







声明
本文是笔者学transformer基本概念的笔记,主要是对网上一些比较好的讲解的整合,如果讲的不对,欢迎大家指正,同时,如果有侵权,请联系我删除
参考文章&视频
【Transformer模型】曼妙动画轻松学,形象比喻贼好记_哔哩哔哩_bilibili
超强动画,一步一步深入浅出解释Transformer原理!_哔哩哔哩_bilibili
Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
Attention
核心思想
通过加权求和,解决context的理解,在不同的上下文下,专注不同的信息
背景&概念
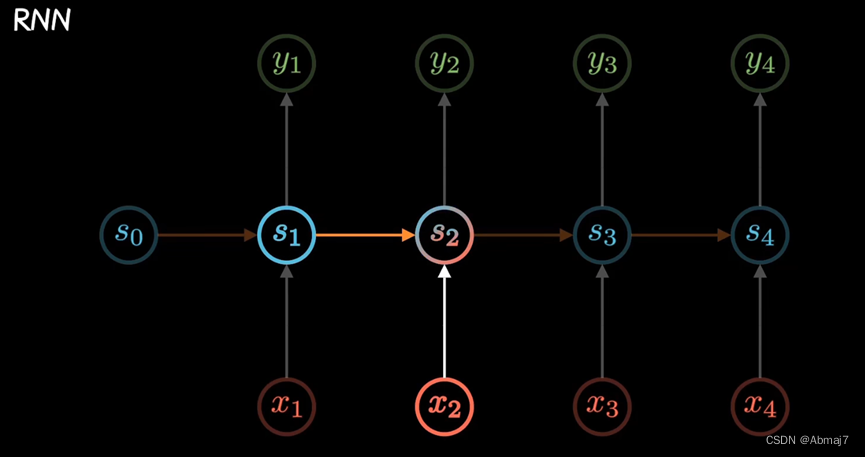
RNN
建立了网络隐层间的时序关联,每一时刻的隐层状态st,不仅取决于输入xt,还包含了上一时刻的状态s(t-1)
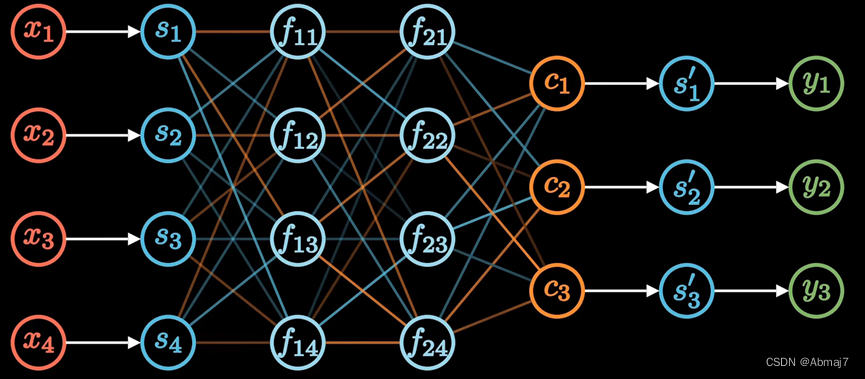
Encoder-Decoder
两个RNN形成Encoder-Decoder模型
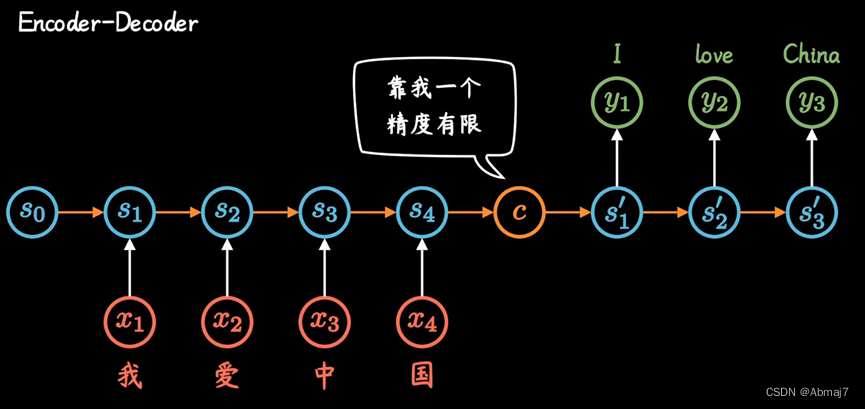
缺陷:不管输入多长,都统一压缩成一个相同长度编码C的做法,会导致翻译精度下降
Attention机制
为了解决上面的缺陷,提出了Attention机制
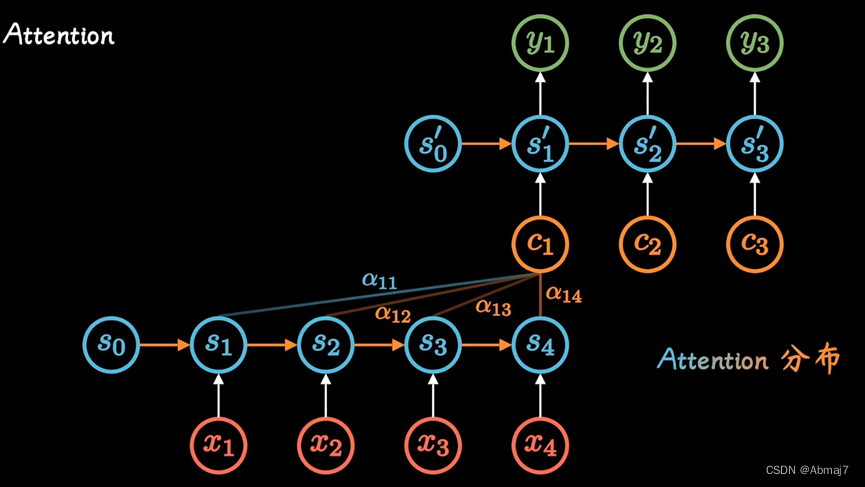
在attention机制中,每一个时间,都会得到不同的编码C,输入给Decoder,这样可以解决精度有限的问题
其中系数a(ti)。标明了在t时刻所有输入的权重,以ct的视角看,在它眼中,就是不同输入的注意力,因此也被称为attention分布
网络结构定了之后,我们可以通过神经网络数据训练,得到最好的attention权重矩阵
