







前向传播和反向传播
输入层, 隐藏层, 输出层之间是怎样流动的
前向传播
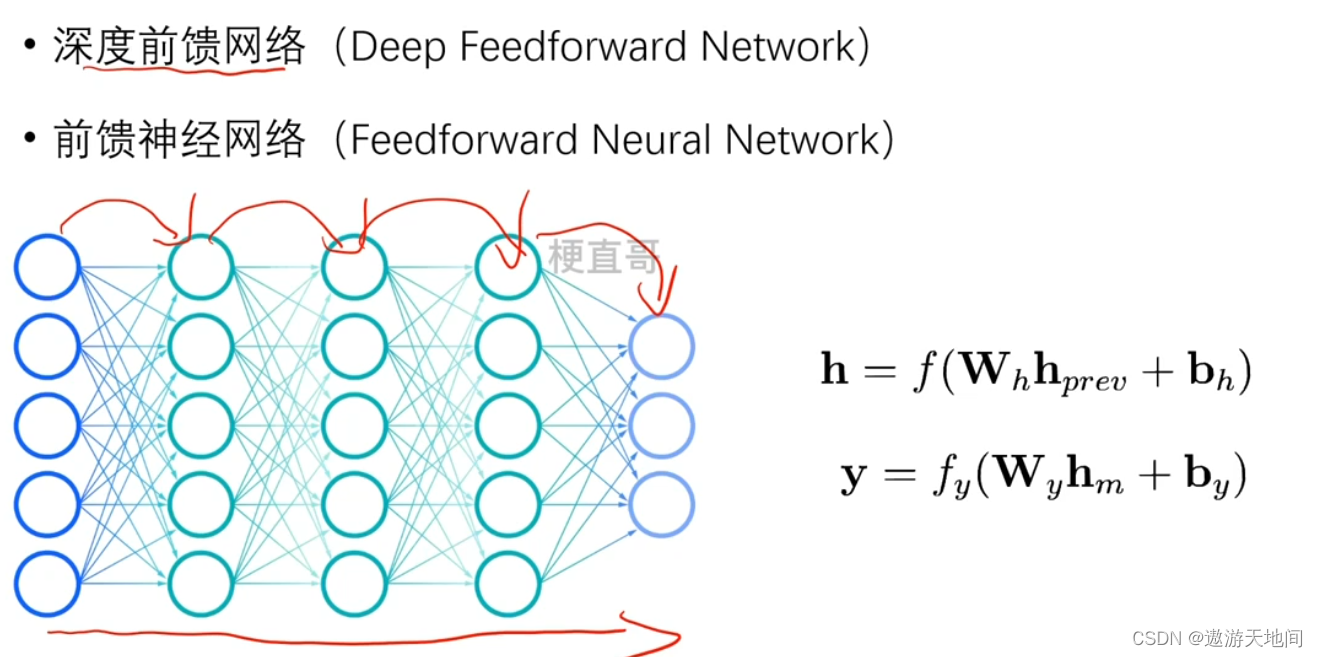
神经网络运行跳层
Wh 权重, Hprev 前一层输出, Bh 偏置, h 本层输出
y 最后输出
损失函数
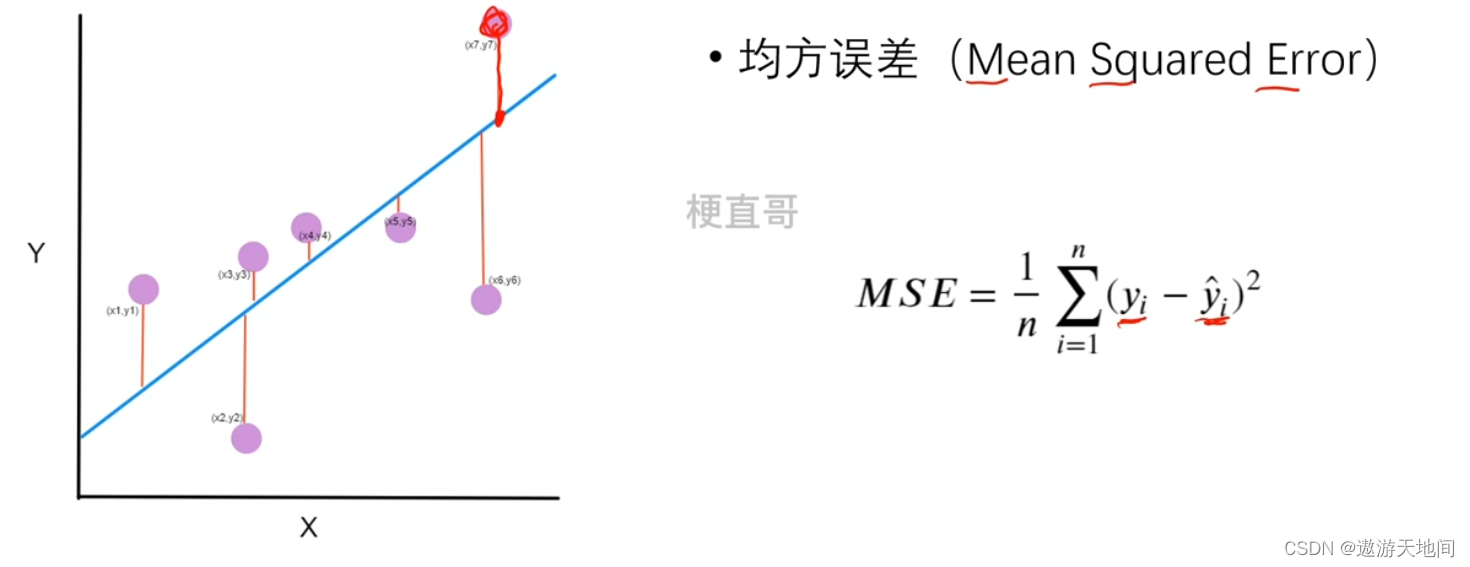
神经网络训练往往以随机参数开始, 初始输出结果不好, 训练过程中经常用损失函数衡量 预测结果和 真实结果的差距
 第i个样本的真实结果
第i个样本的真实结果
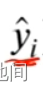 模型预测输出值
