









MMFNet: A Multi-modality MRI Fusion Network for Segmentation of Nasopharyngeal Carcinoma
MMFNet:一种用于鼻咽癌分割的多模态MRI融合网络

中科院SCI分区:二区
Abstract
从核磁共振图像中分割鼻咽癌是鼻咽癌放射治疗的重要前提。然而,人工分割鼻咽癌是一种费时费力的方法。此外,单模态MRI通常不能提供足够的信息来准确显示。因此,提出了一种新的融合多模态医学图像信息的多模态MRI融合网络(MMFNet),利用T1、T2和对比度增强T1的MRI完成鼻咽癌的精确分割。MMFNet的主干被设计成一个基于多编码器的网络,该网络由多个编码器和一个解码器组成,编码器用于捕获特定于模态的特征,解码器用于获取用于NPC分割的融合特征。**为了有效地融合多源特征,提出了一种融合块。它包含一个3D卷积块注意力模块(3D-CBAM)和一个残差融合块(RFBlock),**前者重新校准从特定模态编码器捕获的低层特征以突出信息特征和感兴趣区域(ROI),后者融合重新加权的特征以保持融合特征和解码器高层特征之间的平衡。此外,为了充分挖掘多模态MRI中的个体信息,提出了一种自转移的训练策略,利用预先训练好的特定模态编码器来初始化基于多模态编码器的网络。本文提出的基于多模态MRI的鼻咽癌分割方法能够有效地分割鼻咽癌,并通过大量的实验验证了该方法的优越性。
Keywords
鼻咽癌;分割;多模态MRI;三维卷积块注意模块;残留融合块;自转移。
Introduction
鼻咽癌(NPC)是一种病因不明且复杂的恶性肿瘤。鼻咽癌独特的地理分布使东南亚、华南、北极和中东/北非等地区的鼻咽癌发病率极高[1]。早期发现和诊断鼻咽癌患者的10年生存率较高,I期为98%,II期为60%,而晚期患者的中位生存期仅为3年[2]。因此,及时有效的治疗对降低鼻咽癌的死亡率起着至关重要的作用。放射治疗是鼻咽癌的主要治疗手段,它高度依赖于核磁共振成像(MRI)等医学图像来准确描绘大体肿瘤体积(GTV),从而将正常的邻近组织与病变区域分开,从而降低放射相关的毒性[3]。然而,目前临床医生在制定放疗计划前,需要人工逐层标记鼻咽癌的边界,费时费力。另外,人工分割的质量很大程度上依赖于临床医生的经验,影响着治疗效果。因此,目前迫切需要一种自动准确的分割方法来减轻临床医生的工作量,提高治疗效果。
目前,根据所使用的特征类型,鼻咽癌分割方法可以分为基于传统手工特征的方法和基于深度神经网络(DNN)的深度特征的方法两类,一类是基于传统手工特征的方法,另一类是基于深度神经网络(DNN)的深度特征的方法。在传统的方法中,除了比较简单的医学图像的人工特征,如强度[4,5]、纹理[6]和形状[7,8]外,还实现了一些传统的基于知识的方法,如支持向量机(SVM)[9,10]、半监督模糊c-均值[11,6]、字典学习[12]来生成NPC边界。黄等人[8]提出了一种MRI中鼻咽癌的三步分割方法。该方法利用自适应算法和距离正则化水平集来获取NPC区域和轮廓,然后提出一种基于最大熵的HMRF-EM框架来进一步细化分割结果。Wang等人[12]介绍了一种联合字典学习方法,该方法同时获取多个CT、MRI字典和对应的标签,实现鼻咽癌分割。
本文成功地实现了基于手工特征和传统知识方法的鼻咽癌切分框架,完成了鼻咽癌切分。然而,鼻咽癌复杂的解剖结构和邻近组织间强度的相似性使得仅依靠人工特征很难准确分割鼻咽癌。同时,形状和大小的高度多样性使得这项任务更具挑战性[8]。因此,受深度学习技术的成功启发,近年来人们提出了一些基于DNN的方法[13,14,15],以获得更准确的分割结果。Ma等人[13]提出了一种基于图像块的卷积神经网络(CNN),将两个基于CNN的分类网络整合成一个类暹罗(Siamese)子网络,将CT图像和T1加权(T1)图像结合起来完成鼻咽癌分割。Ma等人[14]提出了一种CNN与图割相结合的方法。在该框架下,首先通过整合基于CNN的轴向、矢状面和冠状面三个网络的分割结果来生成初始分割。然后,利用基于三维图形切割的方法对其进行进一步细化。
以往基于深度学习的研究已经为鼻咽癌切分建立了一些优秀的框架。尽管如此,仍有以下不足之处。
- 虽然最近提出了一些基于DNN的框架来提高NPC分割的性能[13,14,15],但这些框架都是基于patch的方法,使用固定尺度的滑动窗口来裁剪图像并确定中心点的类别。这些框架的性能高度依赖于滑动窗口的大小,并且由于严重的计算冗余而非常耗时。
- 这些方法都是基于医学图像的2D切片进行预测,忽略了3D信息在决策中的重要作用。尽管Ma等人[14]提出了一种利用三视图信息进行决策的方法,该框架仍然不能充分利用三维信息。
- 目前,还没有将多模态MRI融合到鼻咽癌自动分割系统的研究。根据Popovtzer等人的研究[16]在高适形放射治疗中综合各种MRI数据,以实现鼻咽癌的GTV勾画应成为常规的临床实践。对于鼻咽癌的勾画,MRI因其优越的软组织对比度而成为首选的影像检查手段[16,3]。此外,不同模式的MRI数据具有不同的视觉特征,对不同的组织和解剖结构有不同的反应。例如,T1加权(T1)MRI适用于检测颅底受累和脂肪平面,而对比增强T1加权(CET1)MRI适用于确定肿瘤范围[3]。图1显示了T1、CET1和T2加权(T2)MRI中NPC反应的一些例子。