通过attention机制,打破了只能利用encoder,形成单一向量的限制,让每一时刻,模型都能动态地看到全局信息,将注意力集中到对当前单词翻译最重要的信息上
Self-Attention机制
随着GPU大规模并行运算的发展,人们发现RNN的顺序结构很不方便,难以并行计算,效率太低。
为了解决这个问题,提出了self-attention机制
利用attention机制计算每个单词,与其他所有单词之间的关联
可以理解为一个参照表,通过权重,标明相互关系,嵌入上下文信息
Sele-Attention结构
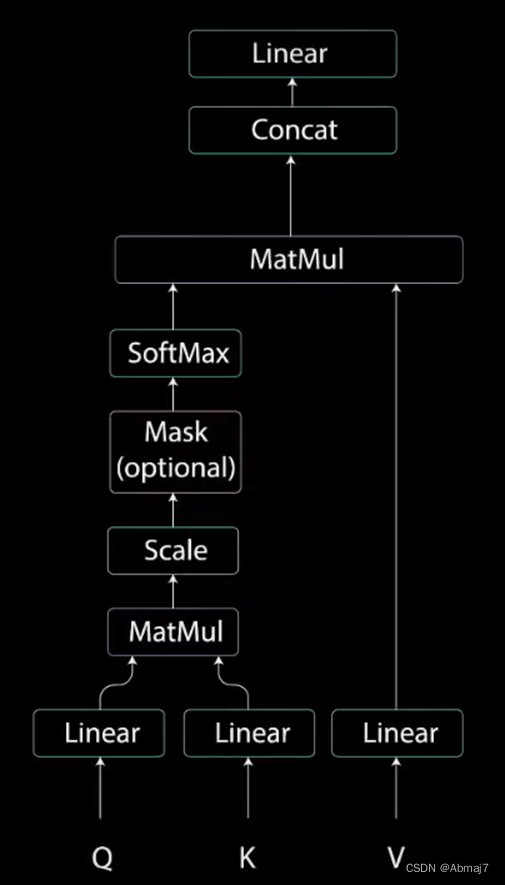
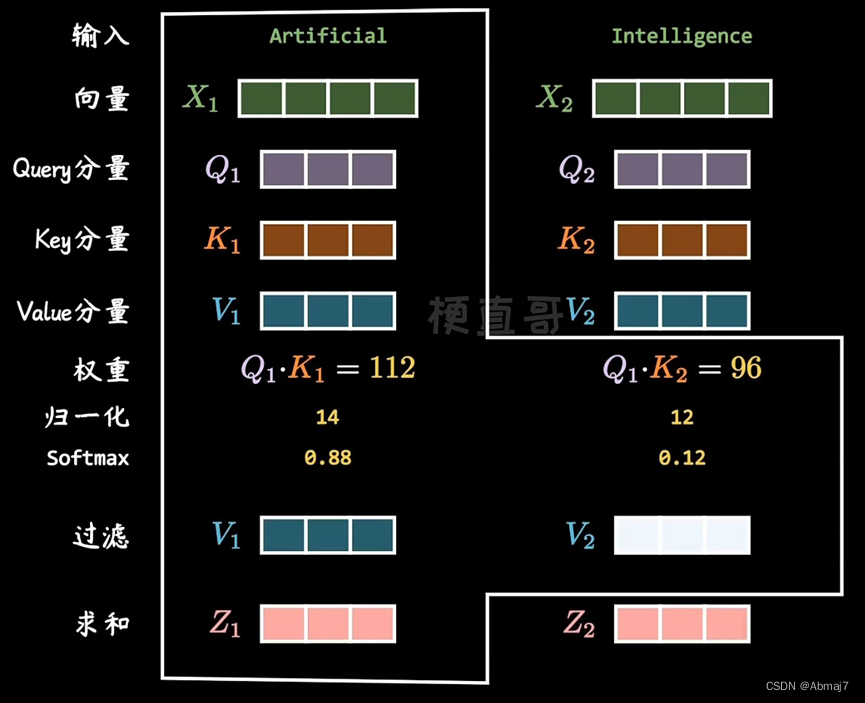
Q,K,V的计算
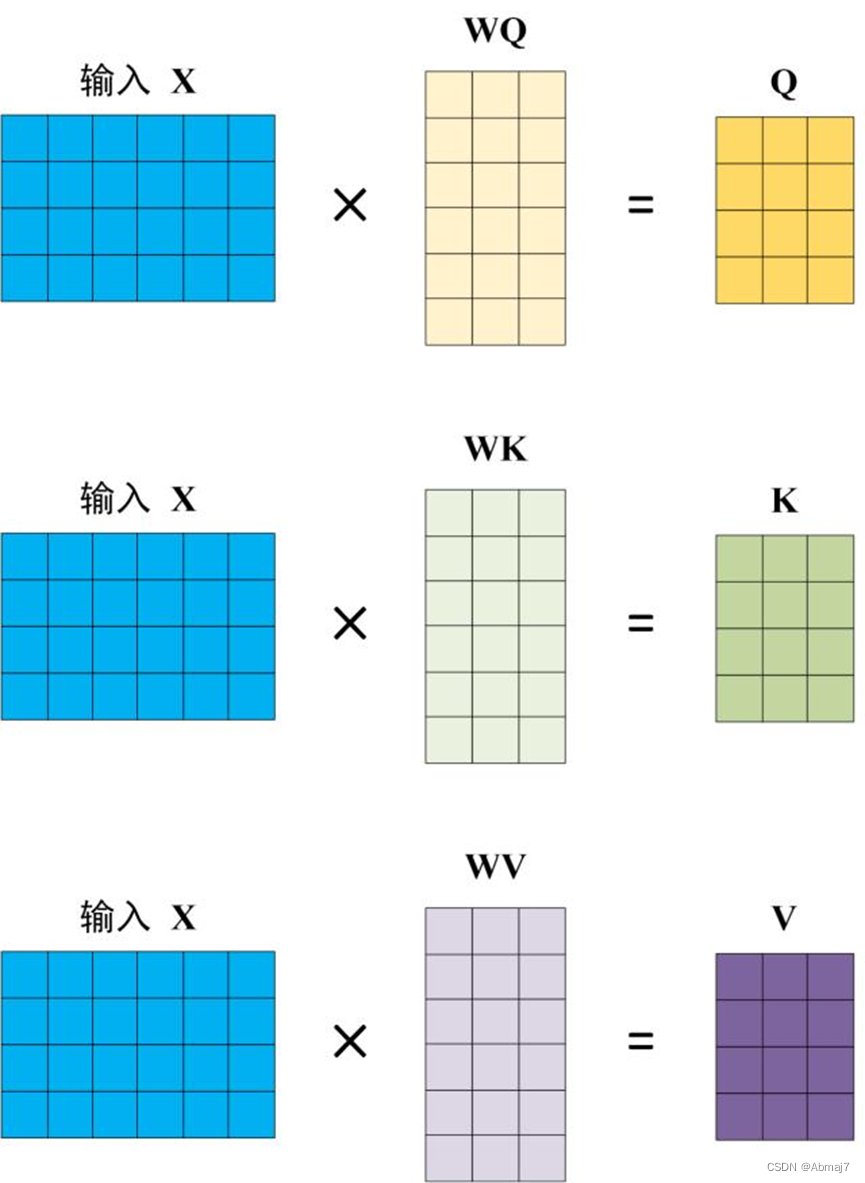
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
Self-attention的输出

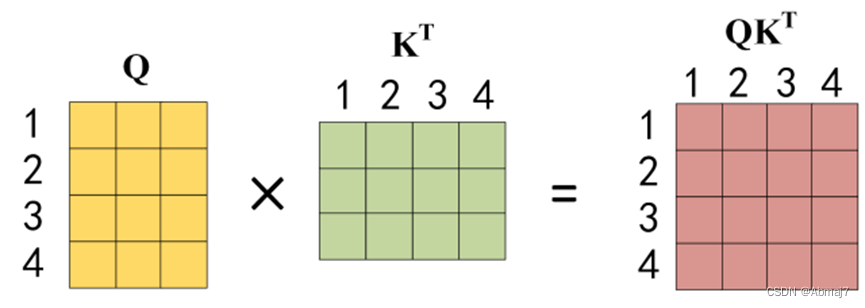
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以dk的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 分数。下图为Q乘以KT,1234 表示的是句子中的单词。
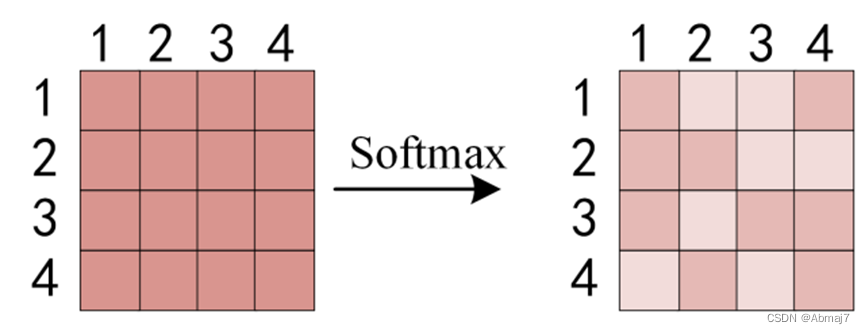
得到QKT之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z
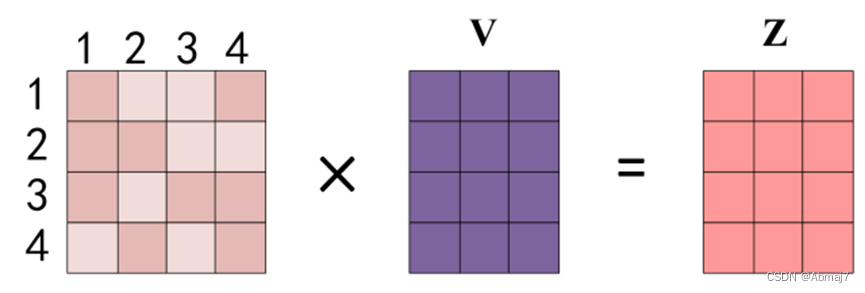
