






一.代码练习
1.MNIST数据集分类
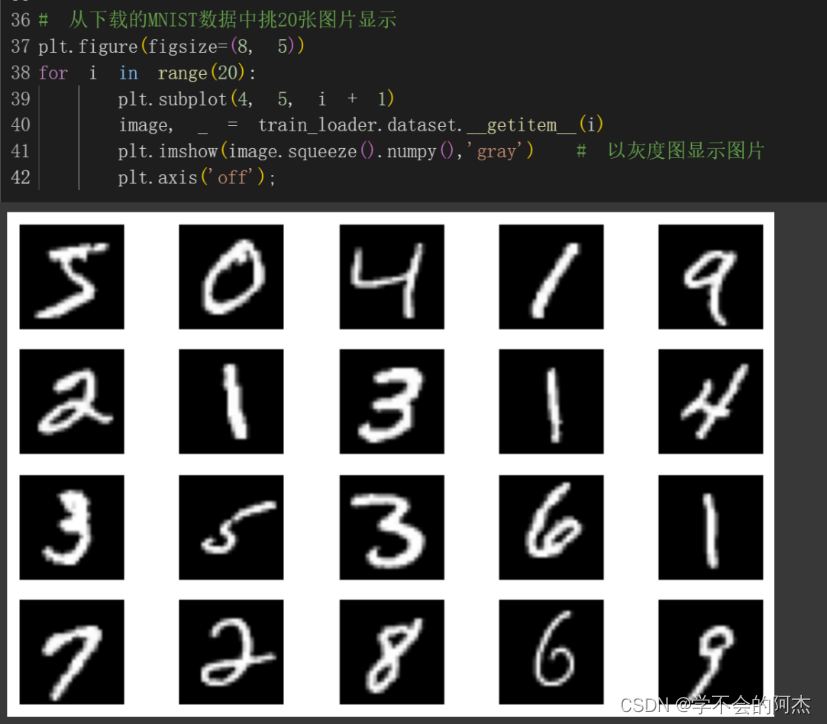
首先将MNIST数据集的训练部分和测试部分分别下载,然后从数据集中挑20张图片,以灰度图的形式显示。
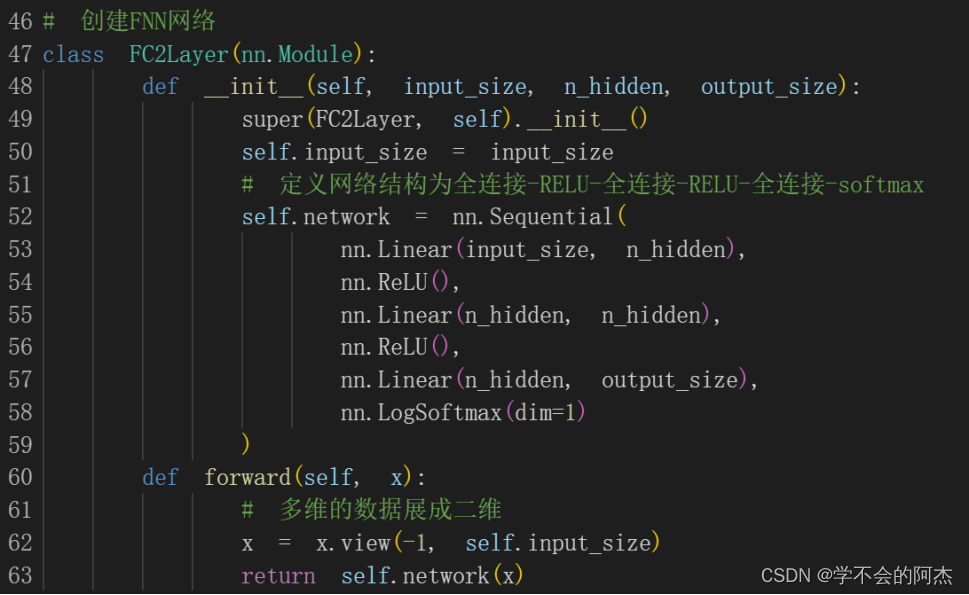
分别创建FNN网络与CNN网络。从网络结构可以看出,FNN网络中只含有全连接层和RELU激活函数,最后输出前加了一个softmax;而CNN网络相比FNN网络减少了全连接层,增加了卷积层和最大值池化层 。
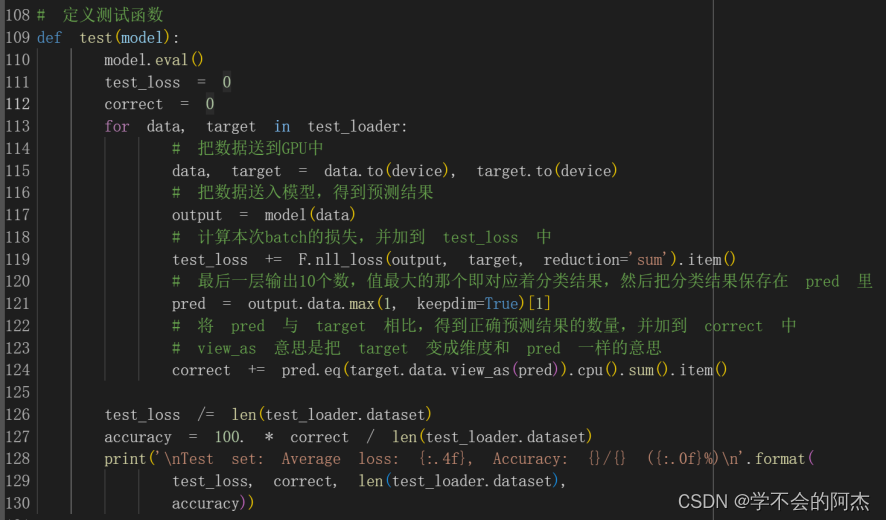
 定义训练函数和测试函数后,分别在FNN网络和CNN网络上进行训练与测试。
定义训练函数和测试函数后,分别在FNN网络和CNN网络上进行训练与测试。

