







Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5) 2014 年
文章目录
论文名字比较长,平时说的 R-CNN 是按照文中的网络名称来讲的。按照论文名字来看的话,可以看到本文主要是提取丰富的特征层级,用来准确的物体检测和语义分割。
Abstract
- 在之前最好表现的是结合多个低层次图像特征和高层次上下文的复杂集成系统。
- 本文提出的简单的、可重组的检测算法,区域推荐 + 特征提取 + 分类器 3 个部分完全 3 个体系,(这也是我叫它 pipeline 散装“缝合怪”的原因,如果再算上候选框回归微调的话那就是 4 部分)。(确实可重组,每一部分都有自己的任务,各个部分之间只是为了互相配合工作组在一起的,散装的啊这是我想起来了江苏 23333)
- 两个亮点:(1)CNNs 高表达能力 + (2)监督预训练能很好适应迁移学习。
- 结合了 region proposal 和 CNNs ,命名为 R-CNN:Regions with CNN features。
Introduction
特征尤其重要。传统图像处理中经常使用 SIFT 或 HOG 特征。SIFT 和 HOG 是块直方图,对应视觉中的第一个阶段特征,而根据研究表明视觉是分阶段的,也就是后面应该有更高级的视觉处理架构来处理视觉信息,其中也包括物体检测任务。
之前 Fukushima 受生物视觉启发,完成了视觉层级和平移不变性的工作,但是缺乏监督训练算法。之后 LeCun 等使用反向传播随机梯度下降算法实现 CNNs 的训练。
CNNs 在 1990s 使用很多,随后随着 SVM 的出现而没落,直到 2012 年 AlexNet 在 ImageNet 数据集上斩获分类任务冠军而重新广泛受到关注。
本文将之前的 CNN 分类网络的现有成果应用在了物体检测任务上,不过在本文中,CNN 的应用还停留在提取区域特征阶段,也就是没有直接用在区域推荐上,而是只用在了确定某个区域之后提取其特征上(对比 SIFT 和 HOG)。本文需要面对的两个问题是:(1)使用深度网络定位物体和(2)使用少量的标注数据训练高容量的模型。
第一个问题:为什么使用深度网络定位物体位置就是个需要解决的问题了呢?物体检测任务不同于分类任务,除了要给出物体的类别以外,还要给出物体的位置信息,我们暂且就以矩形框来表示。本来嘛卷积层里面的计算自然而然地就包含了滑窗的想法,可以直接用的。但是问题是,CNNs 的层级结构注定了随着卷积层的增加感受野也会不断地增大。像 AlexNet 5 层卷积层已经行成了 195 × 195 的感受野和 32 × 32 的 strids(这么大怎么精准定位嘛,发个导弹误差 3000 公里),但是减少卷积层的数目,特征又提取得没那么好了(好纠结)。
所以本论文,诶它就放弃了用 CNNs (对应滑窗法)定位位置了。我直接用 region proposal (Selective Search 就是)来做区域推荐,拿到区域了只用 CNNs 来提取区域的特征,拿完特征我再用 SVM 做分类器。好家伙,这个也是个缝合怪,Selective Search 是在计算特征、相似度等方面是缝合怪,R-CNN 是在 PipeLine 上是缝合怪,区域推荐 + 特征提取 + 分类器 完全来自 3 个不同的方法。这也是这篇论文中模型的命名由来:Regions with CNN features。

第二个问题:四个大字 木 有 数 据(头疼,虽然其实我觉得这个论文里面不算没有数据……)。传统手段就是先无监督训练,然后再有监督调优。还有一个办法就是预训练 + 迁移学习参数调优。在大数据集上预训练,在小数据集上调优参数。
本文提出的整套系统也是很有效率的。特定类别计算仅仅有一个小矩阵向量乘法和贪心非极大值抑制。因为借助的是 region proposal 而非滑窗,所以很自然地也很适合语义分割等任务。
Object detection with R-CNN
上一部分也有提到了, R-CNN 一共三个模块分别对应整个流程中的三个任务,即独立于类别的区域推荐 + 固定大小的特征提取 + SVM 分类器。
Module design
区域推荐:Selective Search;
特征提取: 4096 维度 AlexNet ,每个区域都缩放到 227 × 227,会拿区域周围 16 像素的上下文再 warp(像如下 column D ,row 2);