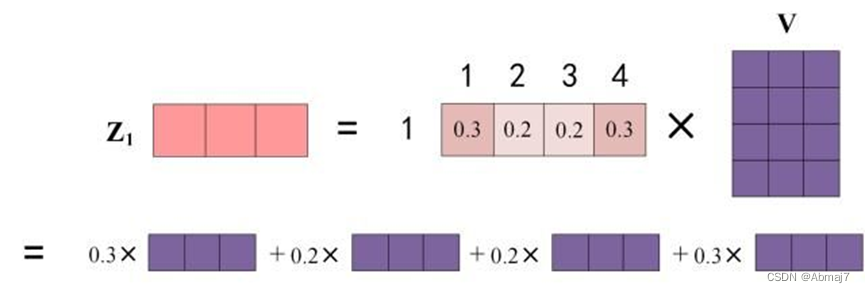
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出Z1等于所有单词 i 的值Vi根据 attention 系数的比例加在一起得到,如下图所示:
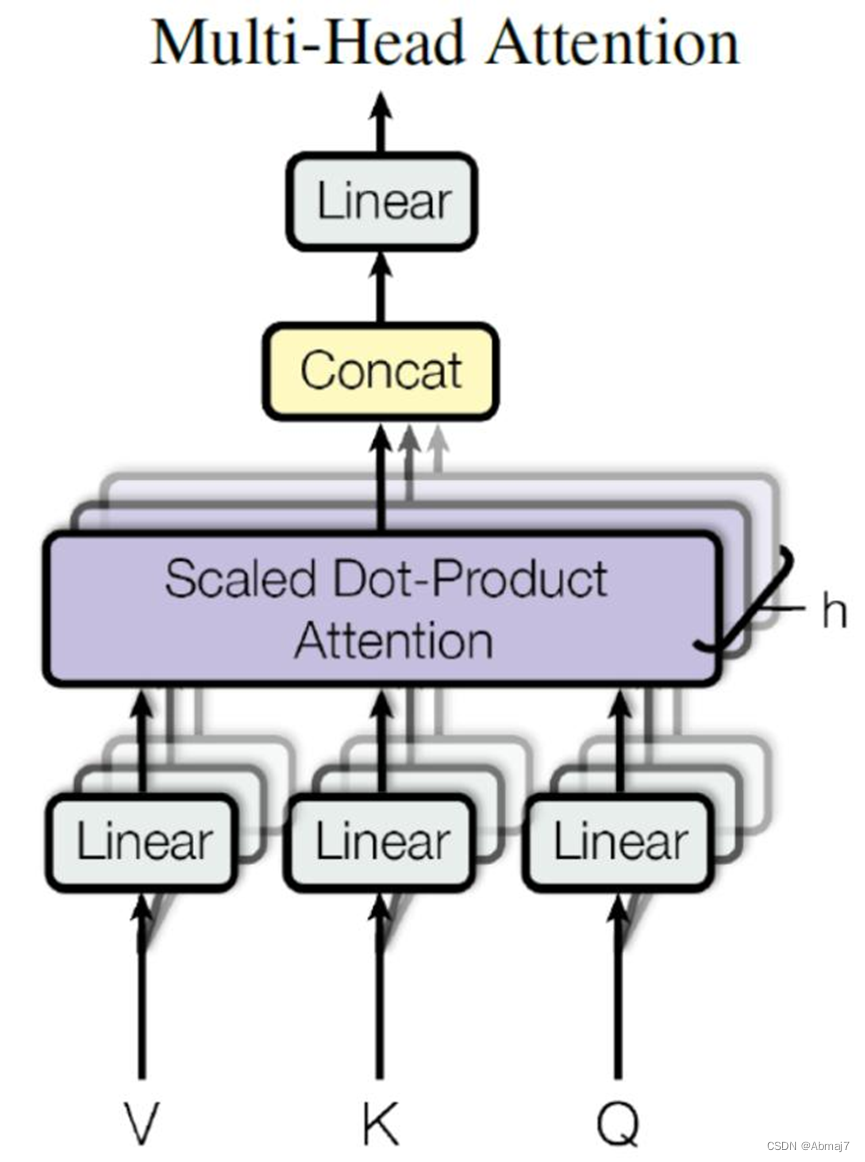
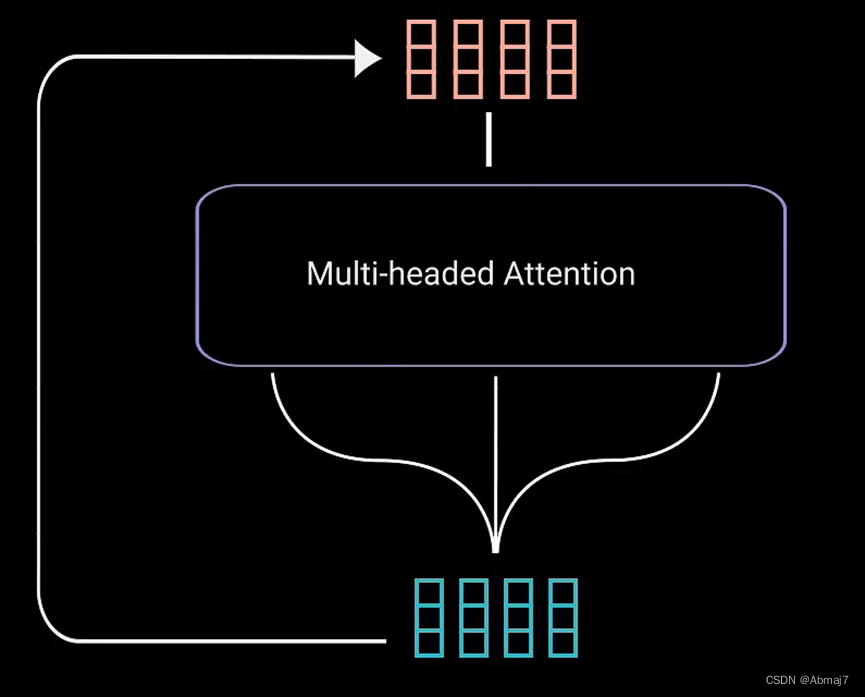
Multi-head attention
Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是 Multi-Head Attention 的结构图。
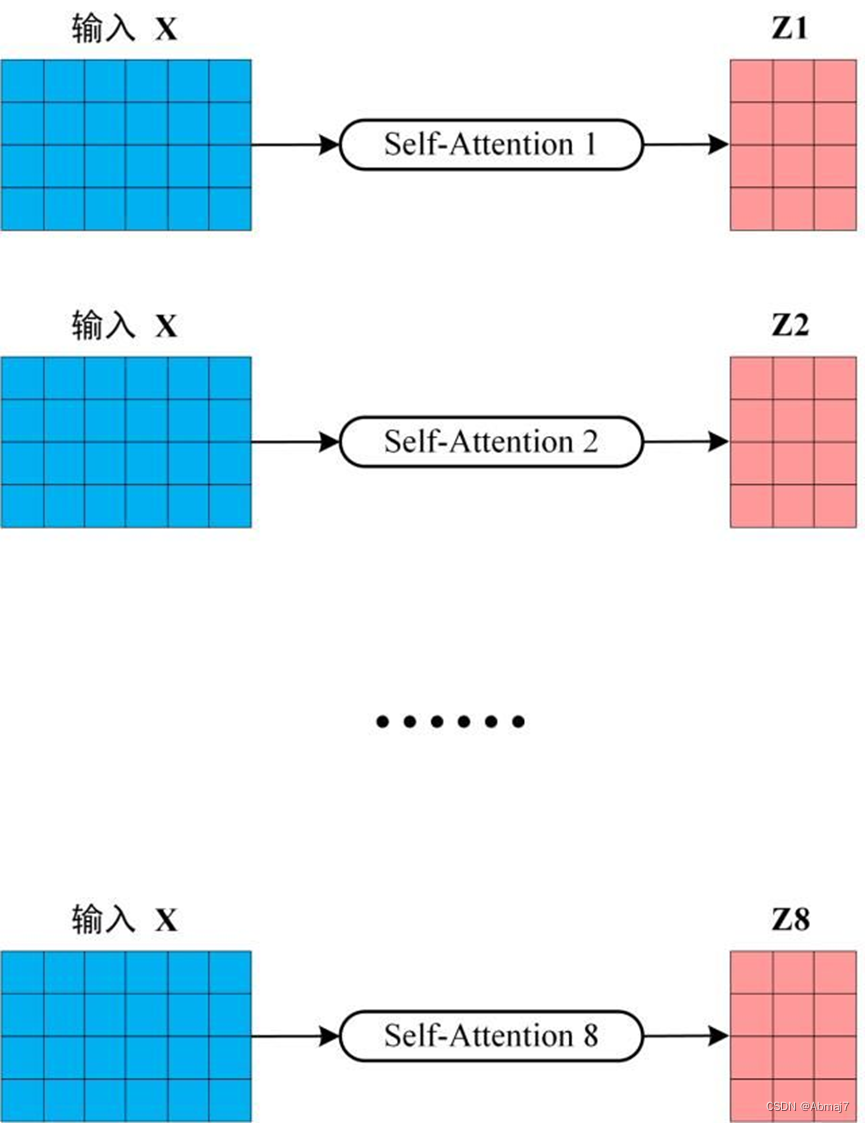
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
得到 8 个输出矩阵Z1到Z8之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
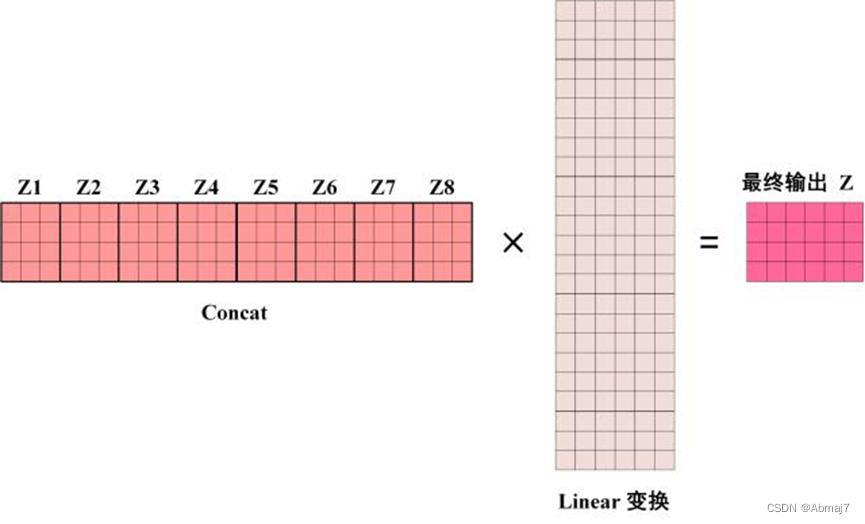
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
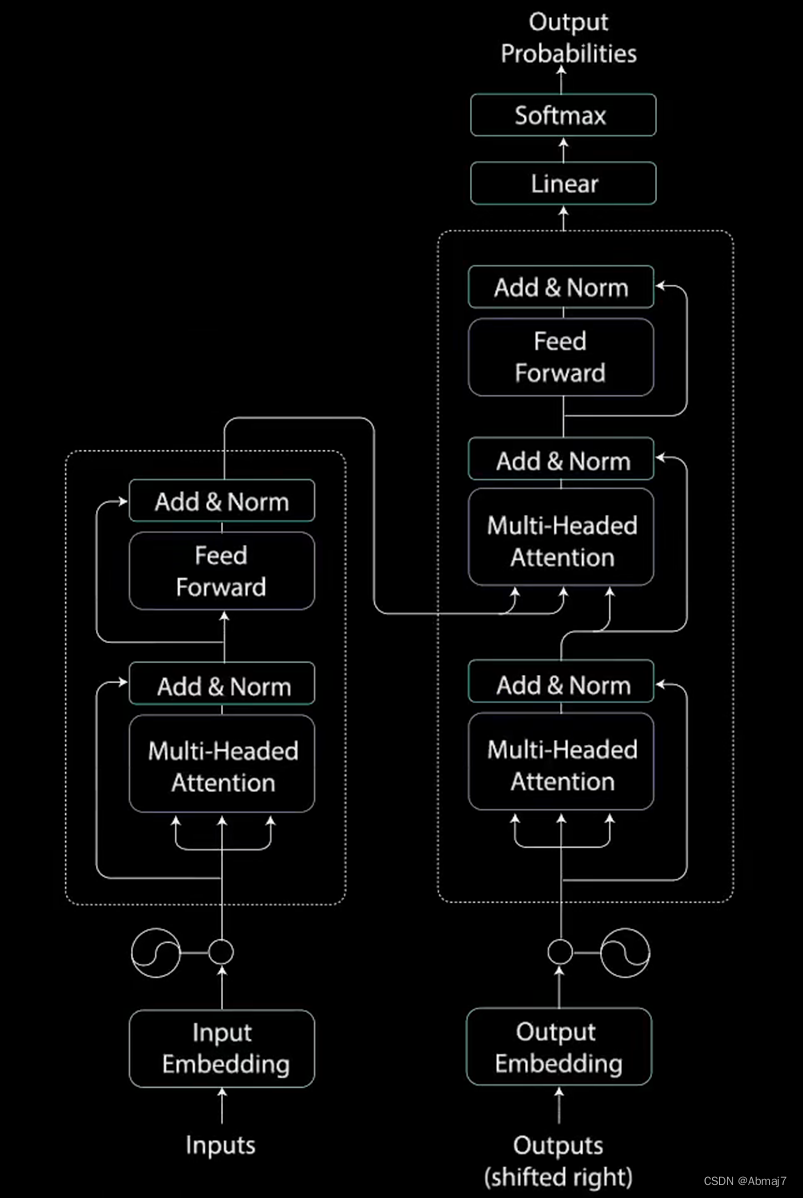
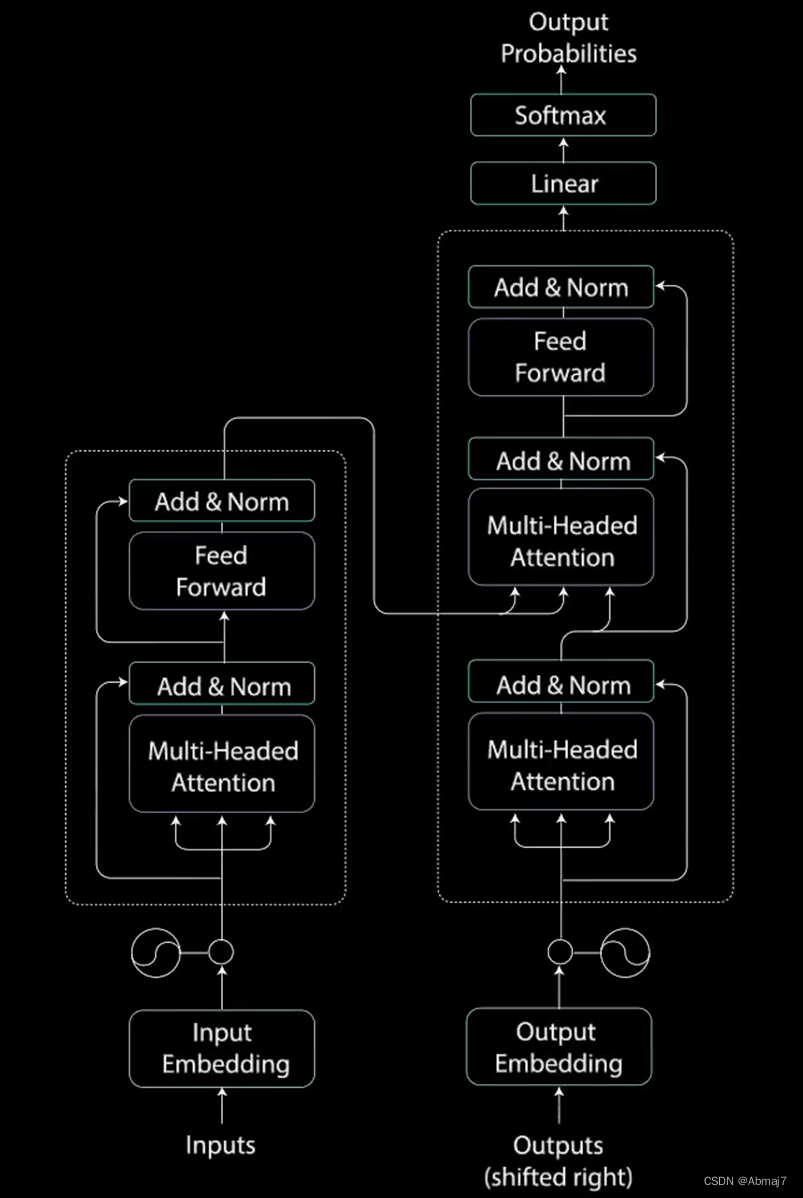
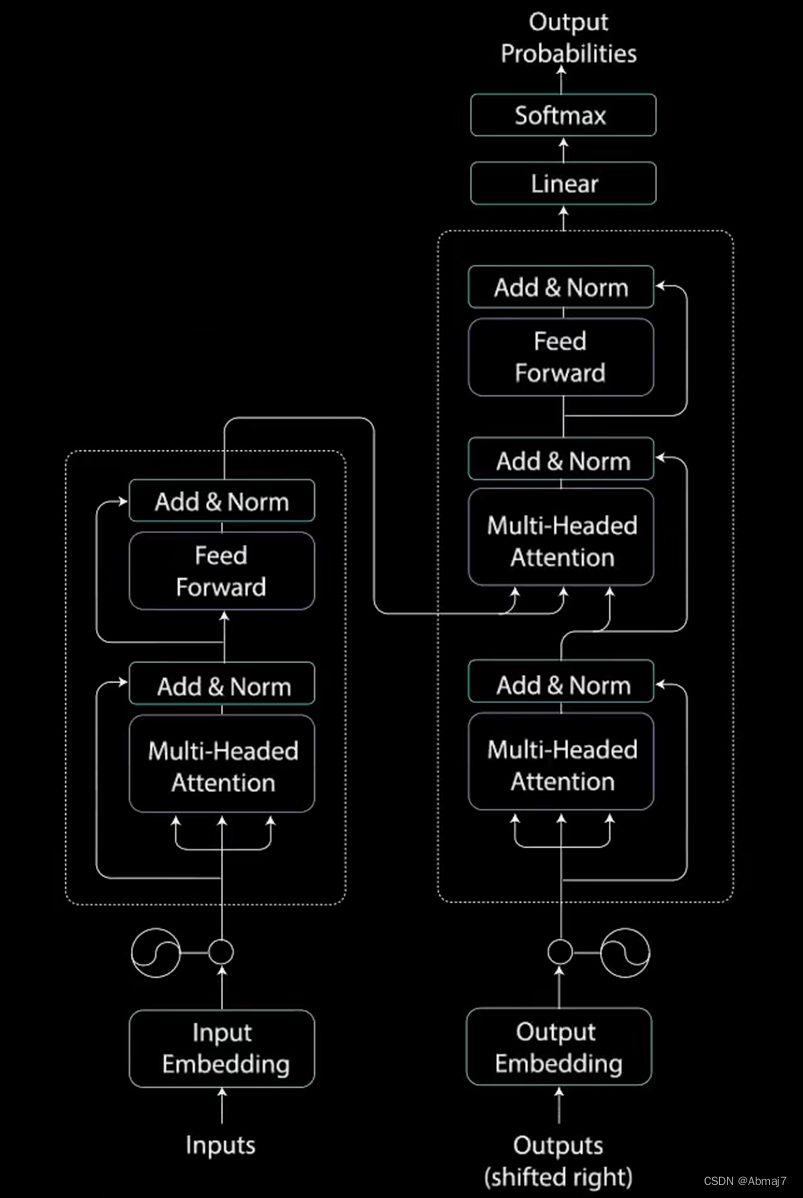
Transformer网络结构
整体结构
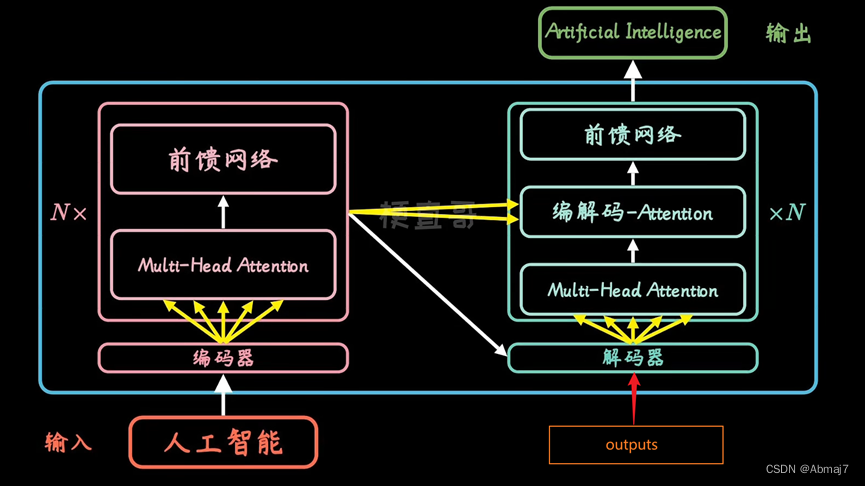
分为编码encoder和解码decoder两个过程
每个encoder和decoder又是一个串联的组合
