










Reverse Attention for Salient Object Detection
2018ECCV
Abstract
得益于深度学习技术的快速发展,显著目标检测最近取得了显著进展。然而,仍然存在以下两个主要挑战阻碍其在嵌入式设备中的应用,低分辨率输出和沉重的模型权重。为此,本文提出了一个准确但紧凑的深度网络,用于高效的显著目标检测。更具体地说,给定最深层的粗略显著性预测,我们首先采用残差学习来学习侧输出残差特征以进行显著性细化,这可以在保持准确性的情况下使用非常有限的卷积参数来实现。其次,我们进一步提出反向关注以自上而下的方式指导这种侧输出残差学习。通过从侧输出特征中删除当前预测的显著区域,网络最终可以探索缺失的对象部分和细节,从而获得高分辨率和准确性。在六个基准数据集上的实验表明,所提出的方法与最先进的方法相比具有优势,并且在简单性、效率(45 FPS)和模型大小(81 MB)方面具有优势。
keywords: 显著目标检测, 反向注意, 边输出残差学习
Introduction
显著物体检测,也称为显著性检测,旨在定位和分割图像中最显眼和吸引眼球的物体或区域。通常用作预处理步骤,以方便后续的各种高级视觉任务,例如图像分割 [1],图像字幕 [2] 等。最近,随着深度卷积神经网络 (CNNs) 的快速发展,显著的对象检测已比传统的基于手工制作的基于特征的方法取得了重大改进。完全卷积神经网络 (FCNs) [3] 的出现,由于其效率和端到端训练,进一步将其推向了新的技术水平。这种架构也有利于其他应用,例如语义分割 [4],边缘检测 [5]。
尽管已经取得了深刻的进步,但仍然存在两个主要挑战,这些挑战阻碍了其在现实世界中的应用,例如嵌入式设备。一种是基于FCNs的显著性模型产生的显著性图的分辨率低。由于CNN体系结构中反复的跨步和池化操作,不可避免地会失去分辨率和难以细化,从而无法准确定位显著对象,尤其是对于对象边界和小对象。另一种是现有深度显著性模型的重大和冗余大。从图1中可以看出,所有列出的深度模型都大于1 00 MB,这对于预处理步骤来说太重了,无法应用于后续的高级任务中,并且对于嵌入式设备来说也不是有效的存储器。
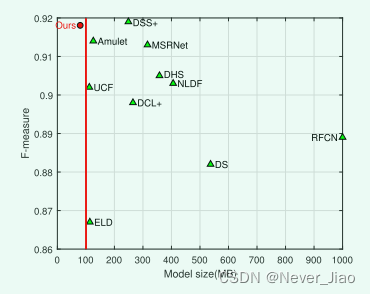
Fig. 1. ECSSD上最近基于深度CNN的显着性检测模型的最大F度量,包括DS [6],ELD [7],DCL [8],DHS [8],RFCN [9],NLDF [10],DSS [11],MSRNet [12],Amulet[13] 、UCF [14] 和我们的 (红色圆圈)。可以看出,所提出的模型是唯一一个小于100 MB的模型,同时通过最先进的方法实现了可比的性能。
已经探索了多种解决方案,以提高基于FCNs的预测的分辨率。早期作品【8,15,16】通常将其与额外区域或基于超像素的流相结合,以高时间成本为代价融合各自的优势。然后,构建一些简单但有效的结构,将浅层和深层CNN特征的互补线索结合起来,分别捕获低级空间细节和高级语义信息,如跳跃连接【12】、短连接【11】、密集连接【17】、自适应聚合【13】。这种多级特征融合方案在语义分割[18,19]、边缘检测[20]、骨架检测[21,22]中也发挥着重要作用。然而,在复杂的现实场景下,尤其是在处理具有不同尺度的多个显著对象时,现有的古语融合仍然不能用于显著性检测。此外,一些耗时的后处理技能也被应用于细化,例如,基于超像素的过滤器【23】,全连接条件随机场(CRF)[8,11,24]。然而,据我们所知,目前还没有考虑到轻量级模型和高精度的显著性检测网络。