模型预测输出值
蓝色是预测值, 误差累加和求平均就是 均方误差。 损失可以评估网络性能, 希望通过训练使 MSE 尽可能小, 因此需要找到方法有效的不断更新 网络权重 和 偏置, 是损失函数不断减小, 就是反向传播算法 与梯度下降算法
反向传播(Back Propagation)
梯度 : 偏导数
使用链式法则,从最后的损失函数开始,逐层往前计算各个神经元的 权重和偏置,这些模型参数的偏导数, 构成损失函数对权值的梯度作为进一步修改 模型参数的依据
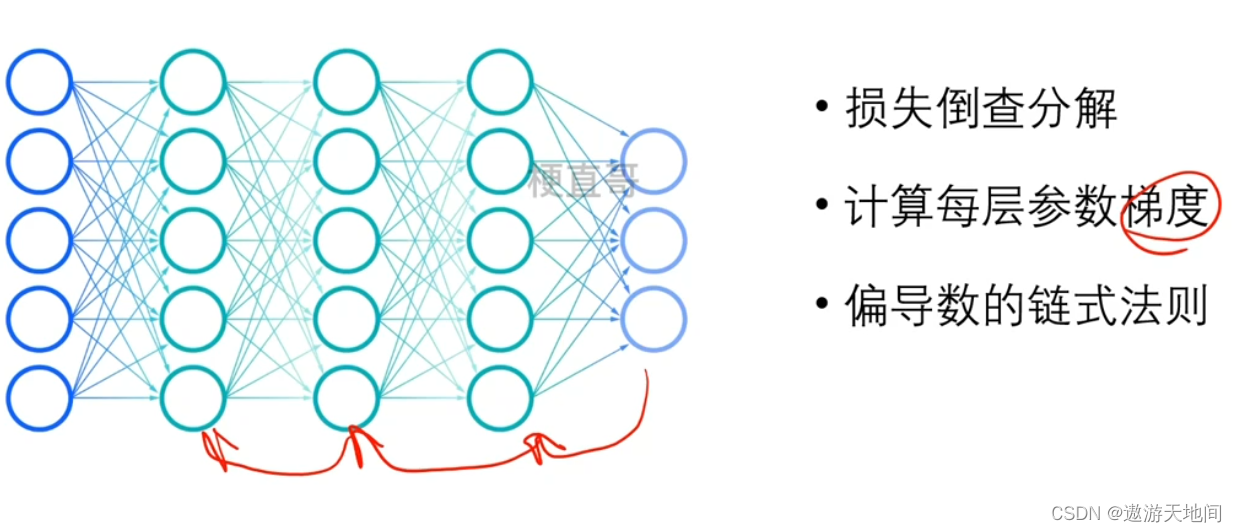
