






一.代码练习
1.pytorch基础练习
区分tensor与Tensor:
torch.Tensor()是python类,默认张量类型为float。
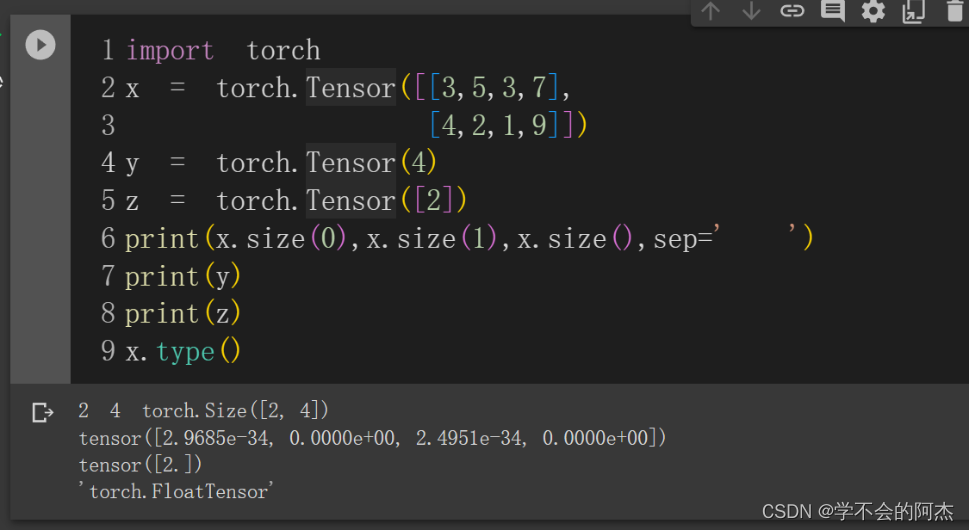
可见y = torch.Tensor(4)中4是一个标量,作为生成张量的大小传入,生成的y为一个大小为4的浮点型张量。把Tensor(4)改为Tensor([2]),z就成为一个数值为2的张量了。
而torch.tensor()是一个python函数,其函数原型为
torch.tensor(data, dtype=None, device=None, requires_grad=False)
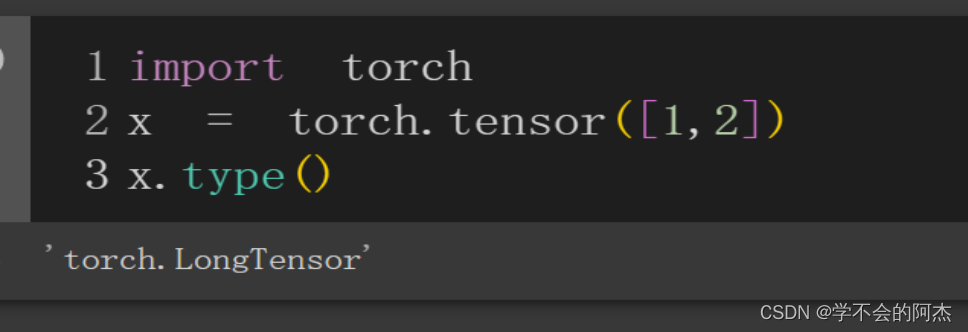
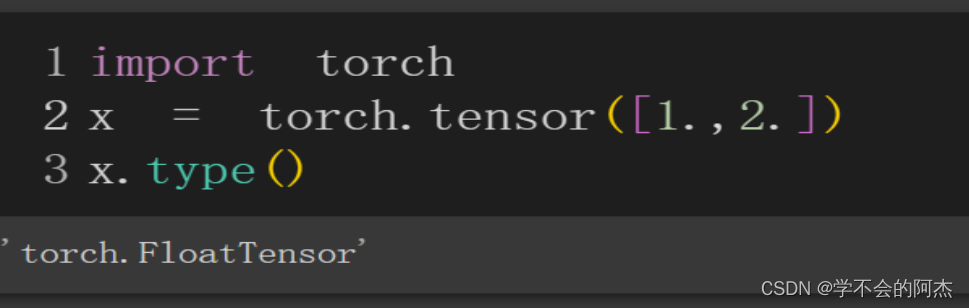
torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor、torch.FloatTensor和torch.DoubleTensor张量。