为此,我们提出了一个准确而紧凑的深度显著目标检测网络,该网络实现了与最先进的方法相当的性能,从而实现了实时应用。通常,由于较大的感受野和模型容量可以捕获更多语义信息,因此具有较大内核大小的更多卷积通道会在显著目标检测中获得更好的性能,例如,在最后一个侧输出中有 512 个内核大小为 7×7 的通道DSS [11]。以不同的方式,我们将残差学习 [25] 引入 HED [5] 的架构中,并将显著目标检测视为超分辨率重建问题 [26]。鉴于 FCN 的低分辨率预测,学习边输出残差特征以逐步对其进行细化。请注意,它只能使用 64 通道的卷积和每个侧输出中 3×3 的内核大小来实现,其参数明显少于 DSS。
类似的残差学习也被用于骨骼检测[21]和图像超分辨率[27]。 然而,由于其具有挑战性,如果我们直接将其应用于显着目标检测,其性能还不够令人满意。 由于大多数现有的深度显著性模型都是从图像分类网络中微调出来的,微调后的网络在残差学习过程中会无意识地关注具有高响应值的区域,如图 5 所示,从而难以捕获残差 细节,例如对象边界和其他未检测到的对象部分。 为了解决这个问题,我们提出了反向注意力以自上而下的方式指导侧输出残差学习。 具体来说,对深层的预测进行上采样,然后对其进行反向加权以对其相邻的浅侧输出特征进行加权,从而快速引导网络专注于未检测到的区域进行残差捕获,从而获得更好的性能,如图 2 所示。

Fig. 2. 视觉对比DSS【11】(顶行)、我们的方法(中间行)和反向注意(底行)分别在不同侧输出中产生的显著性图。可以清楚地看到,显著性图的分辨率从深侧输出逐渐提高到浅侧输出,我们基于反向注意的侧输出残差学习的性能比短连接好得多【11】。
总而言之,本文的贡献可以得出以下结论 😦 1) 我们将残差学习引入HED的体系结构中,以进行显著的对象检测。借助学习到的侧输出残差特征,与现有的深度显著性网络相比,可以以更少的参数逐渐提高显著性图的分辨率。(2) 我们进一步提出反向关注引导侧产出残差学习。通过擦除当前预测,网络可以快速有效地消除丢失的对象部分和残差细节,从而显着提高性能。(3) 受益于上述两个组件,我们的方法始终如一地实现了与最先进方法相当的性能,并在简单性、效率 (45 FPS) 和模型大小 (81 MB) 方面具有优势。
Related Work
在过去的两个十年中提出了大量的显著性检测方法。在这里,我们只关注最近最先进的方法。几乎所有这些方法都是基于FCN的,并试图解决常见的问题:如何使用FCN产生高分辨率的显著性图?Kuen等人[28]将循环单元应用于FCN中,以迭代细化每个显著区域。hu等人[23]需要一个基于超像素的引导滤波器作为网络中的一个层,用于边界细化。Hou等人[11]设计了用于多尺度特征融合的短连接,而在Amulet[13]中,多级卷积特征被自适应地聚合。罗等人[10]提出了一种多分辨率网格结构来捕获局部和全局线索。此外,还引入了一种新的损失函数来惩罚边界上的错误。张等人 [14] 进一步提出了一种新的上采样方法来减少反卷积中产生的伪影。最近,进一步结合了扩张卷积[23]和密集连接[17]以获得高分辨率显着图。还有一些进步的工作来解决语义分割中的上述问题。在 [19] 中,提出了跳跃连接来细化对象实例,而在 [29] 中,它被用于构建拉普拉斯金字塔重建网络以进行对象边界细化。