Encoder
每个encoder又包含了multi-head attention和前馈网络两个核心模块
在encoding阶段,利用attention机制计算每个单词,与其他所有单词之间的关联
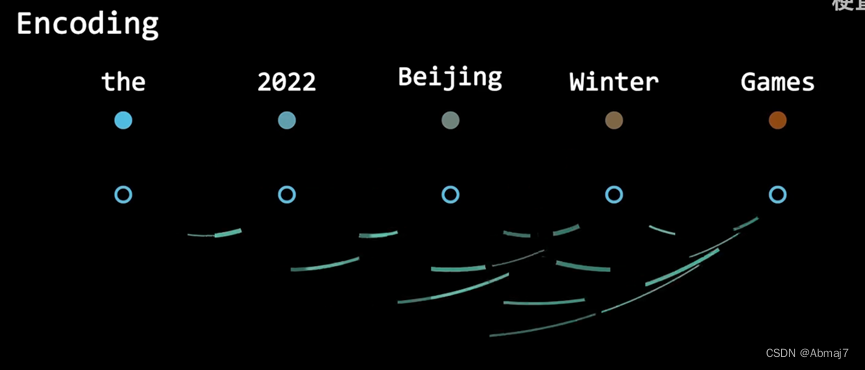
利用这些权重,加权表示,再放到一个前馈神经网络中,得到新的表示,就很好的嵌入了上下文的信息
Decoder
Decoder除了multi-head attention和前馈网络两个核心模块之外,在中间还多了一层,叫做encoder-decoder attention,其作用就是在decode的时候,不光要考虑自己,还要兼顾拆解时候的整体信息
解码时,每个词,不光要看已经翻译的内容,还要考虑encoder中上下文的信息
工作流
输入->encoder
总体工作流
具体步骤
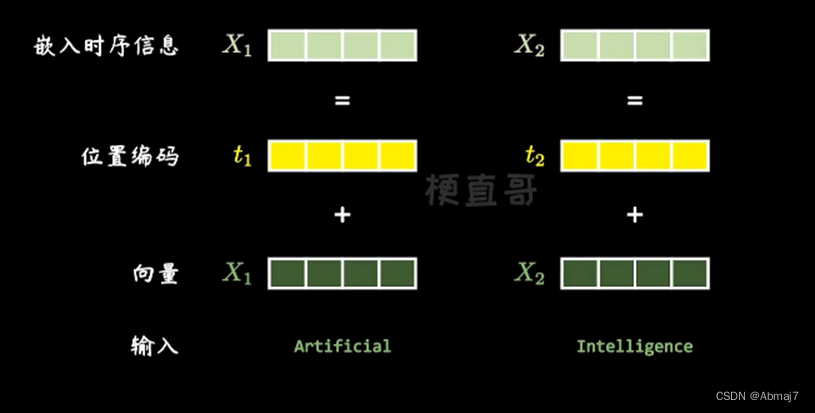
1.用算法,把单词向量化,嵌入位置信息(与位置Embedding相加),变成统一长度(比如都是512位),得到X向量
单词向量化可以采用Word2Vec、Glove等算法
位置Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
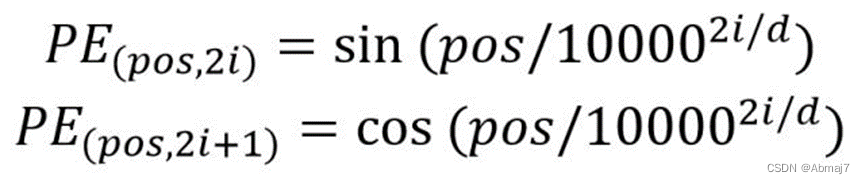
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量X,X就是 Transformer 的输入。
2.将第①步中产生的X向量,分别乘以三个训练好的向量Q,K,V,得到Q分量,K分量,V分量
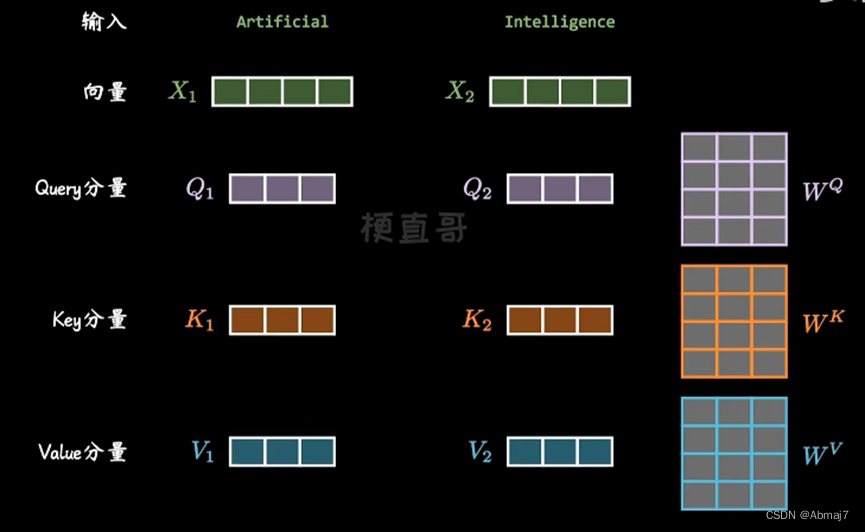
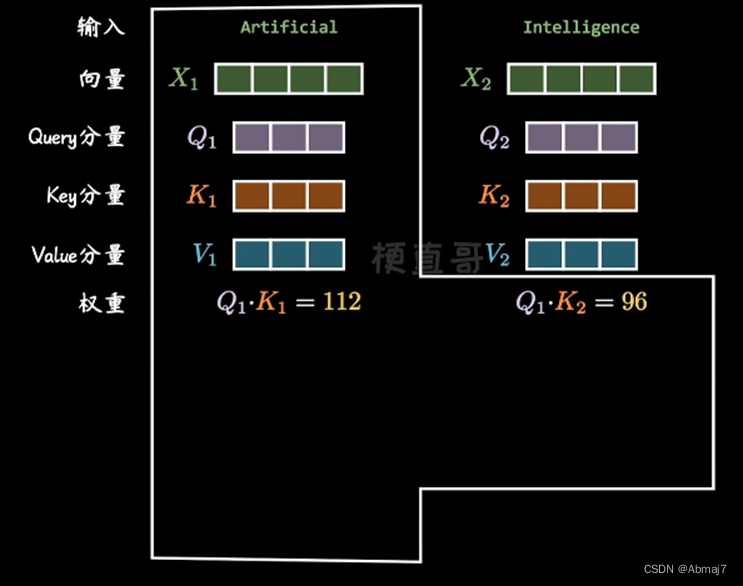