 FNN网络测试结果:
FNN网络测试结果: CNN网络测试结果:
CNN网络测试结果: 
从结果可以看出,同参数数据集下CNN测试结果明显优于FNN,因为CNN网络中包含的卷积层和池化层能够更好的挖掘图片像素间的局部关系。
考虑到CNN的优良特性是由于卷积和池化对图片中特性规律的学习,为了验证这个想法下面将图片的像素点打乱顺序再进行测试。

打乱了像素点后的图片效果如下图所示 重新定义训练函数和测试函数,函数体内容与之前大部分相同,只是添加了perm_pixel函数打乱了像素顺序。
重新定义训练函数和测试函数,函数体内容与之前大部分相同,只是添加了perm_pixel函数打乱了像素顺序。 
FNN网络测试结果: CNN网络测试结果:
CNN网络测试结果: 从结果可以看出,FNN网络的效果与之前没打乱像素顺序时效果差不多;而CNN网络的效果明显下降了不少,甚至不如FNN网络效果好。至此验证了之前的猜想,可见卷积神经网络在打乱了图片像素间的局部关系后就不能起到好的效果了。
从结果可以看出,FNN网络的效果与之前没打乱像素顺序时效果差不多;而CNN网络的效果明显下降了不少,甚至不如FNN网络效果好。至此验证了之前的猜想,可见卷积神经网络在打乱了图片像素间的局部关系后就不能起到好的效果了。
2.CIFAR10数据集分类
CIFAR10数据集包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
注:transforms.Normalize函数中参数给的是0.5是因为PyTorch源码中是这么写的“input[channel] = (input[channel] - mean[channel]) / std[channel]”,故结果就是((0,1)-0.5)/0.5=(-1,1)。

接着展示CIFAR10中的一些图像,并输出第一行的图像标签。
运行结果如下图


接下来定义网络,损失函数,优化器;并训练网络。
 接着我们从测试集中取出8张图片,并展示出他们的标签,然后把图片输入到训练好的模型当中,看CNN网络将这些图片识别成什么。
接着我们从测试集中取出8张图片,并展示出他们的标签,然后把图片输入到训练好的模型当中,看CNN网络将这些图片识别成什么。
下图为测试集中取出的8张照片和他们的标签 下图为图片原标签和CNN所识别出的图片标签,可以看到其中有3个识别错了。
下图为图片原标签和CNN所识别出的图片标签,可以看到其中有3个识别错了。
然后把整个数据集放进训练好的模型,看看表现如何。