下面是生成10000个随机数,并按照100个bin统计直方图

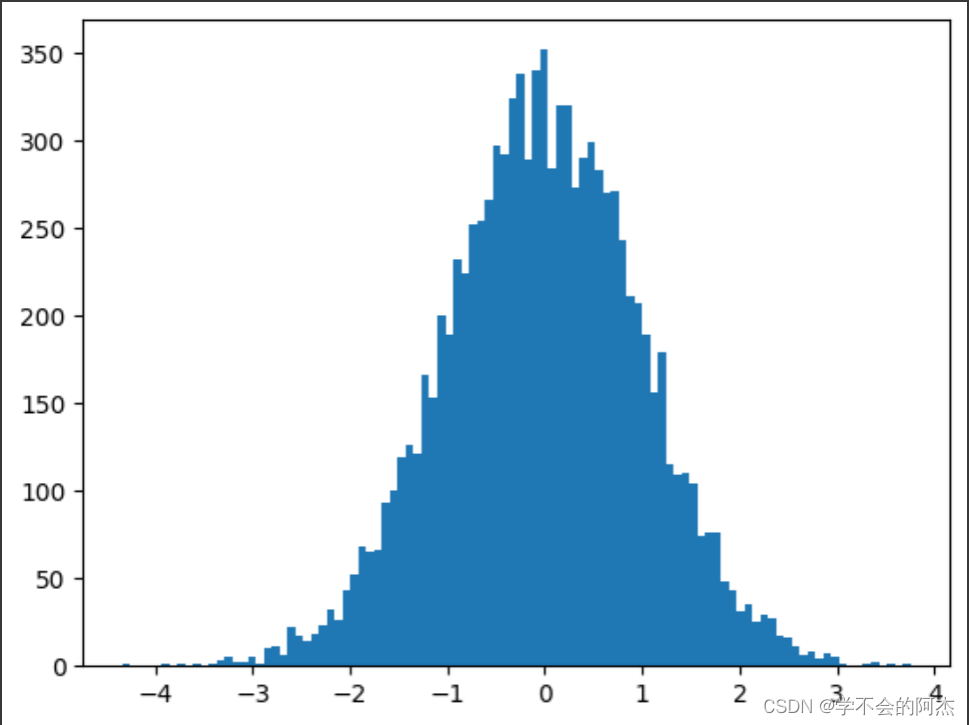
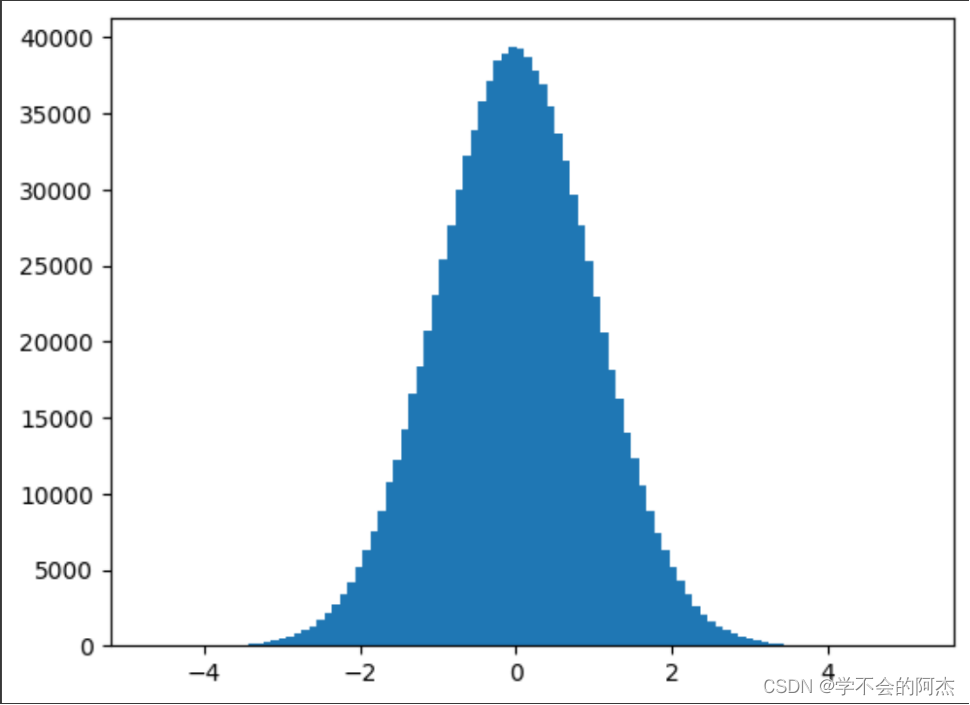
下面是生成10^6个随机数,并按照100个bin统计直方图,可见数据足够多时正态分布就能体现的非常明显。