我们没有像上述工作那样融合多级卷积特征,而是尝试学习残差特征以进行低分辨率细化。残差学习的思想最早是由 He 等人[25]提出的,用于图像分类。之后,它被广泛应用于各种应用。柯等人[21] 学习了用于精确对象对称检测的侧输出残差特征。金等人[27]基于残差学习构建了一个非常深的卷积网络,以实现准确的图像超分辨率。
虽然将其应用于显著目标检测是很自然的,但性能还不够令人满意。为了解决这个问题,我们引入了受人类感知过程启发的注意力机制。通过使用顶层信息有效地引导自下而上的前馈过程,它在许多任务中取得了巨大的成功。注意力模型被设计为在 [12,30] 中对多尺度特征进行加权。在 [31] 中,残差注意力模块被用来生成用于图像分类的深度注意力感知特征。在 ILSVRC 2017 图像分类挑战赛中,Hu 等人[32] 通过构建用于通道注意力的 Squeeze-and-Excitation 块获得第一名。 黄等人 [33]设计了一个注意掩码来突出反向对象类的预测,然后从原始预测中减去它,以纠正语义分割中混淆区域的错误。 受到启发但又有所不同,我们以自上而下的方式采用反向注意力来指导侧输出残差学习。 从中受益,我们可以学习到更准确的残差细节,从而带来显著的改进。
Proposed Method
在本节中,我们首先描述所提出的深度显著目标检测网络的整体架构,然后一一呈现主要组件的细节,分别对应于侧输出残差学习和自顶向下的反向注意力。
Architecture
所提出的网络建立在 HED [5] 架构上,并选择 VGG16 [34] 作为骨干网。 我们使用直到“pool5”的层,并选择 {conv1_2, conv2_2, conv3_3, conv4_3, conv5_3} 作为边输出,其相对于输入图像的步幅分别为 {1, 2, 4, 8, 16} 像素。 我们首先通过卷积核大小为 1×1 的卷积将“pool5”的维数降低到 256,然后添加三个 5×5 核的卷积层来捕获全局显著性。由于全局显著图的分辨率仅为输入图像的1/32,我们进一步学习每侧输出的残差特征,以逐步提高其分辨率。具体而言,将具有3×3个核和64个通道的D个卷积层堆叠以进行残差学习。在侧输出残差学习之前嵌入反向注意块。将最浅侧输出的预测输入到sigmoid层中以进行最终输出。整体架构如图3所示,完整配置如表1所示。
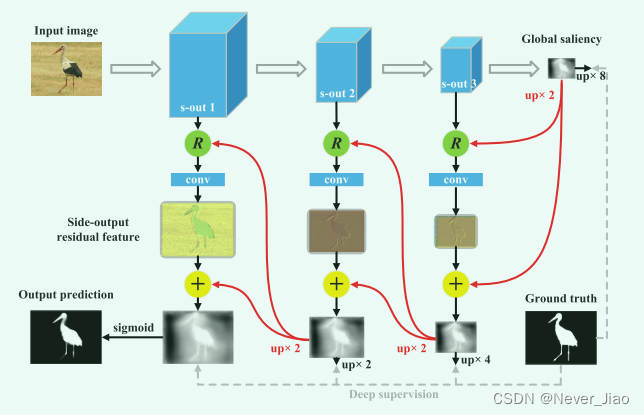
Fig. 3. 拟议网络的总体架构。此处仅列出三个侧面输出以供说明。“R”表示图4所示的提议的反向注意块。可以看出,在对残差单元(黄色圆圈)的输入和输出进行监控的情况下,残差沿堆叠方向减小。
Table 1. 建议网络的配置。 (n, k × k) × D 表示堆叠 D 个卷积层,通道数 (n) 和内核大小 (k),并添加 ReLU 层进行非线性变换。

Side-output Residual learning
众所周知,网络的深层捕获了高级语义信息,但细节混乱,而浅层则相反。基于此观察,多级特征融合是捕获其互补线索的常见选择,但是,当与浅层结合时,它会降低深层的自信预测。在本文中,我们通过采用残差学习来弥补预测的显著性图与ground truth之间的误差,从而以一种不同而更有效的方式实现了它。具体来说,残差特征是通过对设计残差单元的输入和输出应用深度监督来学习的,如图 3 所示。形式上,给定侧输出阶段i+1中因子2的上采样输入显著性图Supi+1,以及在侧输出阶段i中学习的残差特征Ri,则深度监督可以表述为:
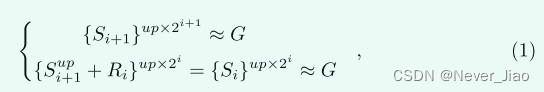
其中,Si是残差单元的输出,G是ground truth,up × 2i表示因子为2i的上采样操作,该操作通过与HED [5] 相同的双线性插值实现。
这样的学习目标继承了以下良好特性。残差单元在不同尺度的预测和ground truth之间建立了快捷连接,这使得更容易纠正错误,具有更高的尺度适应性。一般来说,在相同的监督下,残差单元的输入和输出之间的误差相当小,因此可以用更少的参数和迭代更容易地学习。极端情况下,如果预测与ground truth足够接近,则误差近似为零。因此,构建的网络可以非常高效和轻量级。
Top-down Reverse Attention
尽管为显著性细化学习残差细节是自然而直接的,但在没有额外监督的情况下,网络很难准确地捕获它们,这将导致检测不理想。 由于大多数现有的显著性检测网络都是从仅对小而稀疏的判别对象部分做出响应的图像分类网络中微调而来的,因此它显然偏离了显著性检测任务需要探索密集和完整区域的像素级的预测。为了缩小这一差距,我们提出了一种基于反向注意力的侧输出残差学习方法,用于逐步扩展对象区域。 从在最深层生成的具有高语义置信度但低分辨率的粗显著图开始,我们提出的方法通过从侧输出特征中擦除当前预测的显著区域来引导整个网络顺序发现补充对象区域和细节,其中当前 预测是从更深层上采样获得的。 这种自上而下的擦除方式最终可以将粗略和低分辨率的预测细化为具有这些探索区域和细节的完整且高分辨率的显著图,参见图 4 进行说明。
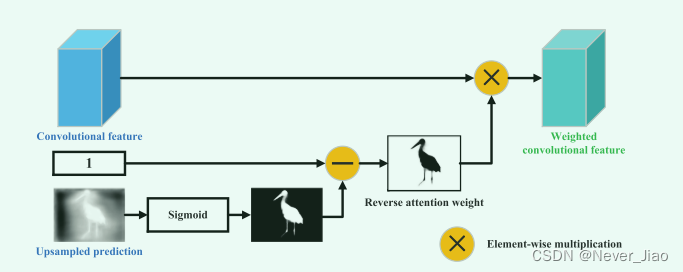
Fig. 4. 建议的反向注意块的图示,其输入和输出分别以蓝色和绿色突出显示。
给定侧输出特征 T 和反向注意力权重 A,那么输出注意力特征可以通过它们的元素相乘产生,可以表示为:

其中z和c分别表示特征图的空间位置和特征通道的索引。侧输出阶段i中的反向注意力权重是简单地通过从1中减去侧输出i+1的上采样预测来生成的,其计算如下:
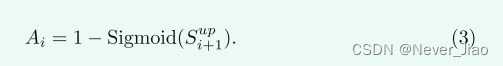
图 5 显示了一些学习到的残差特征的视觉示例,以说明所提出的反向注意力的有效性。可以看出,所提出的网络在反向注意力的帮助下很好地捕获了对象边界附近的残余细节。在没有反向注意力的情况下,它学习了对象内部的一些冗余特征,这对显著性细化无济于事。

Fig. 5. 在没有 (第一行) 和有反向注意 (第二行) 的情况下,建议网络的不同侧输出中的残余特征的可视化。从左到右是显著性图,分别是从侧面输出1到4的最后一个卷积特征。在引起我们的反向关注之后,拟议的网络很好地捕获了对象边界附近的空间细节,这对于显着性的细化是有益的,尤其是在浅层中。最好用彩色观看。
Supervision
如图 3 所示,深度监督应用于每个侧输出级,如 [5,11] 中所做的那样。每个侧输出都会产生一个损失项 Lside,其定义如下:
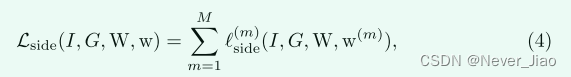