反向传播原理
理解原理
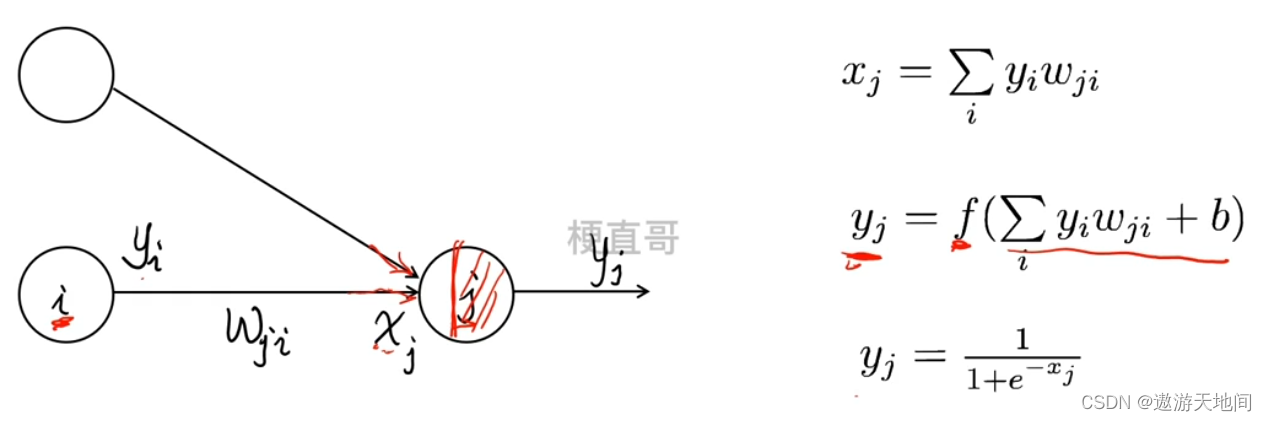
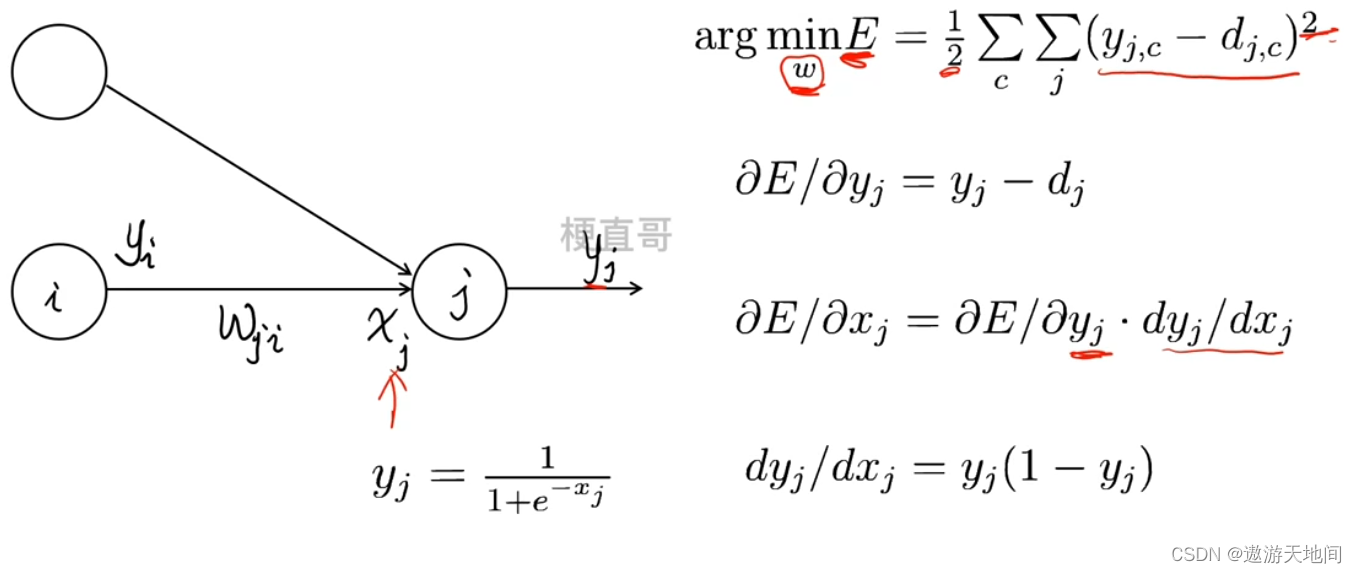
Xj 所有链接的加权和
每个神经元和分 2部分, 前面是线性组合, 后面是激活函数
神经网络训练的目标是找到一组权重参数 w 能够确保任何一个输入向量 产生的输出向量 Yj 都能和想要的目标输出向量 完全一样或足够接近
最小化损失函数
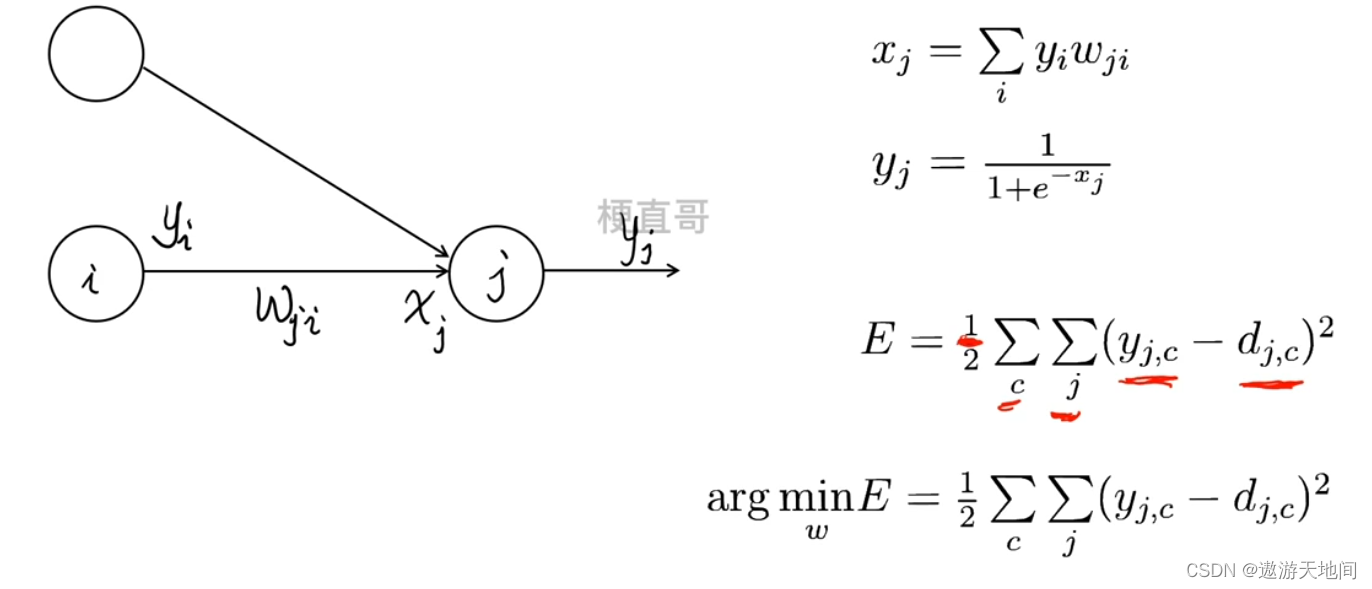
 左边例子的网络预测输出
左边例子的网络预测输出