2.螺旋数据分类
2.1设置样本
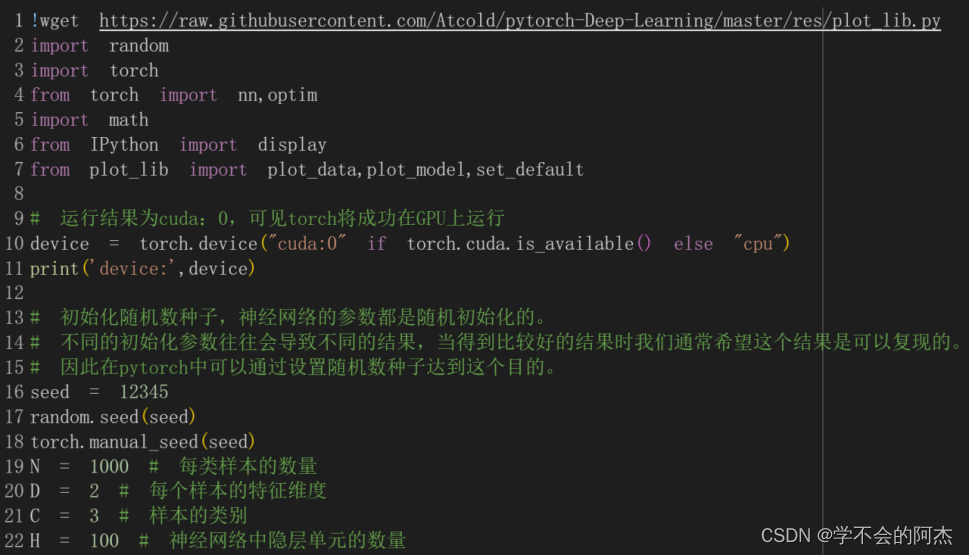
首先引入基本的库,然后初始化样本所需的几个参数:
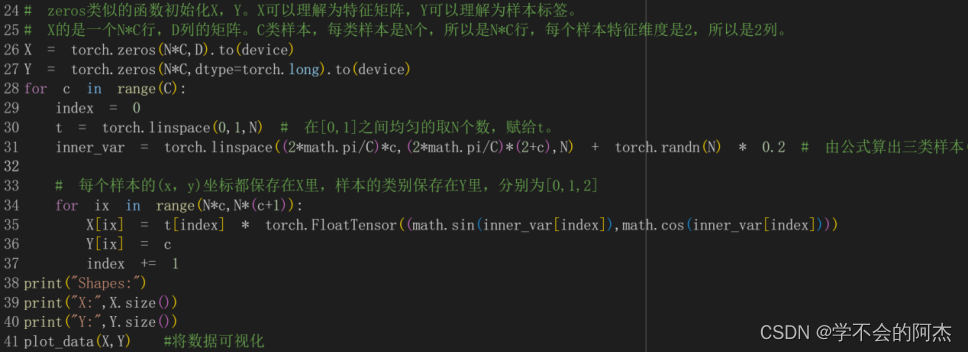
然后初始化X和Y。X可以理解为N*C行,D列的特征矩阵,Y可以理解为每个样本的种类标签。
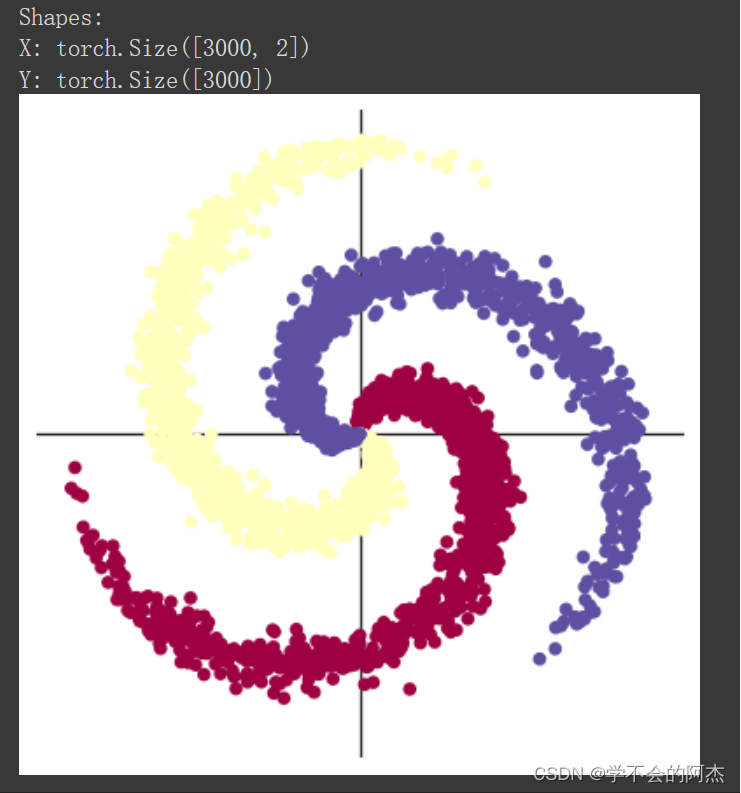
运行后可获得一个螺旋形的样本
2.2构建线性模型分类