3.再用每个单词的Q向量,和所有单词的K向量相乘,得到的权重(分数矩阵),就是attention,它确定了一个单词应该如何关注其他单词
每个单词都会有一个与时间步长中的其他单词相对应的分数,分数越高,关注度越高。

4.通过将Q和K的维度开平方,将分数矩阵的得分缩放
目的:防止让梯度更加稳定,因为乘法可能会产生梯度爆炸的效果
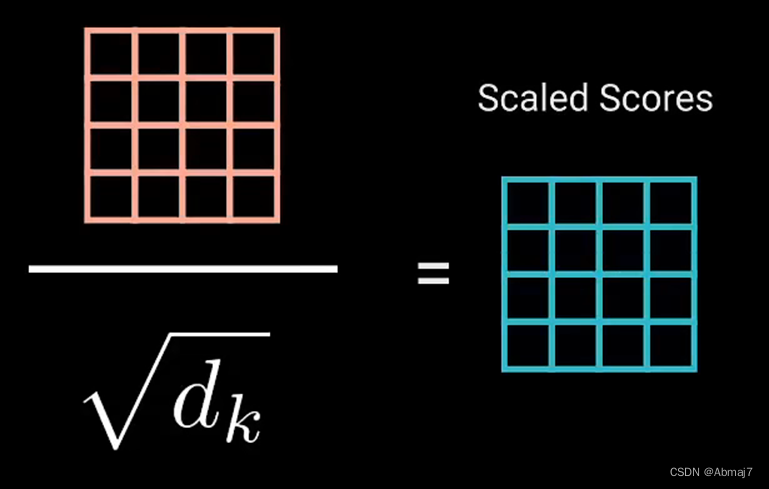
5.再然后,对缩放后的得分进行softmax计算,得到attention权重矩阵,从而获得0到1之间的概率值
注意:进行softmax计算后,较高的得分会得到增强,较低的得分会被抑制
较高的softmax得分会保留模型认为更加重要的词的值
较低的得分将淹没不相关的词

6.接着,将attention权重矩阵与V向量相乘,得到输出向量
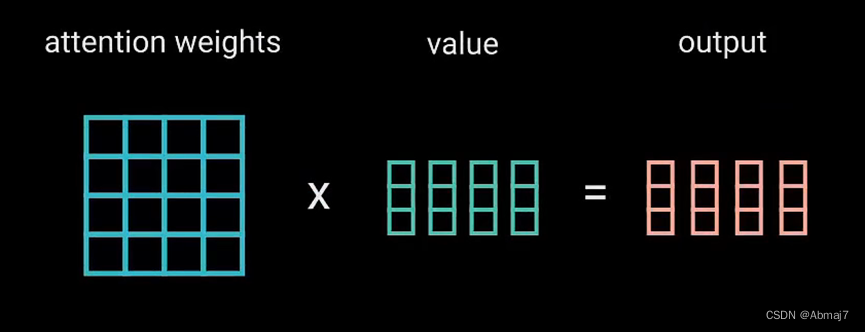
7.在multi-head attention中,使用了不同的权重矩阵Q,K,V,做8次计算(做8次计算的目的是为例消除QKV初始值的影响),最后求一个加权平均,合成一个Z
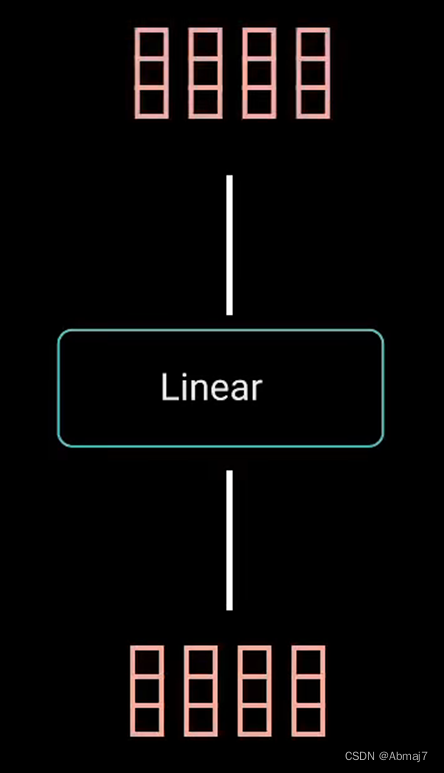
8.将输出向量输入线性层进行处理
生成一个带有编码信息的输出向量,指引序列中的每个词如何关注其他所有词
注意,输出矩阵Z的维度没有变,只是其中被编码,掺入了其他单词的上下文信息
9.将multi-head attention输出向量加到原始输入上,做残差连接,用于防止网络退化
10.残差连接的输出经过层归一化

11.归一化后的残差输出被送入一个点对点前馈网络进行处理
点对点前馈网络是几个线性层,中间有ReLU激活函数
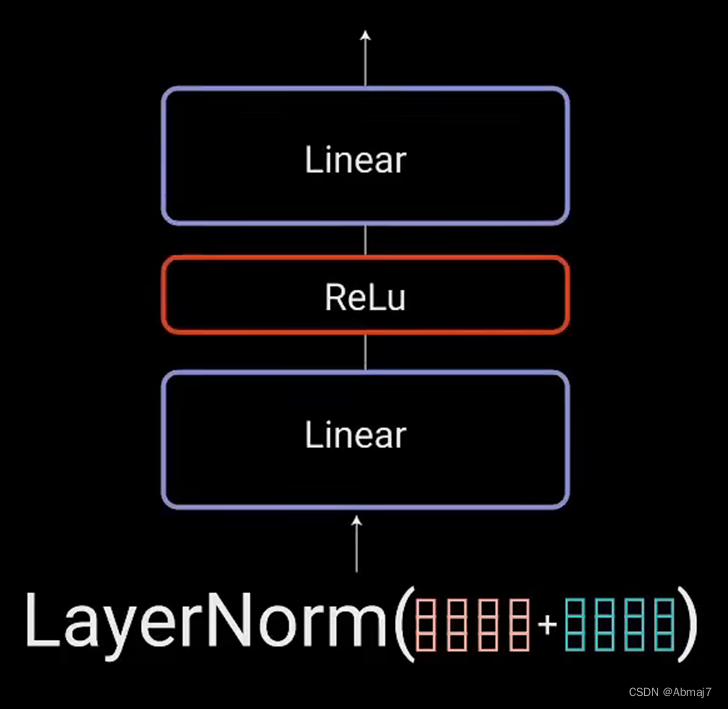