图1:不同MRI(T1、CET1和T2)的切片示例,鼻咽癌的轮廓用红线标记。(a)、(b)和©分别是来自T1、CET1和T2的切片。
本文提出了一种多模态MRI融合网络(MMFNet),该网络能够有效地捕捉三维医学图像中多源特征之间的相互依赖关系,通过融合多模态MRI(T1、CET1和T2)来改进鼻咽癌分割。在MMFNet中,包含多个编码器和一个解码器的主干可以用来很好地学习在每种MRI模式中隐含地用于NPC分割的特定模式特征和融合特征。我们提出了一种融合块来融合特定于模态的特征。该算法可分为3D卷积块注意模块(3D-CBAM)和残差融合块(RFBlock),前者是3D医学图像的注意模块,用于重新校准多源特征以突出信息特征和感兴趣区域(ROI),后者将加权后的特征与解码器的高层特征进行融合以保持它们之间的平衡。此外,采用自迁移的训练策略对编码器进行有效的初始化,可以激发不同的编码器充分挖掘特定通道的特征。通过MMFNet,我们结合多个MRI实现了鼻咽癌的准确分割。我们进行了大量的实验,并与相关方法进行了比较,以证明该方法的有效性和优越性。
本文的主要贡献可以概括为以下几点:
- MMFNet是一个多编码器单解码器网络,能够从多个模式的MRI中获取局部的、全局的、跨模式的和特定模式的特征,以实现鼻咽癌的准确分割。
- 在MMFNet中设计了一种新的融合模块,包括3D-CBAM和RFBlock,以学习多模式MRI的互补特征和跨模式相互依赖关系。3D-CBAM是专门为从3D医学图像中重新校准特征而设计的。RFBlock被用来融合特定于通道的特征以供进一步处理。
- 自迁移训练策略可以刺激不同的编码器充分挖掘多通道MRI的通道特征。
其余的论文组织如下。在第二节中,将回顾相关工作。第三节将介绍我们提出的框架。实验结果和分析将在第四节中报告。然后在第五节中,我们将设置一些消融实验来进一步讨论所提出的方法。最后,在第六节中得出结论。
Related work
Multi-modal fusion
在医学图像中,结合CT、T1MRI、T2MRI等多模态图像实现多器官分割[17]和病变分割[18,19],由于不同模态数据集对不同组织的响应不同而被广泛采用。根据对基于多模态融合的医学图像分割深度学习的综述[20],多模态分割网络体系结构可分为输入级融合网络、层级融合网络和决策融合网络。**输入级融合网络[21,22]按通道堆叠多模态图像,并将它们直接馈送到神经网络以做出最终决定。在决策层融合分割网络中,多条路径被设置为分别处理多模式图像,并将最终特征[25]或结果[26]组合起来进行决策。层级融合网络[17,18,23,24]融合中间层中的多源特征,以获得互补和相互依赖的特征。**基于多编码器的方法[17,18]是典型的层级融合网络框架,它使用多个特定于模态的编码器在不同层次上提取特征,并将它们馈送到单个解码器中。对于多源层特征的融合,除了直接合并编码器的特征[18]外,跨多路径[23]链接特征和跨多个编码器[24]链接特征也是很好的策略。