需要注意的是,每一次进行反向传播之前都需要先把梯度置0。
使用print(y_pred.shape)可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本都有3个预测结果,其中值最大的即为该样本预测的类别,保存在y_pred的一行里。score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在score中,所在的位置(即第几列的最大)保存在predicted中。


上图所展示的是以第10行为例输出所得到的结果

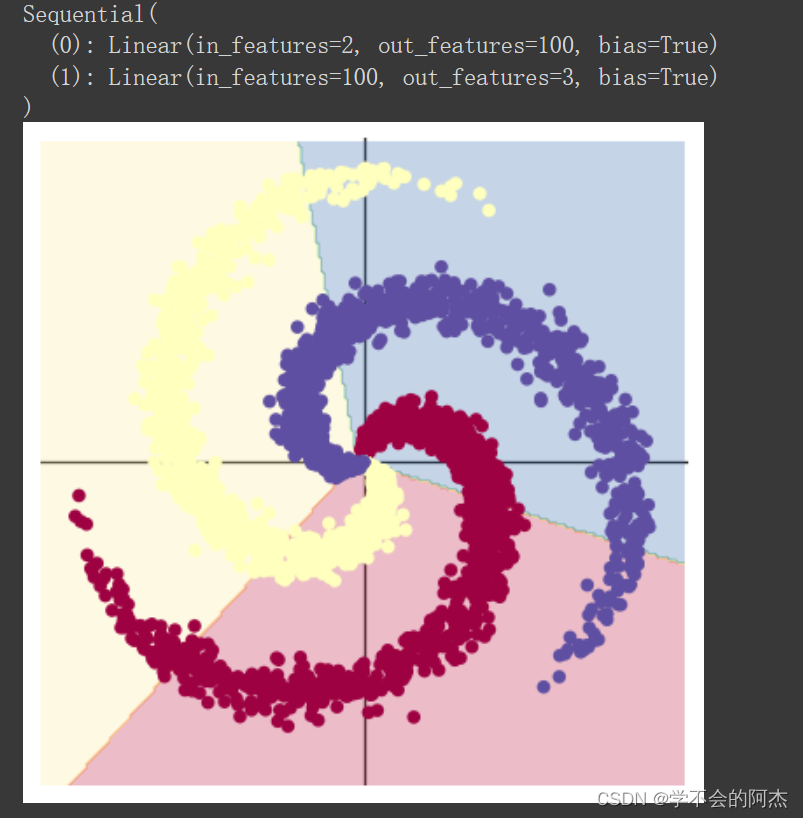
上面使用print(model)把模型输出,可以看到有两层:
第一层输入为2(因为特征维度为主2),输出为100;第二层输入为100(上一层的输出),输出为3(类别数)。
从上面图示可以看出,线性模型的准确率最高只能达到50%左右,对于这样一个螺旋形的数据分布,仅用线性模型难以将其准确分类。
2.3构建两层神经网络分类