12.再次将该输出与点对点前馈网络的输入相加,并进一步归一化
残差连接有助于网络训练,因为它允许梯度直接流过网络
使用层归一化来稳定网络,从而显著减少所需的训练时间。
点对点前馈层用于进一步处理attention输出,可能使其具有更丰富的表达
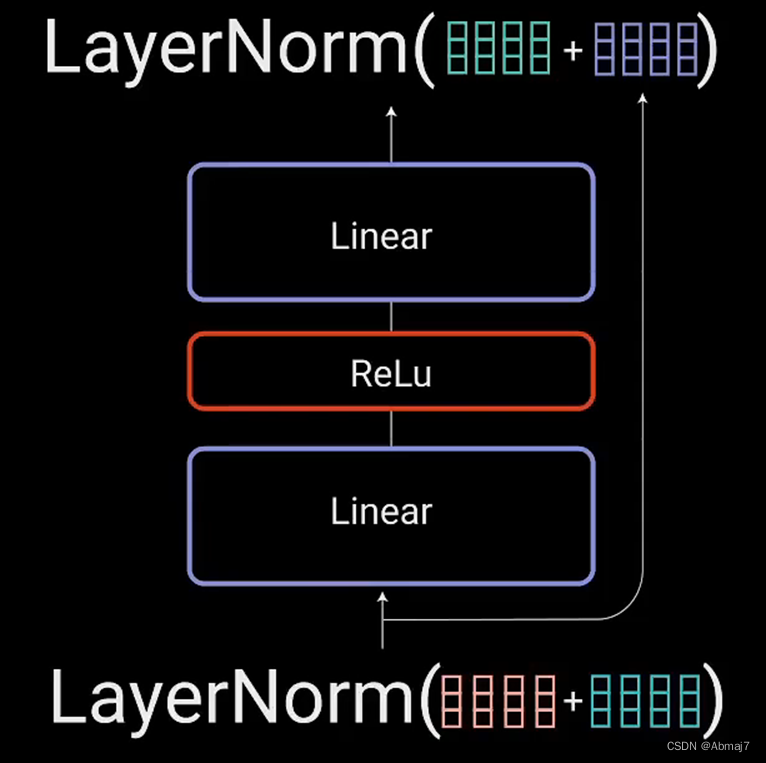
13.将编码器堆叠n次,以进一步编码信息,其中每一层都有机会学习不同的注意力表示,从而有可能提高transformer网络的预测能力
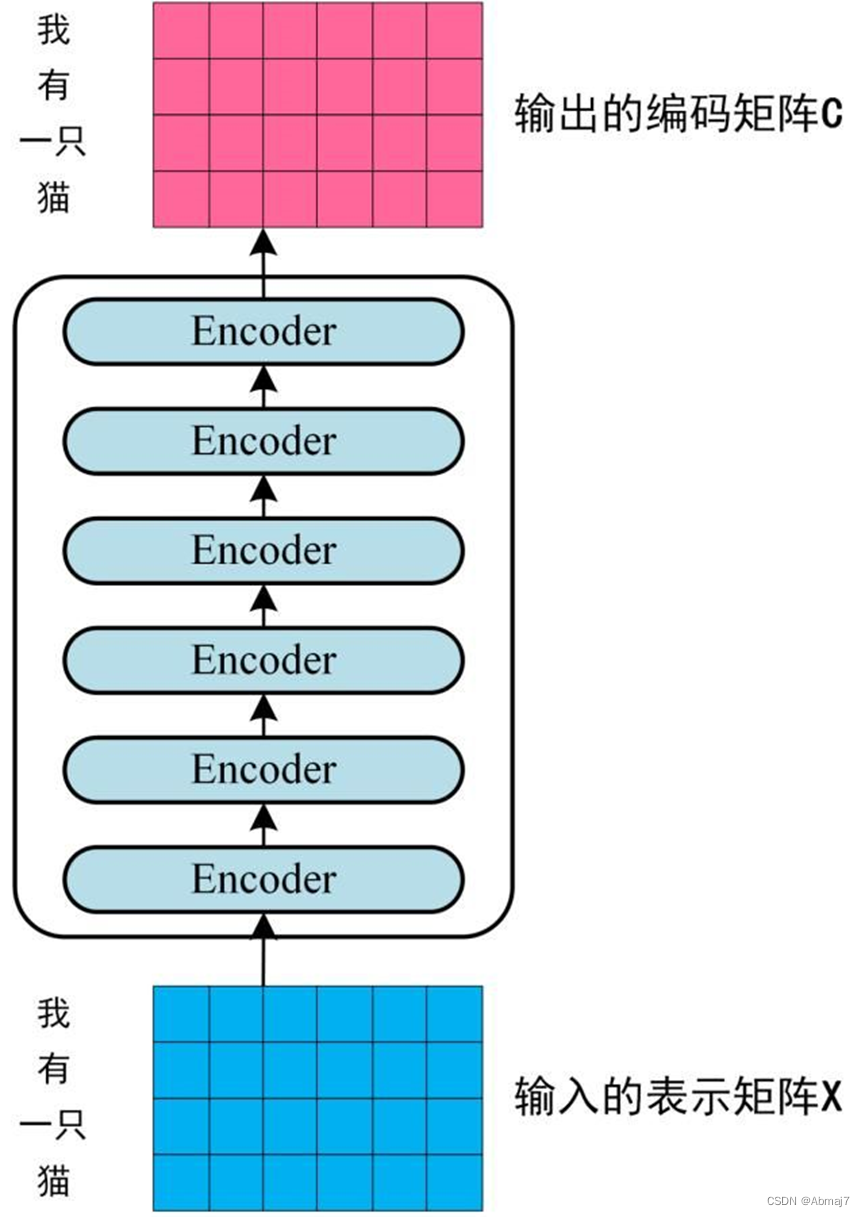
14.最后,输出一个Encoder的编码信息矩阵C
如下图。单词向量矩阵用X n x d表示,n是句子中单词个数,d是表示向量的维度(论文中d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
Decoder->输出
总体工作流
具体步骤
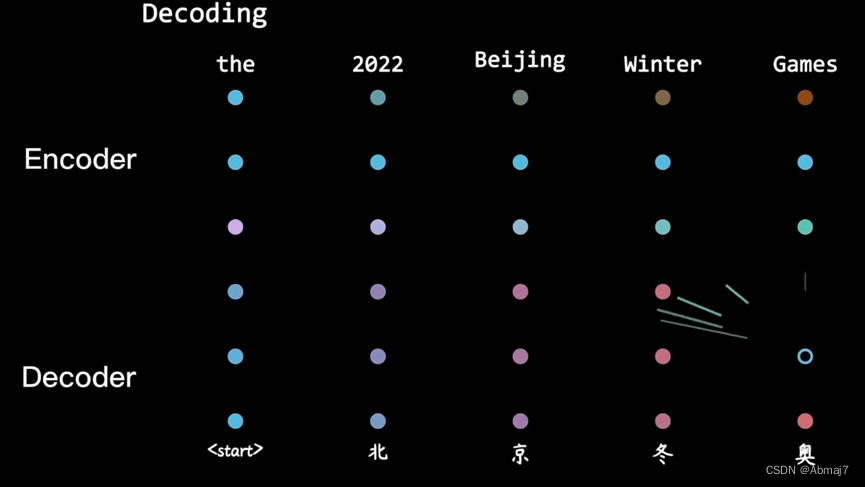
1.输入通过嵌入层和位置编码层,得到位置嵌入向量X,进入第一个multi-head attention块
输入是:目前已经翻译的内容,比如,翻译我有一个梦想,我目前已经翻译得到了I have a三个单词,还剩一个“梦想“没有翻译,那此时,我在翻译梦想的时候,decoder的输入,也就是图中的outputs是I have a
具体可以参考:
(99+ 封私信 / 82 条消息) 哪位大神讲解一下Transformer的Decoder的输入输出都是什么?能解释一下每个部分都是什么? - 知乎 (zhihu.com)
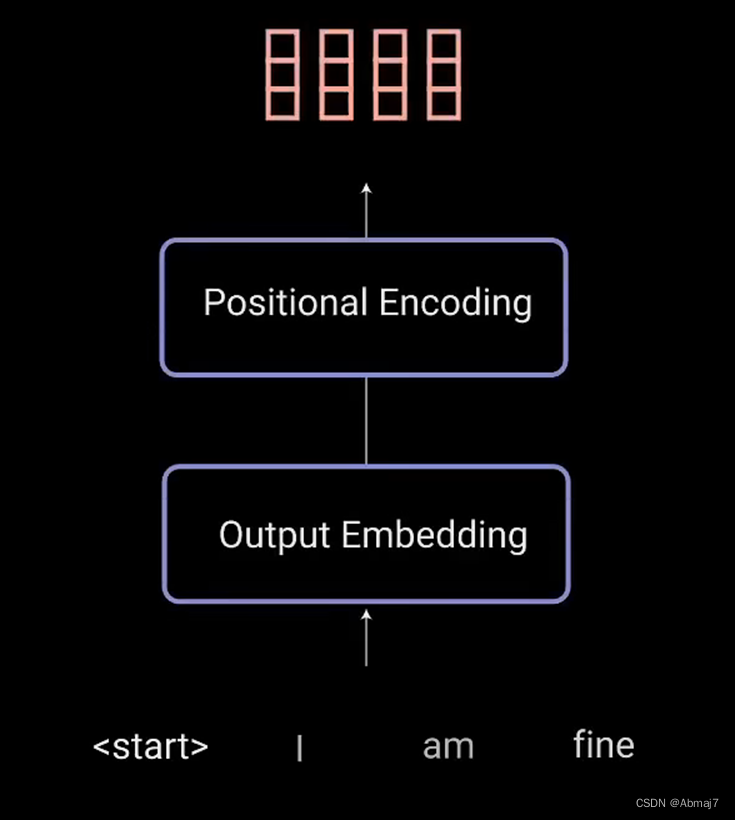
2.X乘以三个训练好的向量Q,K,V,得到对应的分量