根据一些研究[27,17],基于多个编码器的方法具有更好的捕获互补和跨模式相互依赖的特征的能力。因此,我们提出的框架是基于多编码器的方法。尽管基于多编码器的方法可以结合来自多个模态数据集的信息来捕捉互补和相互依赖的特征,但是特定模态的某些个体特征仍然可以忽略。此外,还没有一个预先训练好的足够强大的3D网络来从医学图像中提取一般特征。为了解决这些问题,我们提出了一种名为自转移的训练策略来初始化编码器,以充分挖掘特定于通道的特征。并将这些特征进一步融合,得到相互依赖的跨通道特征。
在对多源特征进行融合时,也存在一些问题。来自不同MRI模态的低层特征之间的差异,以及低层特征和高层特征之间通道数量的巨大不平衡,如果我们仅仅将它们简单地合并,就会使网络感到困惑。因此,提出了一种融合块来融合低层特征,并准备融合后的特征与高层特征进行融合。融合块可以自适应地重新校准特定于模态编码器的低层特征,并将它们融合成具有相同通道数的相应高层特征的特征,以保持高层和低层特征之间的平衡。
Attention mechanism
在人类感知中,从不同感觉通道获得的信息将被注意力机制加权,即更大的权重将被赋予提供来自世界的可靠信息的感觉流[28]。特别是在人类视觉注意机制中,中高级视觉加工只会选择一部分感觉信息进行进一步加工[29]。注意机制的思想已经成功地在几个基于DNN的图像分类[30,31,32],图像理解[33],目标检测[32]等框架中实现。
对于注意机制,通道注意模块和空间注意模块是两大主题。通道注意模块试图自适应地重新校准基于通道的特征响应,而空间注意模块则强调集中在感兴趣区上的使用。SENet[31]和残差注意网络[30]分别是通道注意模块和空间注意模块的代表。除了使用这两个模块中的一个之外,还存在将这两个模块组合在一起的方法。CBAM[32]是一种轻量级的体系结构,它同时使用空间和通道方向的关注来提高DNN的性能。在该方法中,最大池化输出和平均池化输出都被馈送到共享的多层感知器(MLP)中以获得通道方面的关注。同时,沿着通道轴的相似汇集输出被馈送到卷积块中以产生空间注意。
Methodology
如图2所示,我们的框架是端到端的完全卷积网络,包含三个编码器,用于从三种MRI模式获取3D图像作为输入。编码器网络是一个类似VGG的[34]DNN,它将包含几个3D卷积层的基本块堆叠在一起,然后是最大池化层,以获得更深层次的特征。解码器网络使用3D去卷积层对特征图进行上采样,最终输出的是与输入相同大小的特征图。与NPC分割相关的低层特征和高层特征都可以通过多个编码器和一个解码器的设计来获得。为了有效融合多模态MRI的低层特征,保持高层和低层特征之间的平衡,提出了一种3D-CBAM和RFBlock组成的融合块对多源低层特征图进行重新校准和融合。对于网络的训练,我们提出使用预先训练好的特定于通道的编码器作为多通道模型的初始编码器,该编码器可以从单通道MRI中获取特定于个体的通道特征,用于网络的训练。利用自迁移技术可以有效提高编码器的性能,充分挖掘各类数据的信息特征。