其中 M 表示包括全局显著性在内的侧输出总数,W 表示所有标准网络层参数的集合,I 和 G 分别指输入图像和相应的ground truth。 每个侧输出层被视为具有相应权重 w 的逐像素分类器,其表示为
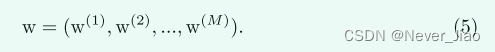
在这里,lm side侧表示第m侧输出的图像级类平衡交叉熵损失函数 [5],该函数通过以下公式计算:
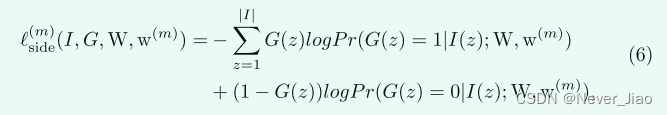
其中 Pr(G(z) = 1|I(z);W, w(m)) 表示在第 m 侧输出中位置 z 处激活值的概率,z 是 saptial 坐标。与 HED [5] 和 DSS [11] 不同,我们的方法中不包含融合层。第一个侧输出的输出在测试阶段的 sigmoid 层之后用作我们的最终预测。
Difference to Other Networks
尽管具有相同的名称,但建议的网络与反向注意网络 [33] 有很大的区别,后者应用反向注意来加权与目标类别无关的预测,以这种方式放大了混淆区域中的反向类响应,从而可以帮助原始分支做出正确的预测。而在我们的方法中,反向注意的使用是完全不同的。它用于从深层擦除自信预测,从而可以指导网络有效地探索缺失的对象区域和细节。
与其他基于残差学习的架构也存在一些显著差异,例如侧输出残差网络 (SRN) [21] 和拉普拉斯重建网络 (LRN) [29]。在 SRN 中,残差特征是直接从 VGG-16 的每个侧输出中学习的,而在本文中,它是在反向注意力后学习的,用于指导残差学习。与 LRN 的主要区别在于 wight mask的使用,它用于加权学习的侧输出特征以在 LRN 中进行边界细化,相比之下,我们在侧输出特征学习之前应用它来进行指导。此外,LRN 中的权重掩码是从深度预测的边缘生成的,由于其低分辨率会遗漏一些目标区域,而在本文中,我们将其应用于所有未检测到的区域进行显着性细化,这不仅很好地细化了对象边界,但也更完整地突出了对象区域。
Experiments
Experimental Setup
提议的网络建立在 HED [5] 和 DSS [11] 的实现之上,并通过公开可用的 Caffe [35] 库进行训练。整个网络使用全分辨率图像进行端到端训练,并通过随机梯度下降法进行优化。超参数设置如下:批量大小(1),迭代大小(10),动量(0.9),权重衰减(5e-4),学习率初始化为1e-8,当训练损失达到平坦时下降10%,训练迭代次数(10K)。在接下来的实验中,所有这些参数都是固定的。源代码将被发布。
我们在6个具有代表性的数据集上综合评估了我们的方法,包括MSRA-B[36],HKU-IS[37],ECSSD[38],pascal-S[39]、SOD[40]和DUT-OMRON[41],,它们分别包含5000、4447、1000、850、300、5168张注释良好的图像。其中,pascal-S和DUT-OMRON比其他的更具挑战性。为了保证与现有方法的公平比较,我们使用与[8,10,11,42]中相同的训练集,并使用相同的模型测试所有的数据集。数据增强也实现了与[10,11]相同的功能,以减少过拟合风险,通过水平翻转增加了2倍。
三个标准和广泛认可的指标用于评估性能,包括精确召回(PR)曲线、F-度量和平均绝对误差(MAE)。通过将二元显著性图与ground truth进行比较,绘制PR曲线,计算精度和召回值对,其中阈值在[0, 255]范围内。采用F-测度来衡量整体性能,定义为精度和召回率的加权调和平均值:

其中 β2 设置为 2 以强调准确率而不是召回率,如 [43] 中所建议的那样。此处仅报告最大 F-Measure 以显示检测器可以实现的最佳性能。给定归一化显著图 S 和ground truth G,MAE 分数由它们的平均每像素差异计算:
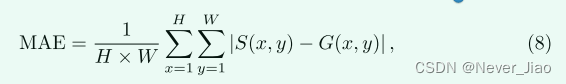
其中 W 和 H 分别是显着性图的宽度和高度。
Ablation Studies
在与最先进的方法进行比较之前,我们首先评估不同设计选项(深度 D)的影响,本节中提出的侧输出残差学习和反向注意力的有效性。
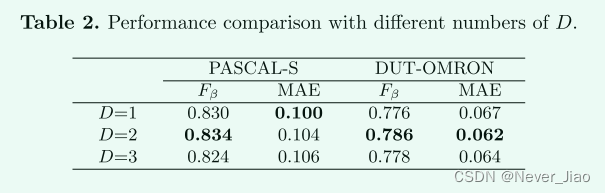
Depth D
我们做了一个实验,通过将深度 D 从 1 变为 3 来观察其对性能的影响。PASCAL-S 和 DUT-OMRON 的结果如表 2 所示。可以看出,当 D= 2可以获得最好的性能。因此,我们在下面的实验中将其设置为 2。
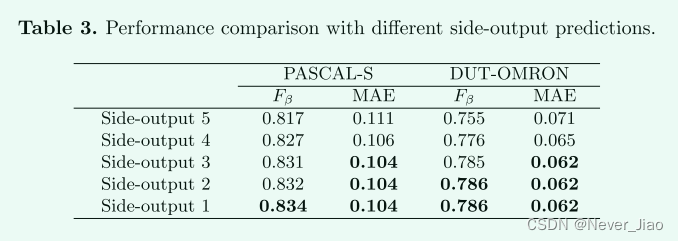
Side-output residual learning
为了研究侧输出残差学习的有效性,我们分别评估了每个侧输出预测的性能,如表3所示。我们可以发现,通过合并更多的侧输出残差特征,性能会逐渐提高。
Reverse attention
如图 5 所示,网络在反向注意力的帮助下很好地位于对象边界。 在这里,我们使用表 4 中报告的 F-measure 和 MAE 分数进行(8)详细比较。从结果中,我们可以得到以下观察结果:(1)没有反向注意力,我们的表现类似于最先进的方法 DSS(没有基于 CRF 的后处理),这表明它的冗余度很大。 (2) 应用反向注意力后,性能大幅提升,具体而言,我们在 F-measure 方面平均获得了 1.4% 的增益,在 MAE 得分方面平均降低了 0.5%,这清楚地证明了它的有效性。
Performance Comparison with State-of-the-art
我们将提出的方法与 10 种最先进的方法进行比较,包括 9 种最近基于 CNN 的方法,DCL+ [8]、DHS [44]、SSD [45]、RFCN [9]、DLS [23]、NLDF [10]、DSS 和 DSS+ [11]、Amulet [13]、UCF [14] 和一种传统的顶级方法 DRFI [42],其中符号“+”表示网络包括基于 CRF 的后处理。请注意,上述方法的所有显著性图都是通过运行源代码或作者预先计算生成的,为了公平比较,不包括基于 ResNet 的方法。
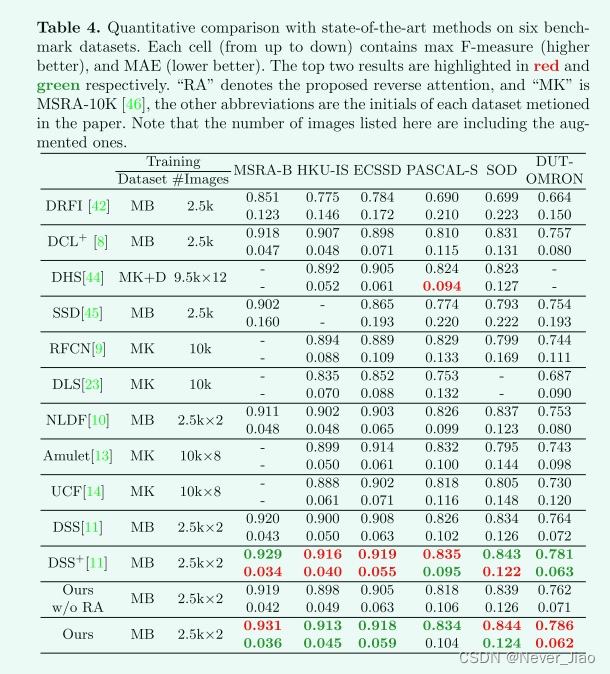
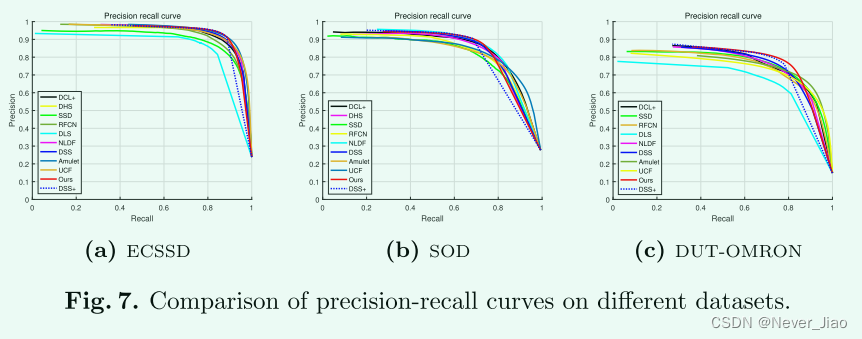
Quantitative Evaluation 表 4 和图 7 报告了与最先进方法的定量比较结果。我们可以清楚地观察到,我们的方法在 F 度量和 MAE 分数方面都显着优于竞争方法,特别是在 具有挑战性的数据集(例如,DUT-OMRON)。 对于 PR 曲线,除了高召回率(召回率>0.9)外,我们还实现了与现有技术相当的性能。与top方法DSS+相比,DSS+使用基于CRF的后处理步骤来优化分辨率,然而,我们的方法仍然可以获得几乎相同(或更好)的总体性能。还需要指出的是,现有的方法使用了不同的训练数据集和数据扩充策略,这导致了不公平的比较。尽管如此,我们的表现仍然要好得多,这清楚地表明了所提出方法的优越性。我们还认为,使用更大的训练数据集和更多的增强训练图像可以获得更大的性能增益,这超出了本文的范围。