和encoder中一样
3.每个单词的Q分量与所有的K分量相乘,得到权重矩阵
和encoder中一样
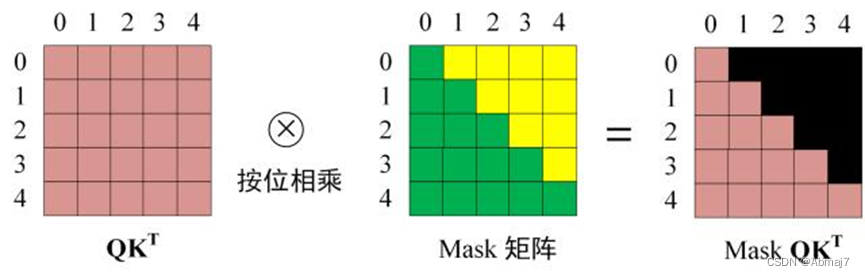
4.构建一个Look-Ahead Mask矩阵,与attention矩阵按位相乘
注意:
因为decoder是自回归的,并且逐词生成序列,你需要防止它对未来的标记进行条件处理
例如,在计算单词”am”的注意力得分时,不应该访问单词”fine”,因为那个词是在之后生成的未来词。

单词”am”应该只访问它自己和它之前的单词,对于所有其他单词,它们只能关注之前的单词。我们需要一种方法来防止计算未来单词的注意力得分。这种方法为mask

所以我们需要用一个Look-Ahead Mask来防止解码器查看未来的标记。
Mask是一个与attention得分大小相同的矩阵,填充0和负无穷大的值。将mask添加到缩放后的注意力得分后,会得到一个带有右上角三角形负无穷大的得分矩阵。
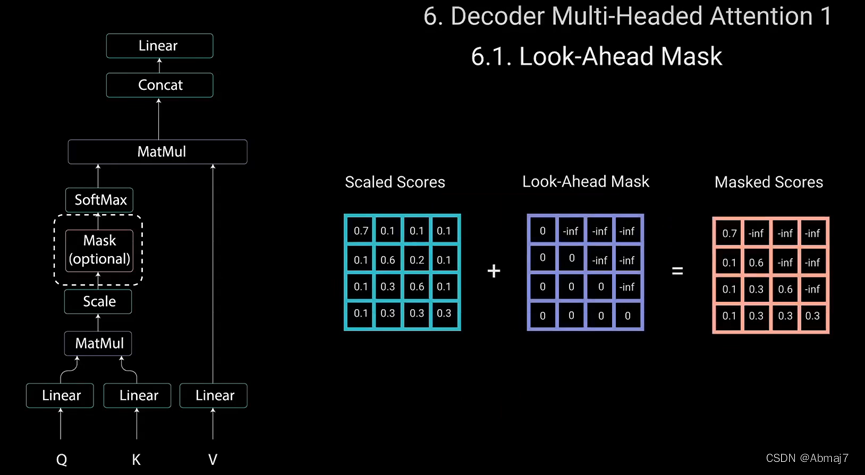
这样做的原因是,一旦对mask得分进行softmax计算,负无穷大值,就会变为零,从而为未来的标记留下零注意力得分,这实质上是告诉模型,不要关注这些单词
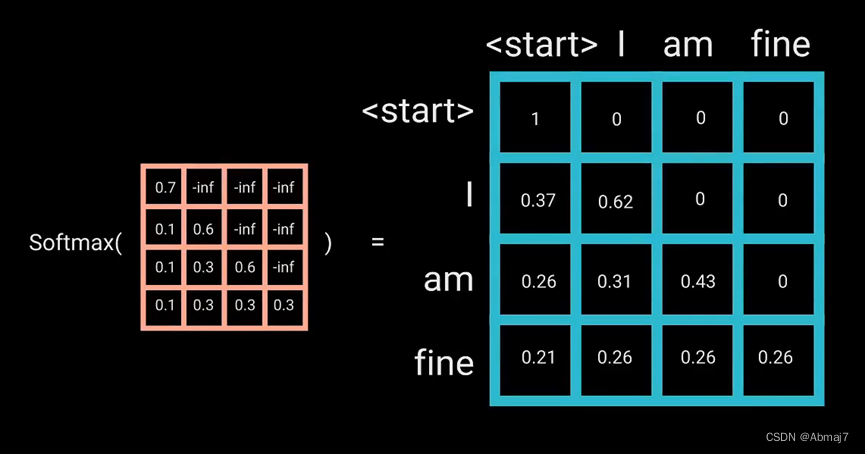
5.对mask后的矩阵进行softmax计算,得到mask attention矩阵
6.使用mask attention矩阵与V向量相乘,得到Z向量,其中包含有关模型如何关注decoder输入的信息。
7.将multi-head attention得到的8个Z向量加权平均,得到输出Z向量
8.将Z向量输入线性层处理
9.将multi-head attention输出向量加到原始输入上,做残差连接
10.残差连接的输出经过层归一化