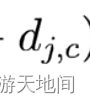 样本类别的真实值
样本类别的真实值
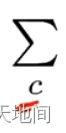 所有训练的样本
所有训练的样本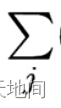 输出神经元的索引
输出神经元的索引
E 总损失, 使E 最小的参数就是我们需要的, 求助最优化方法来求解, 通过求权重的偏导数, 逐步逼近求解
通过这种方式, 把机器学习问题转换成 最优化问题
链式法则
这部分不熟悉补充机器学习 或 数值计算 其中最优化部分的知识
接下来怎样去计算
一层层向后求导数
先求和
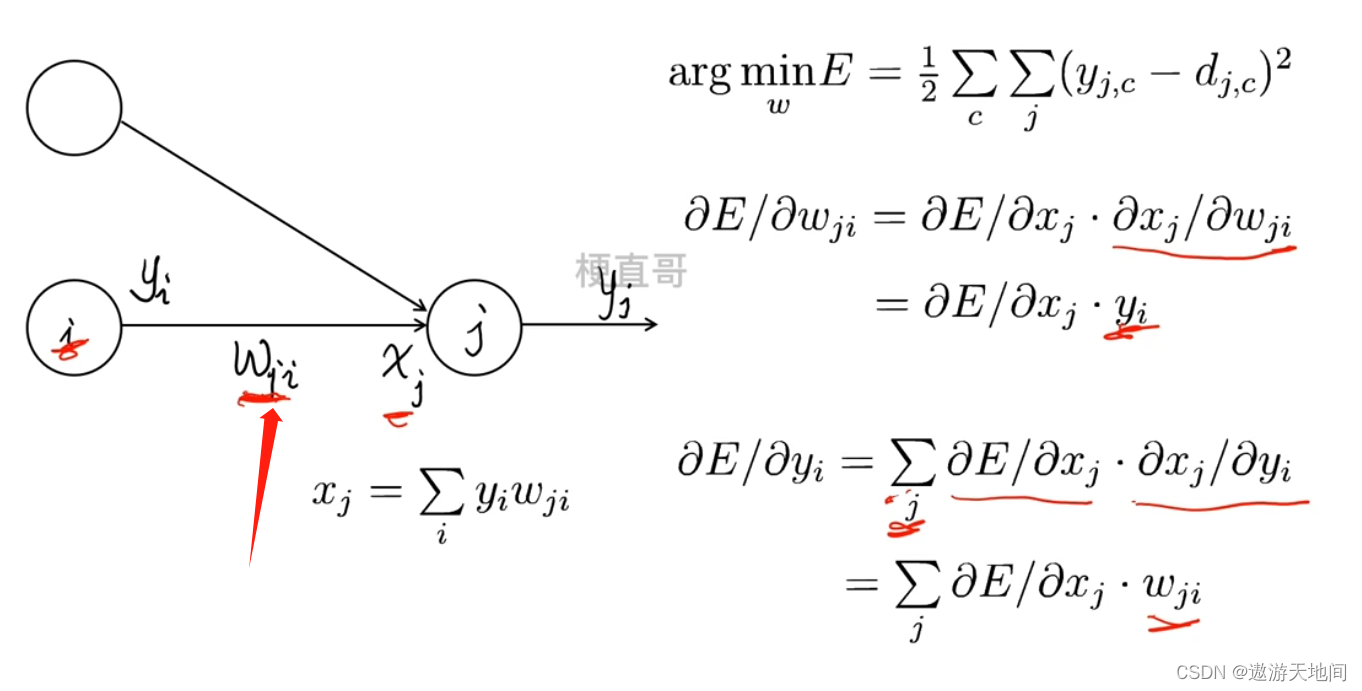
通过链式法则 把最后一层的误差 总损失 传递到倒数第二层, 反复重复这个步骤, 就能得到前面所有隐藏层的偏导数, 也能对前面各层的参数进行求偏导的计算 , 有了偏导计算的公式后 根据梯度下降法更新 神经网络的参数
小结

前向传播传递的是数据, 信息
反向传播 传递的是 误差, 梯度, 偏导数, 用偏导数更新模型参数
多层感知机代码实现

PyTorch搭建神经网络

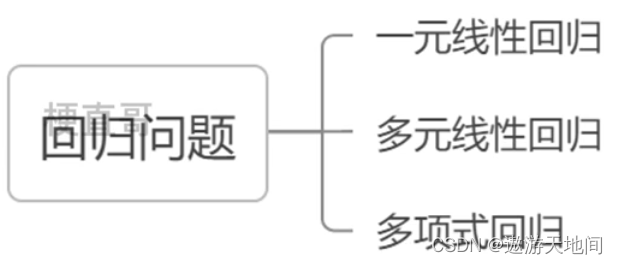
回归问题
一元线性回归