Table 4. 在六个基准数据集上与最新方法的定量比较。每个单元格 (从上到下) 包含最大F-measure (更高更好) 和MAE (更低更好)。前两个结果分别以红色和绿色突出显示。“RA” 表示建议的反向注意,“MK” 是MSRA-10K的 [46],其他缩写是论文中提到的每个数据集的首字母。请注意,此处列出的图像数量包括增强的图像。
Qualitative Evaluation
我们还展示了一些代表性图像的一些视觉结果,以展示图6中提出的方法的优越性,包括复杂的场景、显著对象和背景之间的低对比度、具有不同特征 (例如,大小、颜色) 的多个 (小) 显著对象。考虑到所有情况,可以清楚地观察到,我们的方法不仅以较少的错误检测正确地突出突出区域,而且还产生清晰的边界和连贯的细节 (例如,图6的第4行中的鸟的嘴)。同样有趣的是,所提出的方法甚至纠正了ground truth中的一些错误标记,例如,图6的第7行中的左喇叭。然而,在一些具有挑战性的情况下,我们仍然获得了不令人满意的结果,例如,以图6的最后一行为例,对于现有方法来说,完全分割所有突出的对象仍然非常困难。

Fig. 6. 在一些具有挑战性的情况下,与现有方法的视觉比较: 复杂的场景,低对比度和多个 (小) 显着对象。
Execution Time
最后,我们调查了我们方法的效率,并在单个 NVIDIA TITAN Xp GPU 上进行了所有实验以进行公平比较。训练我们的模型只需要不到 2 个小时,相比之下,DSS 大约需要 6 个小时。我们还将 ECSSD 上的平均执行时间与其他五种领先的基于 CNN 的方法进行了比较。从表 5 可以看出,我们的方法比所有竞争方法都要快得多。因此,考虑到视觉质量和效率,我们的方法是迄今为止实时应用程序的最佳选择。

Conclusions
显著目标检测作为一种低层次的预处理步骤,在各种高层次任务中都有很强的适用性,但仍然没有得到很好的解决,这主要取决于以下两个方面:低分辨率输出和重模型权重。在本文中,我们提出了一种精确而紧凑的深层网络,用于有效的显著目标检测。与直接学习不同侧面输出阶段的多尺度显著性特征不同,我们使用残差学习来学习侧面输出的残差特征以进行显著性细化。在此基础上,利用非常有限的参数,逐步提高了由最深卷积层生成的全局显著性图的分辨率。我们进一步提出反向关注,以自上而下的方式指导这种侧输出残差学习。从中受益,我们的网络学习了更准确的残差特征,从而显着提高了性能。广泛的实验结果表明,所提出的方法在定量和定性比较方面均优于最新方法,这使其成为进一步实际应用的更好选择,并且也使其在其他端到端像素级预测任务中具有巨大的应用潜力。尽管如此,全局显著性分支和骨干 (VGG-16) 网络仍然包含大量冗余,将通过在我们未来的工作中引入手工制作的显著性和从头开始学习来进一步探索。















 6984
6984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