11.进入第二个multi-head attention
它会将encoder的输入与decoder的输入相匹配,允许decoder决定哪个encoder输入是相关的焦点。
具体原理:
第二个multi-head attention的Q,K,V分量的来源如下:
根据 Encoder 的输出 C计算得到 K, V(也是乘以训练好的Q,K,V向量所得),根据上一个 Decoder block 的输出 Z 计算 Q,后续的计算方法与之前描述的一致。
这样,在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息。
12.执行第二个multi-head attention + 层归一化 + 残差连接,输出Z向量
13.解码器堆叠N层高,每层从编码器和其前面的层中获取输入,并输出最终的Z向量
通过堆叠层,模型可以学会从注意力头中,提取并关注不同的注意力组合,从而有可能提高预测能力
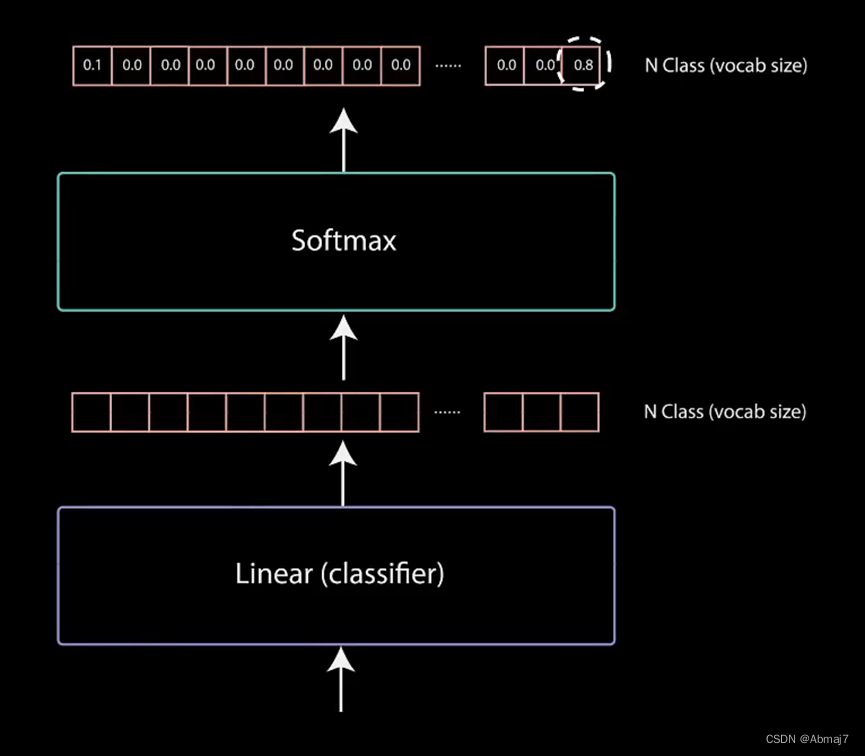
14.线性层通过一个全连接网络,把decoder输出投影成一个一维向量
这个向量的维度很长,包含了所有可能出现的单词总和
该线性层充当分类器。分类器的大小与我们所拥有的类别数相同。
例如,你有10000个类别,表示10000个单词,那么分类器的输出大小将为10000,分类器的输出然后被送入一个softmax层
15.Softmax预测输出单词
Softmax层进一步归一化,其中,概率最高的单词,就是最后的输出
Softmax层为每个类别生成0到1之间的概率得分,我们取概率得分最高的索引,等于我们预测的单词















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