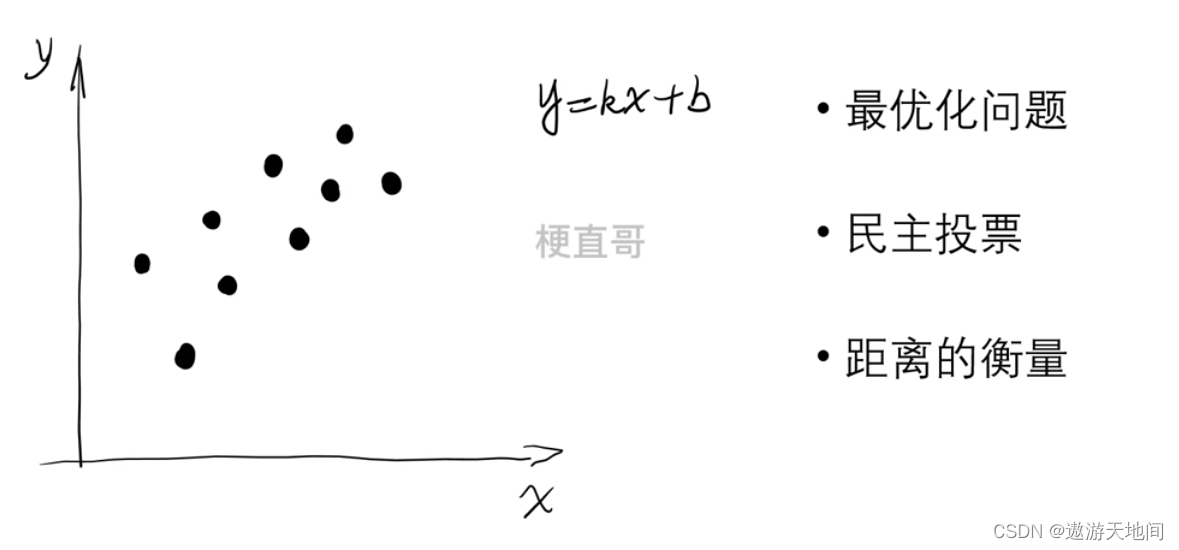
找到哪一条最好 最优化问题
点到线的距离
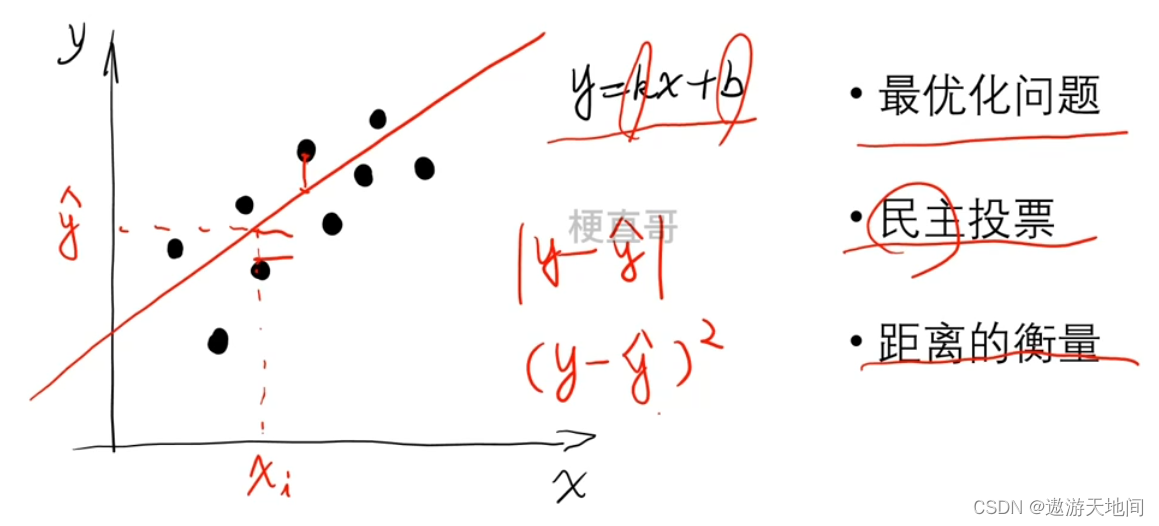
曼哈顿距离 绝对值
欧氏距离 平方和
民主投票
反向运算

找出 k,b 使结果最小,衡量了误差的大小

凸优化: 函数可导的概念
找到最优参数
多元线性回归
x 变成向量

横坐标 X 是高纬度的
X是矩阵, m 是样本的个数, n 特征维度

行乘列
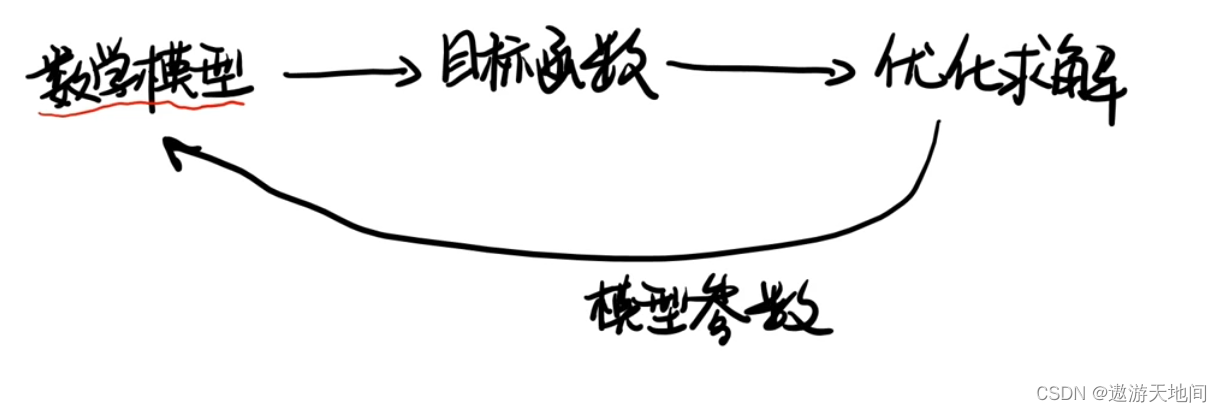
机器学习
目标函数 最优化