Base encoder-decoder network
受U-Net[35]的启发,我们的基本编解码器网络可以看作是一个由3D卷积层和3D反卷积层组成的U网。通过叠加卷积层和最大汇聚层,编码器网络可以获得更大的接收视场,同时空间分辨率变小。相反,解码器网络由三维反卷积层组成,对特征地图进行上采样,从而使高层特征经过解码器网络时,特征的空间分辨率恢复到原来的尺度。如[36]所述,高层捕获识别目标所必需的高级表示,而较低层捕获低级表示,如纹理,这在我们分割对象时减少微小结构的丢失起着重要作用。因此,鼻咽癌切分应采用内容表示和风格表示相结合的方法。因此,采用跳跃连接层将低层特征和高层特征结合起来。基本编码器块和解码器块的体系结构如图3所示。

图3:基本编码器块和基本解码器块的图示。左:基本编码块。右:基本解码器块。Input1、Input3:上一个块中的要素。Input2:对应编码块产生的特征。Output1,output3:特征,将输入到下一块中。Output2:特征,通过跳跃连接层送入对应的解码器块。
Base encoder network
我们的编码器网络是一个类似VGG的[34]网络,基本块由两个3D卷积层组成。根据[37]的说法,表示大小应该略微减小,以避免存在巨大压缩的瓶颈。因此,3×3×3的三维卷积层和2×2×2的最大池化层是构建我们的网络的首选。经过卷积后,接着是批次归一化层和RELU层。编码块产生两个输出,一个是下一个编码块的输入,另一个是对应的解码块的输入,以实现高级特征和低级特征的结合。共有四个编码块,输出通道数(Out_ch)分别为8、16、32和64。值得一提的是,在最终的编码块之后有一个单卷积层用于细化由编码块下采样的特征,其通道数为64。
Base decoder network
解码器网络的目的是将高层特征映射到目标通道。利用3D反卷积层对特征图进行上采样,然后,级联层在跳跃连接层的帮助下将这些特征与编码器的低层特征相结合。融合后,采用卷积层对这些特征图进行融合。解码器块的输出通道数分别为64、32、16和8。
最后,在最终的解码块之后是以Sigmoid为激活函数的卷积层,以产生最终的分割结果。
Loss function
受[38]提出的Dice系数可以有效解决前景和背景体素数量不平衡的启发,我们将Dice损耗作为网络的优化目标。我们将ground truth表示为G,P表示为预测结果。Dice损失的定义如下所示:
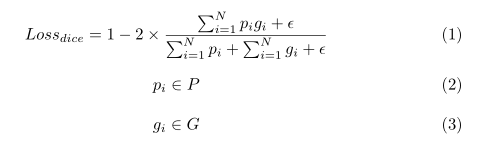
其中eplison是光滑度项,以避免被0除的风险,我们在实验中设置了eplison=1。
Fusion block
融合块的目的是在将来自不同MRI模式的低层特征与高层特征合并之前,对它们进行有效的重新校准和融合。由于多模态MRI对不同组织的响应差异很大,直接融合多个MRI的低层特征是一项艰巨的任务。因此,融合块在3D-CBAM的辅助下,首先对与NPC相关的特征进行重新加权,突出与NPC密切相关的区域。3D-CBAM由通道关注块和空间关注块组成,**通道关注块关注的是“什么”是有意义的特征,空间关注块关注的是哪里是一个有趣的部分。**在重新校准低层特征后,利用RFBlock将它们融合成具有相同通道数的高层特征,以保持它们之间的平衡。它们的体系结构如图4所示。