通过在线性模型的两层间增加一个ReLU层,可见预测结果得到了明显改善。
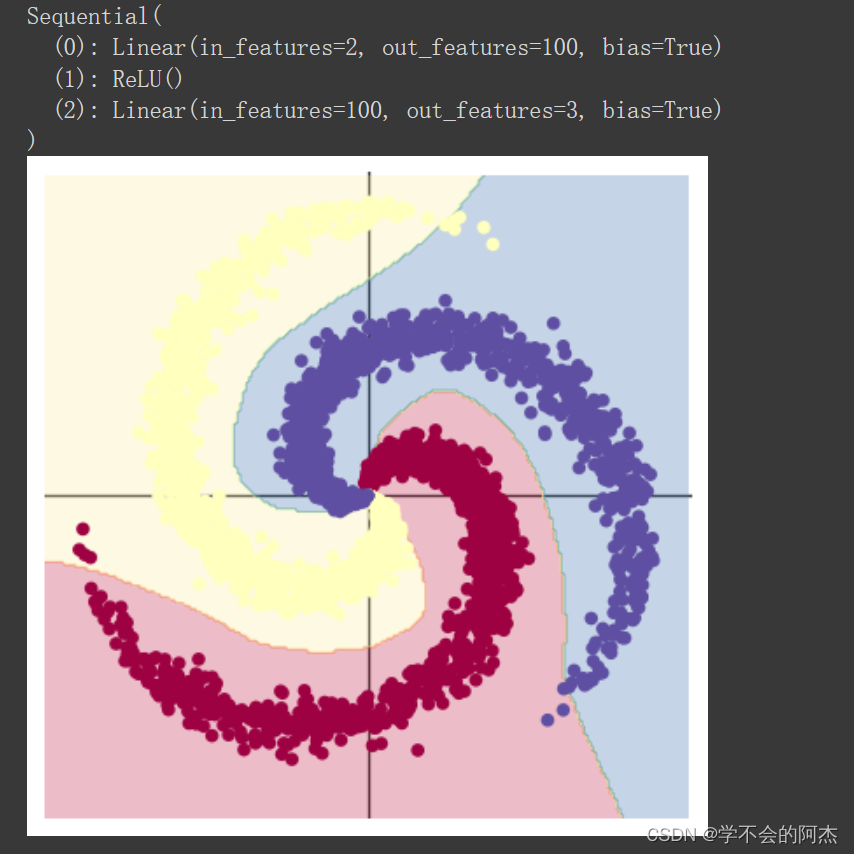
二.问题总结
1.AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
AlexNet使用的是ReLU函数,而LeNet网络使用的是sigmoid激活函数。ReLU函数比sigmoid函数计算上更为简单,尤其是在处理大规模数据时ReLU的优势更加突出。
2.激活函数有哪些作用?
激活函数能够加入非线性因素,没有激活函数的模型无法拟合非线性的函数。
3.梯度消失现象是什么?
梯度消失现象是由梯度下降操作导致的。梯度下降本质是为了求得目标函数的一个极小值,而根据链式求导法则可知,当链式求导过程中有一个值特别小,最终就会导致整个链式求导结果特别小,甚至于消失。
4.神经网络是更宽好还是更深好?
相较于更宽还是更深好,深度对函数复杂度的贡献是指数级增长的,而宽度只是线性增长。但要注意的是也不是越深越好,具体跟任务的复杂度有关。
5.为什么要使用Softmax?
Softmax适用于多分类过程,它将多个输出映射到(0,1)区间当中,相当于输出结果转化为一个概率表示,这样就可以根据概率大小较为容易的选取目标。
6.SGD和Adam哪个更有效?
我觉得Adam更有效,因为我用Adam才能训出较好的效果,但具体原因我还不清楚。















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