多元线性回归的正规方程解

多项式回归
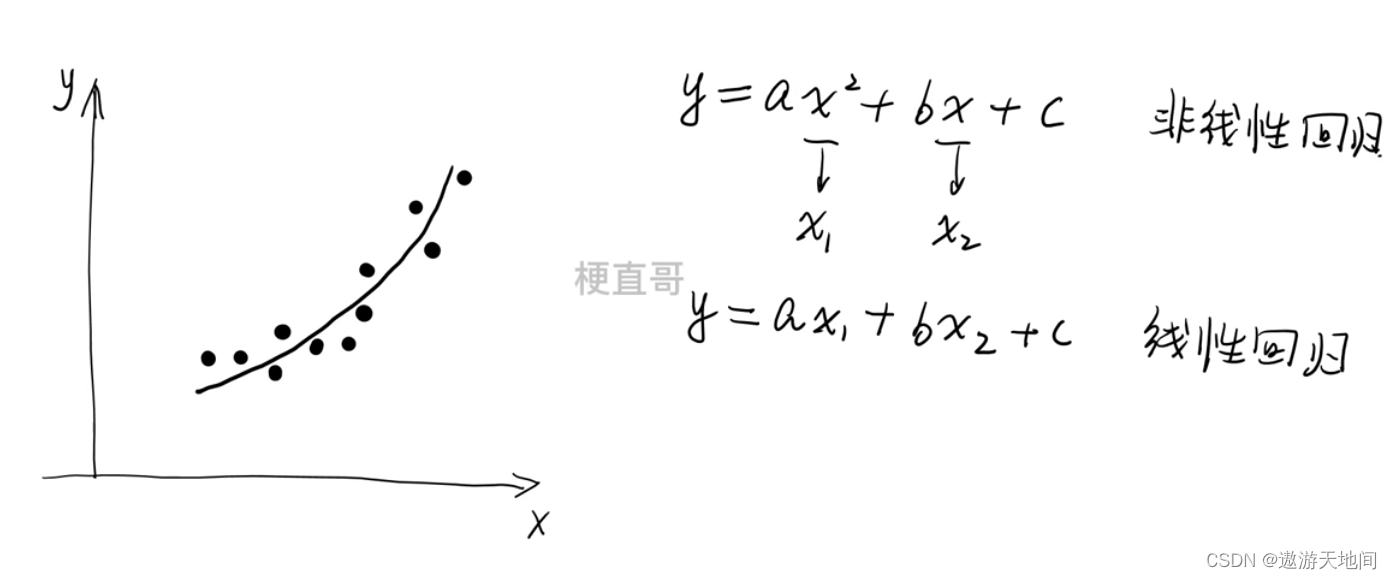
求所有样本点到这条线距离的和
先算出目标函数, 在通过最优化方法求使得它最小的参数, 最终得到一条线(模型)
小结
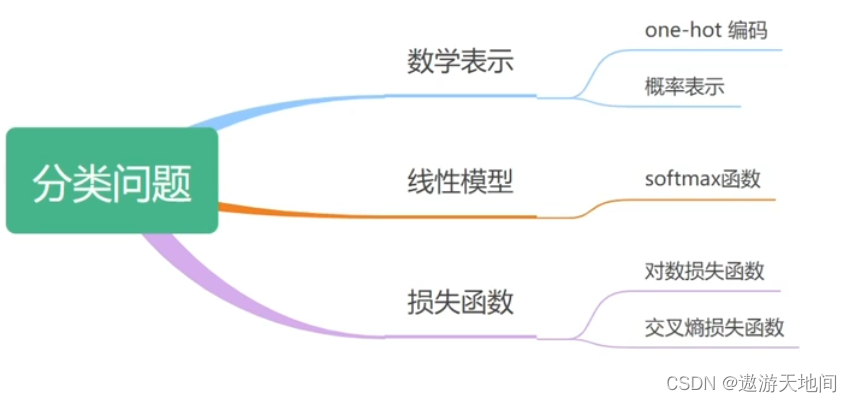
分类问题
分类任务的定义
- 将输入数据集划分到一个或多个类别中的过程
- 类别是事先确定的,并且类别标签是已知的
- 输出是一个离散的类别标签,而不是连续的值
机器学习算法流程
多分类问题的数学表示
向量表示
