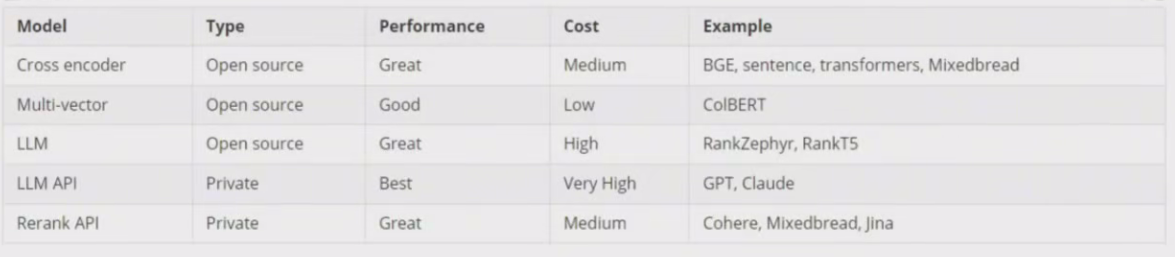
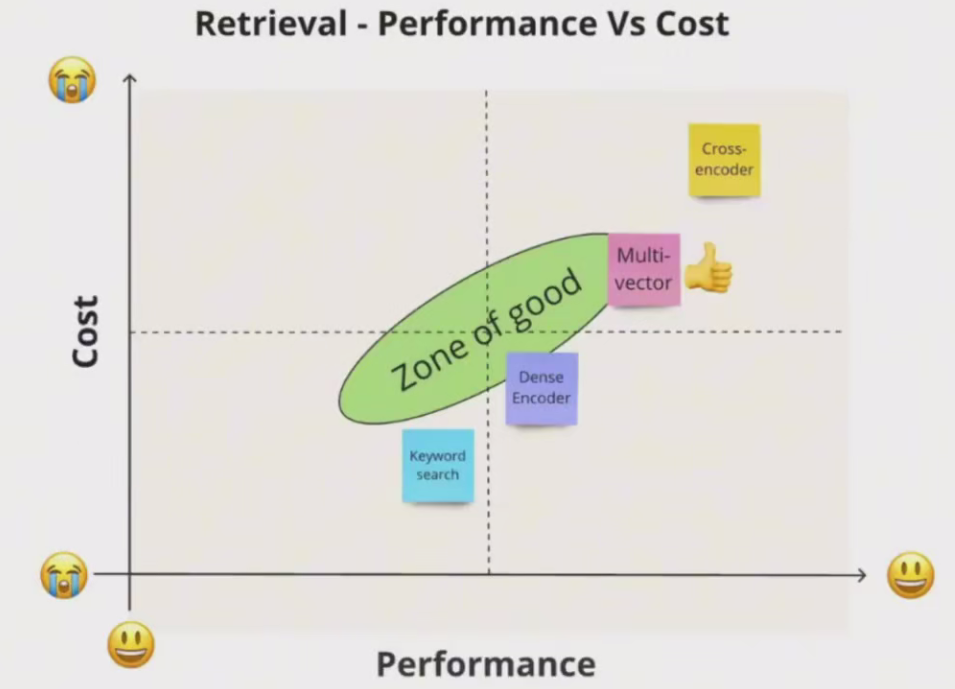
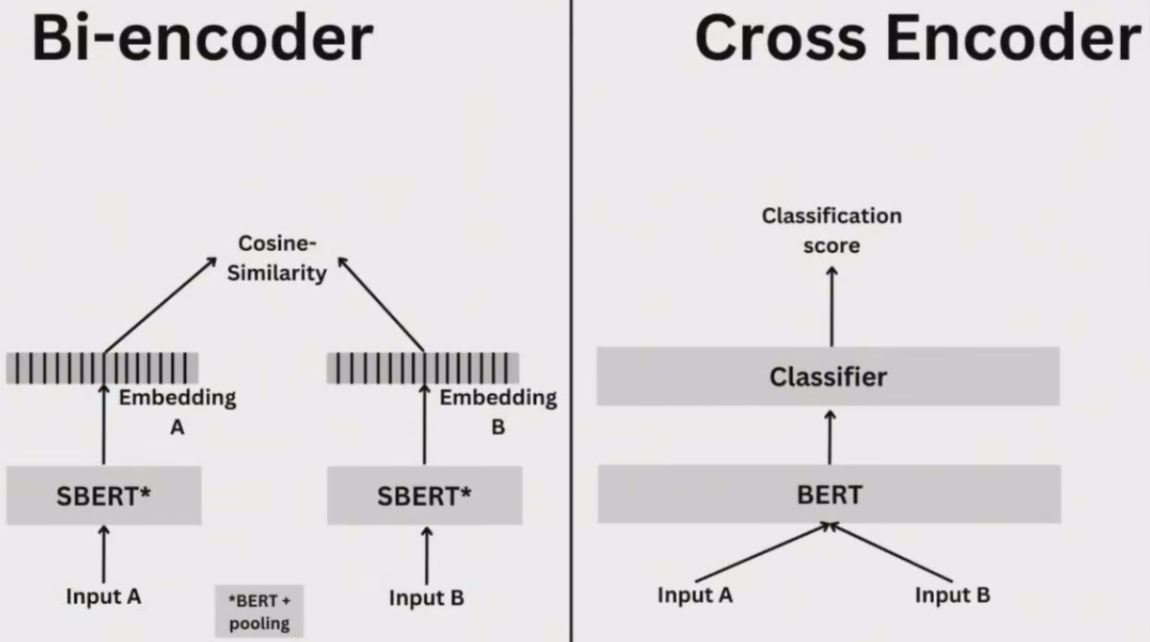
Sentence Transformers 支持两种类型的模型:Bi-encoders和Cross-encoders。
Bl-encoders更快更可扩展,但Cross-encoders 更准确。
Bi-encoders 更适合搜索,而Cross-encoders 更适合分类和高精度排序
如何选择?
Bi-encoder:
当您拥有大规模数据集和计算资源时,使用Bi-encoder。由于相似性得分可以独立计算,它们在推理期间通常更快。它们适用于捕获查询和文档之间复杂交互不太关键的任务。
Cross-encoder:
当捕获查询和文档之间的交互对于您的任务至关重要时,请选择Cross-encoder,它们在计算上更为密集,但可以在理解查询和文档之间的上下文或关系至关重要的场景中提供更好的性能。
由于交叉编码更精确,它同样适用于一些微小差异很重要的任务,比如医疗或者法律文档,其中一点微小的差异可以改变句子的整个意思。
embedding模型在获取embeding向量时,仅仅考虑了当前的文本,rerank模型则是把query跟相关的文档信息一起做了比较。
rerank模型则是在最后学习一个映射,输出的就是0-1的相似性判断。简单来说就是rerank功能更明确,效果也更好。
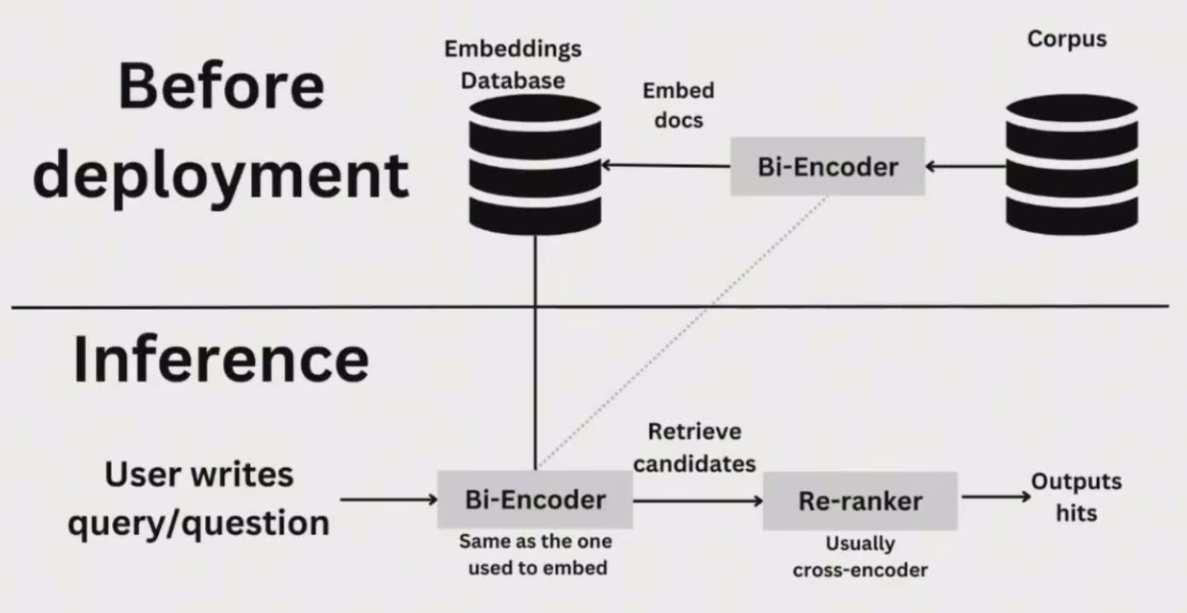
5、使用LLM作为ranker
LLM 自主改进文档重排序,策略分为三类:逐点方法、逐列表方法和成对方法。
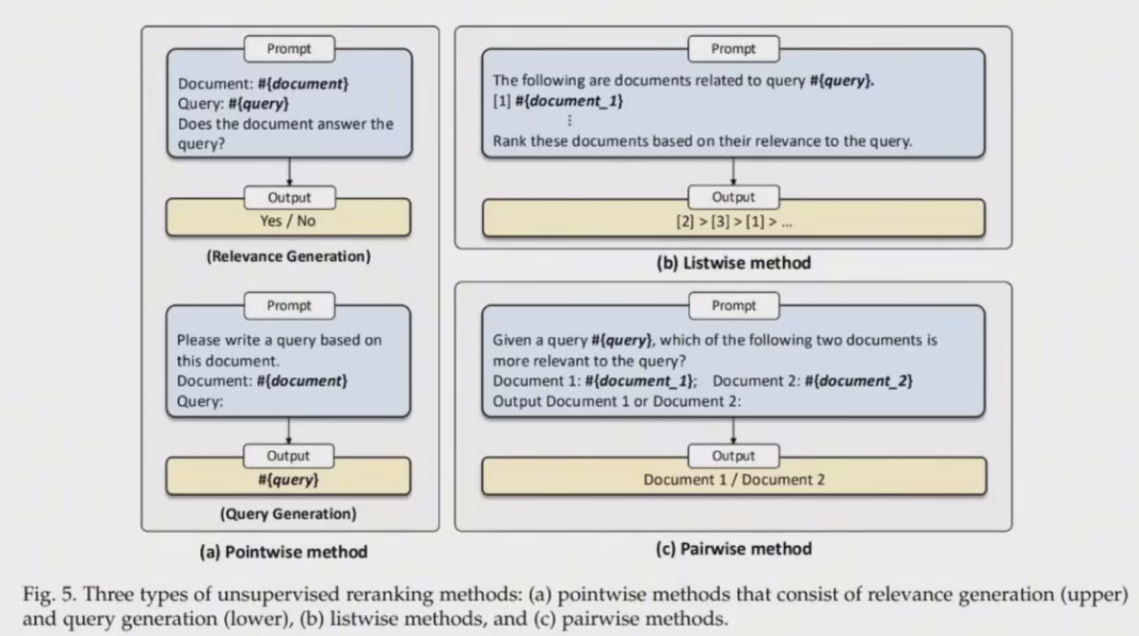
逐点方法
逐点方法测是查询与单个文档之间的相关性,子类别包括相关性生成和査询生成,两者在零样本文档重新排序中都很有效,图a。
列表方法
列表式方法通过将查询和文档列表插入提示并指示LLM 输出重新排序的文档标识符来直接对文档列表进行排序。由于 LM 的输入长度有限,将所有候选文档插入提示是不可行的,为了解决这个问题,这些方法采用滑动窗口策略每次对候选文档的子集进行重新排序,这涉及使用滑动窗口从后向前排序,并且每次仅对窗口内的文档进行重新排序。图b。
成对方法
在成对方法中,LLM 会收到包含查询和文档对的提示,然后,它们会被指示生成被认为更相关的文档的标识符。使用 AllPairs 等聚合方法对所有候选文档进行重新排序。AllPairs最初会生成所有潜在文档对,并合并每个文档的最终相关性分数,通常使用堆排序和置泡排序等高效排序算法来加快排名过程,图c。


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