给出来自多个编码器的三个中间特征图F1、F2、F3∈RC×D×H×W为输入。我们首先在通道轴上对它们进行合并,得到总的原始特征图Fori∈R3C×D×H×W,并将最终使用的融合特征表示为Ffused,整个融合过程可以总结如下:
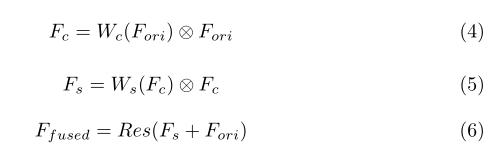
我们将⊗表示为基于元素的乘法,它将自动广播空间关注度(Ws)和通道关注度(Wc)以适应输入特征地图。同时,用通道注意块和空间注意块分别细化后的Fc和Fs表示为特征图,所用的Ffused为最终输出,并用残差融合块进行融合和细化。
Channel attention block
通道注意块的重点是选择性地强调对最终预测有意义的特征映射。SENet[31]利用全局平均池化来获取每个特征地图的平均值,并将其送入MLP以获得每个通道的权重。与SENet相比,CBAM[32]的通道注意块除了使用全局平均池层捕获平均值之外,还使用全局最大池化层来获取特征地图的最大值。并且平均值和最大值都被馈送到共享MLP中。然后,通过加法运算将输出向量组合。
在本文中,为了更好地表示三维医学图像的全局特征,我们对每个三维特征提取stds,并将其与平均值和最大值相结合,生成每个通道特征的权值。我们将获得的stds、平均值和最大值表示为Fstd、Favg、Fmax∈R3c×1×1×1。在MLP方面,由于stds、平均值和最大值之间的分布存在很大差距,我们分别为它们设置了三个MLP。所有这些MLP都是由一个隐层组成的,隐含激活尺寸为R3c/r×1×1×1,**其中r是还原比,我们在实验中设置r=12。并且最终输出通道权重Wc每个通道特征有3c个值。Wc的计算公式如下所示:
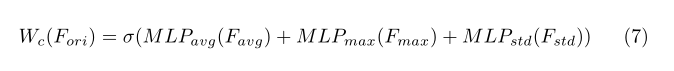
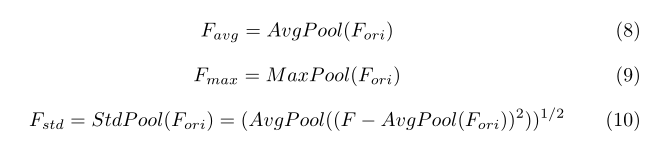
其中σ是产生通道权重的sigmoid激活,范围从0到1。图4(a)显示了通道注意块的结构。
Spatial attention block
空间注意块的目的是利用通道细化后的特征图获得三维空间注意图。在CBAM以前工作的基础上,我们沿着通道轴捕获std、平均值和最大值,并将它们连接在一起,生成三个3D特征块。并将这些特征馈入3×3×3的3D卷积层中,以Sigmoid为激活,以产生Ws。通过元素相乘,信息丰富的区域将被有效地突出显示。空间注意块的架构如图4(b)所示,流程可概括为:

其中,3×3×3表示为单卷积层,核大小为3×3×3,输出通道数为1。
Residual fusion block
在突出显示信息特征和ROI之后,构造残余融合块以融合和细化低级特征。值得一提的是,(Fori+Fs)的通道数量为3c,而准备与融合特征相结合的相应高级特征仅具有c通道。因此,为了保持低级和高级特征之间的平衡,利用具有c通道输出的1×1×1卷积层来融合特征映射并首先减少通道数量。**然后,采用残差块[39]来细化特征映射。**该块由两个卷积层组成,它们都具有1×3×3个内核,第一个之后是批量归一化层和ReLU层。**我们可以使用以下等式来总结这个过程。
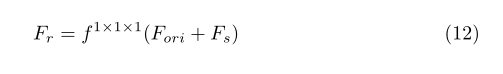
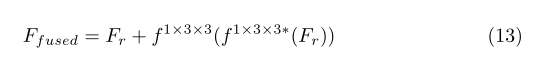
其中1×1×1卷积层后的Fr是特征图,f1×3×3∗表示为1×3×3卷积层,然后是批归一化层和RELU层。
Self-transfer learning