缺点:类别数量大时, 特征维度数量特别高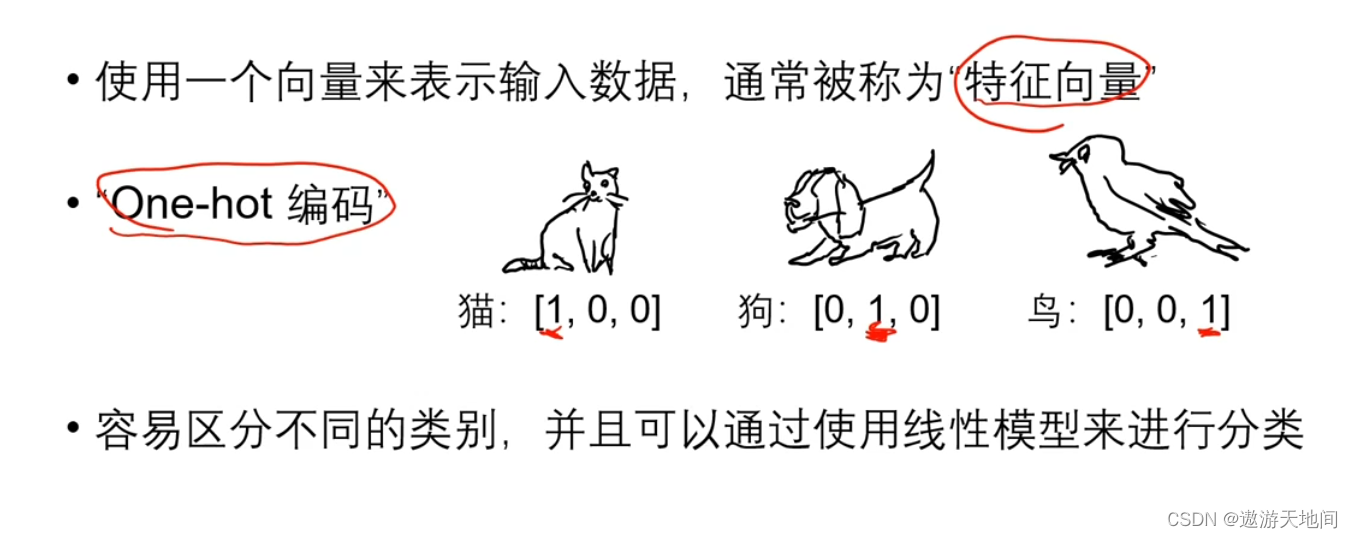
概率表示

softmax回归
多项式逻辑回归, 可以输出多个类别的概率
优点: 将输入特征向量转化为概率值

损失函数
对数损失函数
i 类别的编号
单调性, 结合性 多个数乘积转换为和的形式 , 放缩性
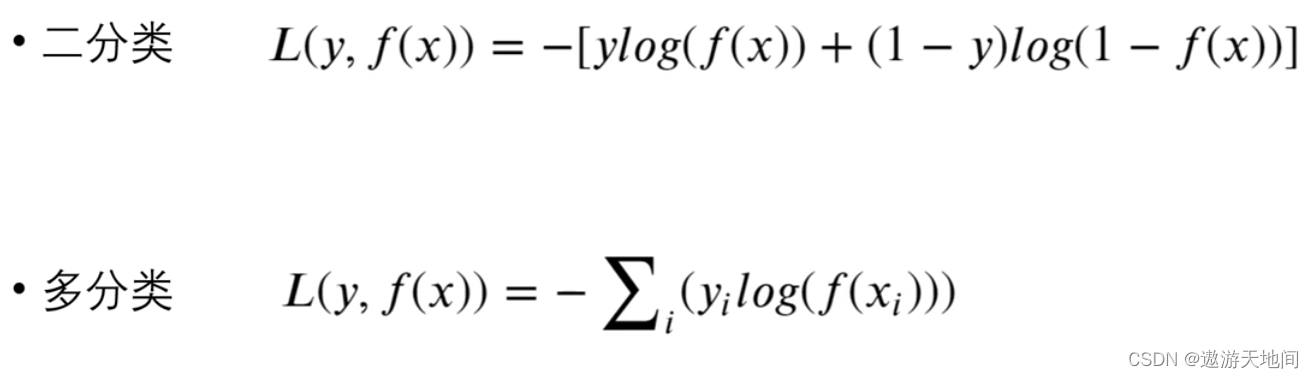
交叉熵损失函数
m 样本数, n 所属不同类别的个数

小结
















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