运行结果如下图
 可以看到整体的准确率可以达到62%,通过改善网络的结构性能应该可以得到进一步提升。
可以看到整体的准确率可以达到62%,通过改善网络的结构性能应该可以得到进一步提升。
3.使用VGG16对CIFAR10进行分类
VGG模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
其16层网络的结节信息如下:
01: Convolution using 64 filters
02: Convolution using 64 filters + Max pooling
03: Convolution using 128 filters
04: Convolution using 128 filters + Max pooling
05: Convolution using 256 filters
06: Convolution using 256 filters
07: Convolution using 256 filters + Max pooling
08: Convolution using 512 filters
09: Convolution using 512 filters
10: Convolution using 512 filters + Max pooling
11: Convolution using 512 filters
12: Convolution using 512 filters
13: Convolution using 512 filters + Max pooling
14: Fully connected with 4096 nodes
15: Fully connected with 4096 nodes
16: Softmax
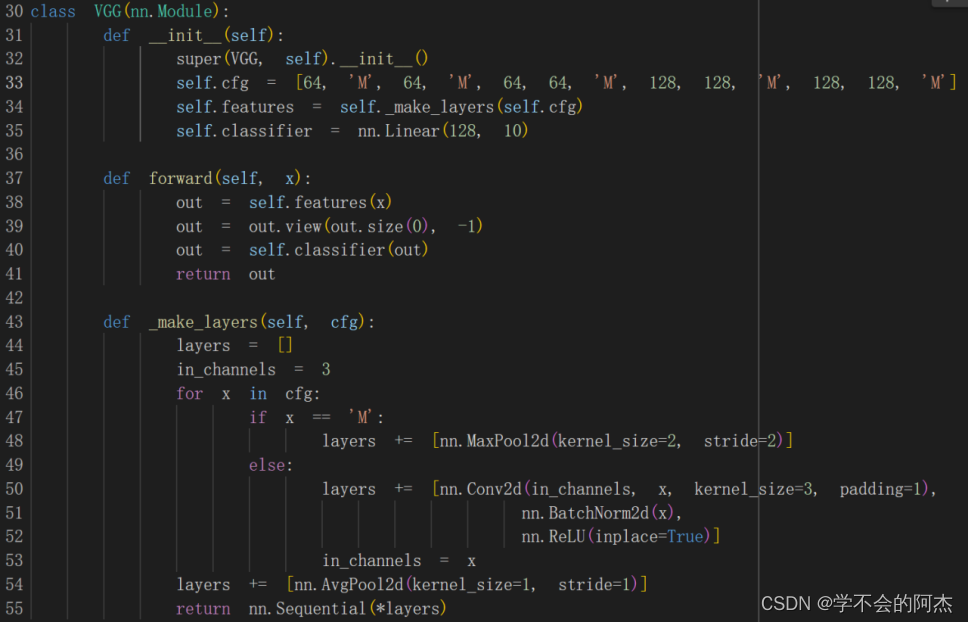
由于VGG16的参数太多,为了方便,将网络结构改的简单一些,具体结构为:
01: Convolution using 64 filters + Max pooling
02: Convolution using 64 filters + Max pooling
03: Convolution using 64 filters
04: Convolution using 64 filters + Max pooling
05: Convolution using 128 filters
06: Convolution using 128 filters + Max pooling
07: Convolution using 128 filters
08: Convolution using 128 filters + Max pooling
09: Softmax
简化后的结构运行起来速度还能快一些,不然等运行结果要等好久。
之后将网络进行10轮训练,并把整个数据集放进训练好的模型,具体的操作和CNN对CIFAR10分类的操作相同。

运行结果如下图

可见通过一个简化版的VGG网络就能将准确率从CNN网络的62%提升到81.35%。
二.问题总结
1. dataloader 里面 shuffle 取不同值有什么区别?
dataloader函数中shuffle取True表示每次加载的数据是随机的;取False表示加载的数据是顺序固定的。
2.transform 里取了不同值,这个有什么区别?
transform(数据转换)的不同取值能对数据进行统一的处理,例如归一化、标准化、正则化、旋转、降维等操作。
3.epoch 和 batch 的区别?
一次epoch是指整个训练集在神经网络中进行了一次训练(正向传播+反向传播);batch是指将一次epoch分为多个batch,每次只对一个batch进行一次训练(正向传播+反向传播)然后对下一个batch进行训练。
4.1x1的卷积和 FC 有什么区别?主要起什么作用?
1x1的卷积是指卷积核为1*1大小的卷积层,它能够通过激活函数对输入的数据进行非线性变换,由于是卷积层能够实现参数共享,所以所需要的参数数量远小于全连接层,它能起到升/降维的作用;FC(全连接层)是将输入数据与一个权重矩阵进行乘积,并将结果进行加权求和得到输出,它能起到分类的作用。
5.residual leanring 为什么能够提升准确率?
残差学习通过残差网络结构使得网络能够直接学习出从输入到输出间的差异,通过映射的方式简化了非线性计算的过程,因此可以避免梯度消失的问题,从而提升准确率。
6.代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
传统的LeNet网络使用的是sigmoid激活函数,而AlexNet使用的是ReLU函数;传统的LeNet网络使用的是平均值池化,而AlexNet使用的是最大值池化。
7.代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
增加padding或者使用1*1的卷积核。
8.有什么方法可以进一步提升准确率?
使用性能更好的网络;选择更合适的激活函数、损失函数、优化器;加入dropout防止过拟合等。















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