转移学习[40]利用一个强大的预先训练的网络作为特征提取器,是提高新系统性能的一种流行的技巧。因此,使用在ImageNet中预先训练的网络作为分割网络的编码器是自然图像中的常见操作[41,42]。然而,由于三维医学图像的复杂性和成像技术的多样性,目前还没有一个足够强大的三维预训练模型可以作为各种三维医学图像的初始特征提取器。特别是对于多模态磁共振成像,每种模态的图像都有自己独特的成像风格,很难得到一个可以一概而论的特征提取器。此外,通过多编码器单解码器网络的设计,可以提取互补信息和跨模态的相互依赖关系,而忽略特定模态的某些个体特征。为了解决这些问题,我们提出了一种称为自转移的初始化技巧来有效地初始化编码器,并充分挖掘不同模式MRI的特征。根据实验结果,基于多编码器的模型通过使用自迁移可以获得相当大的性能改善。
具体而言,模态特定模型可以有效地从单一模态数据中捕获个体信息特征,而多模态模型旨在从多模态数据集中获得相互依赖和互补的信息。因此,在多模态模型中,单个模态的一些单独特征可能被忽略。因此,我们建议自我转移充分挖掘模态特定特征。图5是自我转移的图示。**第一步是分别训练三种模态特定的编码器-解码器模型。然后,这些预先训练的编码器将被用作多模态模型的初始编码器。**与具有随机初始化的原始编码器相比,这些编码器具有更大的能力来从MRI的特定模态完全挖掘各个特征。同时,融合块和解码器可以有效地融合这些特征以获得用于最终预测的信息特征。我们将在下面的文章中设置几个实验来证明自转移可以增强分割系统。
Experiment and Comparations
Data and Prepocessing
Dataset
在山东大学附属山东肿瘤医院进行了149例患者的T1、CET1和T2三种MRI检查。采用飞利浦 Ingenia 3.0TMRI系统进行扫描。CET1和T2都与T1对齐。不同的3D图像可能具有不同的分辨率,例如,它们可能具有沿X和Y轴的0.33 mm和0.69 mm的采样间隔,以及沿Z轴的3.5 mm到5.5 mm的采样间隔(即相邻截面图像之间的间隔)。因此,我们对这些3D图像进行重新采样,使它们在X轴和Y轴上具有相同的间距**(0.5 mm)**,同时保持其各自的Z间距不变,以避免获得不真实的图像。重新采样后,3D图像的大小从[24,387,387]到[56,520,520]不等。
ground truth是由一位经验丰富的放射科医生创造的,并逐层标记。
Preprocessing
预处理主要包括灰度归一化和感兴趣区域裁剪。我们利用了[43]中提出的体内亮度归一化方法,有效地处理了成像配置的差异和不一致的体背景比的影响。归一化后,根据归一化数据的分布直方图,对数据进行限值裁剪,降低了数据的复杂度。通过对鼻咽癌区域数值的统计分析,将T1、T2和CET1值分别设置为[−2,1]、[−3,2]和[−2,3.5]。
我们使用滑动窗口来裁剪ROI并将它们送入网络。具体地说,我们首先使用OTSU得到原始MRI的3D包围盒(3D-BBox),然后根据3D-BBox的中心点裁剪出一个16×256×256的区域。滑动窗口沿Z轴滑动,滑动步长为4。当输入训练样本时,我们进行动态数据增强。应用的操作包括从(−4,−32,−32)到(4,32,32)的随机中心偏移、从−5◦到5◦的XY平面上的随机垂直翻转和随机旋转。预处理的图示如图6所示。

Evaluation metrics
Dice Similarity Coefficient (DSC): Dice相似系数旨在评估预测结果和ground truth的重叠率。DSC可以写成:

DSC在0~1之间,预测结果越好,DSC越大。
Average symmetric surface distance (ASD): 它是显示两个图像体积之间所有距离的平均值的度量。ASD表示如下:
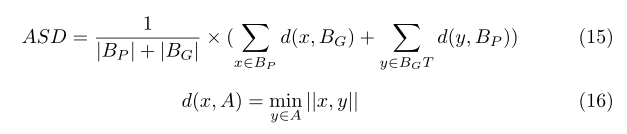
其中||.||表示欧几里得距离。Bp和Bg表示预测§和ground truth(G)的体积表面。和|.|是点数。
Hausdorff Distance (HD): 它显示从一个体积曲面中的一点到另一个曲面中最近的点的最大距离值。其表述如下:
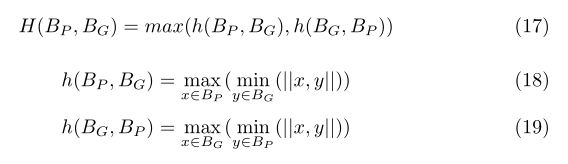
Experiments setting
MMFNet(MMFNet+Multi-MLP+stdPool+Self-Transfer)由三个编码器(T1、T2和CET1)、融合模块和一个解码器组成。通道注意模块中有三个MLP。通道注意块和空间注意块都包含std-pooling、max-pooling和average-pooling。在训练阶段,我们首先训练三个特定于模态的网络,然后将预先训练好的编码器作为MMFNet的初始编码器。对于这些通道特定网络的训练,我们将Adam[44]设置为优化器,学习率设置为10−3。而对于MMFNet的训练,我们首先冻结编码器前5个epoch的参数,以10−3的学习速率用Adam预热解码器。待解码器预热后,我们以10−4的学习率更新MMFNet的解码器和编码器。所有MMFNet和特定通道网络的批量大小为8。我们将最大epoch设置为100,网络每个epoch更新75次。
MMFNet采用五次交叉验证进行评估。并将25%的训练数据划分为验证数据,以选择最佳模型,减少过拟合。同时,如果验证损失在10个周期内没有减少,我们使用提前停止策略来停止训练,以减少过拟合。
我们的实验是在工作站平台上进行的,采用Intel®Xeon®CPU E5-2620 v4@2.10 GHz、64 GB RAM和2x NVIDIA Titan XP GPU以及12 GB GPU内存。该代码是在Windows10中用pytorch 0.4.1实现的。
Comparative experiments
在这一小节中,我们设置了大量的对比实验来展示MMFNet的性能。这些方法如下所述:
1)基于patch的CNN[15,14],它利用滑动窗口捕捉单模MRI的patch来判断中心点是否属于肿瘤。2)基于多模态patch的CNN[13]是一种很好的方法,它将多个基于patch的CNN集成到一个类似Siamese的子网中,以基于鼻咽癌的多模态医学图像进行预测。3)U-Net[35],这是一种新的端到端分割网络,广泛应用于医学图像分割。4)三维U-Net[45],这是U-Net的三维视觉。5)输入级融合网络[21],其将不同形式的MRI按通道堆叠作为网络的输入。我们集中了三个体积的MRI作为不同的输入通道,编码器和解码器的结构如3.1节所述,同时我们将编码器的通道数设置为原始编码器的三倍,以保持低层特征的数量与MMFNet相同。6)合并编码器的特征[18],设置三个特定于通道的编码器来捕获低级特征,并设置一个解码器来融合低级和高级特征。7)跨多路径连接特征[23],这为不同形式的MRI构建多个流,并跨这些流连接特征。8)跨多个编码器连接功能,为每个通道MRI设置单独的编码器,并在不同的编码器之间建立跳跃连接。9)决策级融合,融合来自特定通道路径的最终特征以做出最终决策[25]。
Results
Comparison with ground truth MMFNet的一些预测结果如图7和图8中的2D图像和3D图像所示。如图所示,虽然NPC的形状和大小各不相同,但MMFNet仍然可以准确地确定NPC的区域,并获得准确的肿瘤轮廓。通过对图7中2D图像的分析,MMFNet具有融合多模态MRI的能力,以减少由于邻近组织与NPC之间的强度相似而带来的混乱。MMFNet的平均DSC、平均ASD和平均HD值如表1所示。MMFNet的DSC=0.7238,平均ASD=2.07 mm,平均HD=18.31 mm。

图7:提出的MMFNet在2D图像中的预测结果。从上到下有对应的T1、T2和CET1图像。放射科医生创建的边界用红线标记,预测的边界用蓝线表示。DSC值是该单片的Dice相似系数。

图8:MMFNet的3D预测结果示例。第一行是ground truth,第二行是MMFNet预测的掩码。

Comparison with related works
表1报告了不同方法的平均DSC、平均ASD和平均HD值。不同方法的预测掩码如图9和图10所示,它们分别以2D和3D图像表示结果。通过综合分析这些结果,提出的MMFNet实际上具有以下特性:
(i)它直接融合3D MRI图像,而不是2D切片。因此,它可以有效地利用MRI相邻切片中的有意义信息来实现鼻咽癌分割。如表2所示,与基于2D图像的最佳方法(基于多模态patch的CNN)相比,MMFNet可使平均DSC、平均ASD和平均HD值分别提高0.1226、8.52 mm和81.19 mm。图10显示基于3D的方法比基于2D的方法具有更少的孤立区域(假阳性)。
(ii)通过融合多模态磁共振成像和多编码器网络对NPC进行分割。因此,它可以从不同形式的MRI中学习互补和相互依赖的特征,以便做出最终决定。此外,与输入级融合网络和决策级融合网络相比,层级融合网络(包括MMFNet)能够有效地提取不同模式磁共振成像的信息特征,融合低层特征和高层特征。
(iii)使用融合块融合来自不同MRI模式的低层特征,并准备这些低层特征用于与高层特征的融合。因此,它可以更有效地融合来自不同来源的信息。它还使用自转移策略来初始化NetWerk。因此,它可以激励编码器从特定模态的MRI中充分挖掘有意义的特征。并最终将基于多编码器的网络(合并编码器的特征)在平均DSC、平均ASD和平均HD上分别提高了0.264、1.10 mm和11.88 mm。