Test-time detection
Selective Search 产生大约 2000 个区域推荐(这个论文工作中自己选的,并不是 SS 只能大约 2000),每个区域(这里就已经有效率问题了,2000 个哦,这样弄资源没得省)都送到 AlexNet 中提取特征,然后加 SVM 分类器。当获得一张图中所有推荐区域的得分后,应用非极大值抑制。
整个过程还挺快的,主要归功于 CNN 的参数共享 + 特征尺寸比较小(相比传统方法提取的特征,其实还是 CNN 提取特征能力强)。后面唯一的类特定计算是特征和支持向量机权重之间的点积和非最大值抑制。实际中,一张图中的所有区域的点乘计算被打包成矩阵 batch 运算了,向量矩阵大小为 2000 × 4096,SVM 参数矩阵是 4096 × N。(2000 个区域,每个区域特征 4096 长, SVM 要做 N 分类任务,有 N 个 SVM,每个类别对应一个)。
Training
还是前面说的,先大数据集上预训练,然后小数据集上调优参数,因为那个小数据集那点数据不够训练一个这么大的 CNN 网络(一定会过拟合)。不讲得很仔细了,用大数据集训练,里面类别也多,到小数据集上迁移训练时,迁移过来的主要是前面那些卷积层(提取特征层),而全连接层(特征组合层)你就在新的小数据集上面重新训练就行了,所以模型结构中后面的类别什么的要根据小数据集修改。只不过这里很有意思的是,即使在新数据集上调优之后,也只是拿全连接之前的 4086 特征向量出来作为特征,再送到 SVM 中。(这里会觉得很浪费吗?明明 CNN 最后的全连接后面 softmax 直接就是现成的分类。论文有给出解释,大概两段以后会说明。)
这里要说一下在调优过程中对于正负样本的定义,因为正样本实在太少啦,训 CNN 太捉襟见肘了,所以天平倾向了正样本,把差不多的 IoU > 0.5 的都叫正样本了。但是后面 SVM 的标准并没有沿用这里,是特意改了的。SVM 中把 ground truth 作为正样本,把 IoU < 0.3 的叫负样本。
这里论文附录 B 有讲,论文工作是从 ImageNet 预训练(未经 fine-tuning 的模型)开始训练 SVM的,训完 SVM 后,返回去做 fine-tuning,一开始用的和 SVM 一样的正负样本定义,但是发现训不起来 CNN(大大滴过拟合啦),所以又为 fine-tuning 定了专门的的正负样本定义,这样增加了 30 倍正样本训练 fine-tuning。
回到刚刚的疑问,为啥不直接用 fine-tuning 的 softmax 分类结果啊,那不是现成的一个分类器吗?因为 fine-tuning 过程中正样本被“偏爱”强行增多了,比较“软”,所以 softmax 的效果没有 SVM 那边好,毕竟SVM 那边的样本都很“刚”。对于 20 类的任务,可能 SVM 和 softmax 都可以胜任的,然后 SVM 拿到的数据更好,自然效果也更好了。
Bounding-box regression
通过 SVM 对候选区域打分之后,再使用一个独立于类别的回归器对 BoundingBox 进行回归,来微调物体位置框。这个操作有点像 DPM (deformable part models),区别在于我们从 CNN 提取的特征入手回归,而不像 DPM 中的几何特征。
训练 BoundingBox 回归器的数据是一些候选框和标签框组成的数据对,候选框用 P 表示,标签框就是 ground truth 啦用 G表示。
那么 P i = ( P x i , P y i , P w i , P h i ) P^i = (P_x^i, P_y^i, P_w^i, P_h^i) Pi=(Pxi,Pyi,Pwi,Phi) 表示第 i 个候选框,其中包括四个参数,即中心点坐标和框的宽高。
而对应的 ground truth 就是 G = ( G x , G y , G w , G h ) G = (G_x, G_y, G_w, G_h) G=(Gx,Gy,Gw,Gh) 。那么用来训练的数据集就是一对对 pair 的集合就是 { ( P i , G i ) } i = 1 , . . . , N \{(P^i, G^i)\}_{i = 1, ... , N} {(Pi,Gi)}i=1,...,N。后面为了方便就省略上标 i 了。
4 个参数对应 4 个变换,分别是
d
x
(
P
)
d_x(P)
dx(P),
d
y
(
P
)
d_y(P)
dy(P),
d
w
(
P
)
d_w(P)
dw(P),
d
h
(
P
)
d_h(P)
dh(P)。通过这 4 个变换,可以把 region proposal 映射到/预测出 ground truth 框。即:
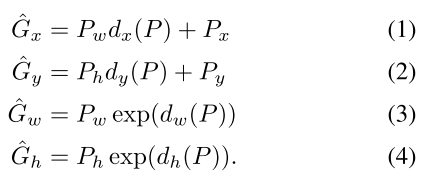
其中坐标位置点上没有直接加变换,而是通过把变换加在宽高上来预测 ground truth 框的中心位置,叫 scale-invariant translation。宽度高度上用的是对数空间的变换, log-space translations。
刚刚说的这 4 个变换,都是 P 在 pool5 特征
ϕ
5
(
P
)
\phi_5(P)
ϕ5(P) 的线性变换,即
d
∗
(
P
)
=
w
T
⋅
ϕ
5
(
P
)
d_*(P) = w^T \cdot \phi_5(P)
d∗(P)=wT⋅ϕ5(P),训练这个回归器就是在训练
w
w
w,对于 4 个变换中的参数分别应用正则最小二乘:
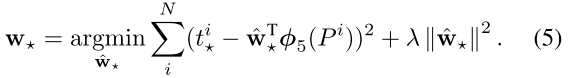
这里面的 t 其实就是回归的目标(对应每个训练数据对 ground truth 和 候选框 4 个变量之间的映射关系),就是前面说的那 4 个变换(每个变换是分开计算的)。
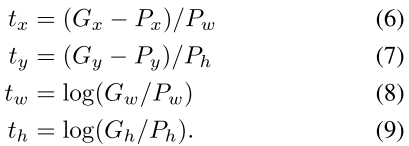
我们的回归优化指标就是找到那么一组参数 w w w,能够让完美变换 t i t^i ti 和实际变换 w ^ T ⋅ ϕ 5 ( P i ) \hat{w}^T \cdot \phi_5(P^i) w^T⋅ϕ5(Pi) 之间的差距最小,同时加上了一项对于参数 w w w 的正则项 λ ∣ ∣ w ^ ∣ ∣ 2 \lambda ||\hat{w}||^2 λ∣∣w^∣∣2。
需要注意的一点是,只有离得比较近的候选框和 ground truth 框之间组成的训练数据对才有意义,因为我们的目的本来就是回归微调。若风马牛不相及的训练数据对用来训练微调,也是很不合理的。
在实际预测时,只做一次回归;论文工作中曾经测试过迭代地回归,发现没啥用,我觉得这里应该就是相当于很多层全连接吧,一层和多层的表达能力差别几乎没有。















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