图9:预测结果在单个切片图像中,从上到下有对应的T1、T2和CET1图像。绿色区域表示T点,红色和蓝色区域表示P和N点。(a)ground truth。(b)基于patch的CNN(CET1)。©基于多模态patch的CNN。(d)U-Net(CET1)。(e)3D UNet(CET1)。(f)输入级融合。(g)合并编码器的特征。(h)MMFNet+Multiple-MLP+stdPool+Self-transfer。

Discussion
在这一小节中,我们设置了广泛的消融实验,以展示我们提出的融合块和自转移的有效性。基线是基于多编码器的网络(合并编码器的功能),它为每个通道设置单独的编码器,并将合并的功能直接馈送到单个解码器。
The design for 3D-CBAM 基于MMFNet的3D-CBAM设计是3D-CBAM的一个简化版本,它在通道注意模块中使用共享的MLP,同时使用最大池化输出和平均池化输出来获得通道关注权重和空间关注权重。接下来,针对不同的全局特征,将单个共享MLP修改为多个MLP。之后,我们设置了几个实验来寻找添加std-pooling输出的最佳选择。
根据表2的结果,3D-CBAM的最佳设计是在通道注意块中使用多个MLP,并且在通道注意块和空间注意块中都使用std-pooling。利用std-pooling输出可以提供更充分的3D图像的全局信息,并且多个MLP的设置适合于处理具有不同分布的多个特征(std-pooling、max-pooling和average-pooling的输出)。
图11显示了空间注意力系数的一些例子。我们可以看到,在训练阶段的开始,几个位置可能会开火,然后能量将在ROI上慢慢积累,从而减少对假阳性的关注。
The contribution of self-transfer 在设置多个实验寻找3D-CBAM的最佳设计后,我们实现了对这些模型的自迁移,以考察其有效性。我们首先训练了三个特定于通道的编解码器网络。然后,这些预先训练好的编码器将作为多个具有不同融合块的多模态网络的初始特征提取器。
表2中的结果表明,利用自迁移可以刺激编码器从MRI中捕获更多有意义的鼻咽癌分割特征。与没有自迁移的方法相比,本文实现的所有具有自迁移的方法在评价指标方面都有更好的性能。因此,自迁移是基于多编码器的网络实现基于多模态MRI的鼻咽癌分割的一种很好的策略。
The choice of MRI 在论证了MMFNet的有效性之后,我们又设置了几个额外的实验来寻找MRI的最佳选择。我们设置了三个带有两个编码器的MMFNet,以显示仅基于两种MRI模式的方法的结果。
如表2所示,我们得出的结论是,融合所有形式的MRI(TI、T2和CET1)可以获得最好的结果。不同形式的MRI对不同的组织有不同的反应。将所有MRI结合起来,获得互补和相互依赖的信息,对鼻咽癌分割具有重要意义。
MMFNet的一些典型预测结果如图12所示。值得一提的是,与放射科医生手动标记相比,我们提出的网络具有极强的时间友好性。具体地说,我们提出的方法只需要大约9秒就可以实现对患者的鼻咽癌勾画,而经验丰富的放射科医生需要10到20分钟才能完成。
Conclusion
本文提出了一种基于T1、T2和对比度增强T1的多模态MRI融合网络(MMFNet)来分割鼻咽癌(NPC)。为此,MMFNet的主干被设计成一个基于多编码器的网络,它可以很好地学习在每种MRI模式下隐含用于NPC分割的低层和高层特征。在MMFNet中使用融合块来有效地融合来自多模态MRI的低层特征。它包含一个3D-CBAM和一个RFBlock,用于重新校准多源特征图并对其进行融合。为了有效地初始化MMFNet的特征提取器,提出了一种自转移的训练策略。实验表明,MMFNet能够很好地分割鼻咽癌,准确率较高,多模态MRI的应用对鼻咽癌分割具有重要意义。特别是与已有的U-Net、3D U-Net等基于多模态的方法相比,MMFNet在鼻咽癌切分中取得了更好的性能。
Acknowledge 本课题得到了国家自然科学基金委员会(61375020,61572317)、上海市智能医学项目(2018ZHYL0217)和上海交通大学转化医学交叉研究基金(ZH2018QNA05)的部分资助。















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









