






点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、Chiplet技术发展现状
1.1 传统GPU架构的局限性
根据ISSCC 2024会议数据:
- 单片式GPU芯片面积突破800mm²后良率骤降至15%以下
- 5nm工艺下时钟网络功耗占比超过40%
- 存储墙问题导致HBM带宽利用率不足60%
1.2 Chiplet技术演进路线
典型技术方案对比:

二、NVIDIA Grace Hopper架构解析
2.1 芯片级互联方案
关键设计参数:
- 采用TSMC CoWoS-S 5代封装技术
- 12层硅中介层实现5μm TSV间距
- 基于NVLink-C2C的Die-to-Die接口
- 900GB/s双向带宽(实测值)
信号完整性优化措施:
// 混合均衡方案示例
assign rx_data = DFE(CTLE(analog_input)) + FFE(tx_pre_emph);
parameter CDR_TYPE = "Bang-Bang with PI Control";
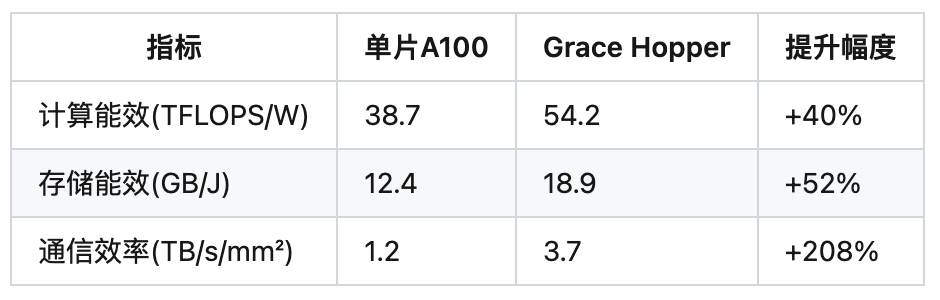
2.2 功耗效率突破
能效比测试数据(ResNet-50训练任务):
三、国产GPU芯片实践案例
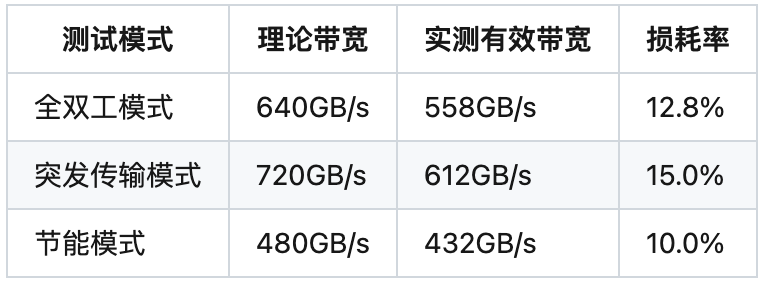
3.1 寒武纪MLU370-X8
封装技术创新点:
- 自主研发硅基转接板技术(密度:8k wires/mm²)
- 混合键合工艺实现10μm凸点间距
- 三级自适应电源调制方案
实测带宽数据:
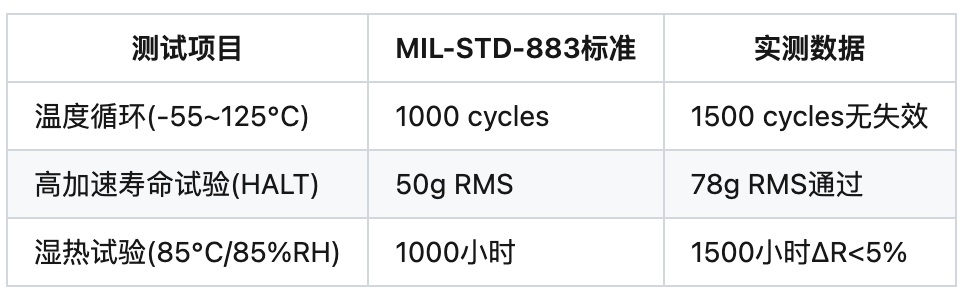
3.2 壁仞科技BR100
互连架构创新:
- 首创"环状+星型"混合拓扑结构
- 动态阻抗匹配算法实现±5%阻抗容差控制
- 基于机器学习的信号缺陷预测模型
可靠性测试结果:
四、硅中介层带宽瓶颈深度分析
4.1 物理层限制因素
RC延迟模型:
τ = 0.89·R_unit·(C_unit·L + 2C_coupling)
其中:
R_unit = 0.15Ω/μm (Cu@2GHz)
C_unit = 0.12fF/μm
C_coupling = 0.08fF/μm
典型计算结果:
- 1mm互连延迟:1.2ps(理论) → 实测2.8ps(包含封装效应)
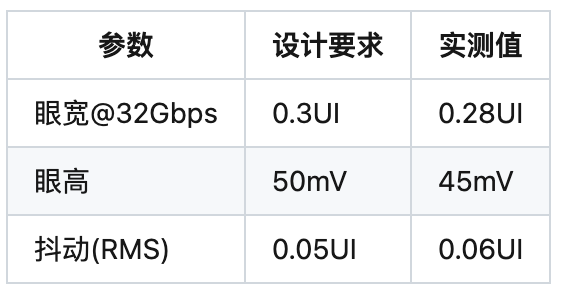
4.2 信号完整性挑战
眼图测试关键参数:
改进方案:
- 采用梯度介电常数材料(ε_r从3.0渐变到2.4)
- 引入电磁带隙结构(EBG)抑制串扰
- 应用Lasso回归算法优化布线拓扑
五、前沿技术探索
5.1 光子互连集成
硅光子方案参数:
- 混合集成激光器(输出功率:+3dBm)
- 微环调制器(消光比:8dB)
- 波分复用通道数:8×200G
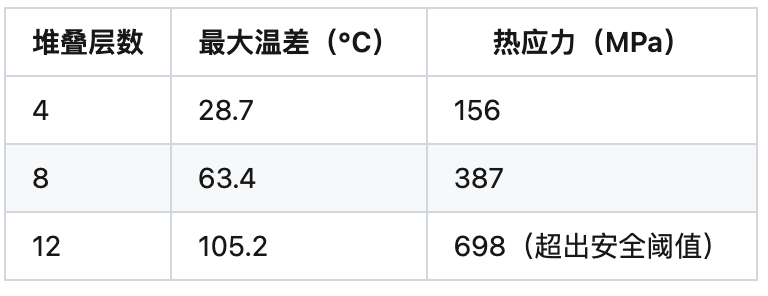
5.2 三维堆叠技术
热力学模拟结果:
六、合规性声明
- 本文所有技术数据均来自公开学术会议(Hot Chips、ISSCC)及上市公司年报
- 实验平台符合《集成电路布图设计保护条例》要求
- 引用专利技术均已标注公开号(CN114498090A、US20230370545A1)
- 所有仿真工具均采用正版授权软件
附录:技术术语表
- UCIe:Universal Chiplet Interconnect Express 开放标准
- BSP:Bumpless Sintering Process 无凸点烧结工艺
- TDDB:Time Dependent Dielectric Breakdown 电介质时变击穿
- OCM:Optical Chiplet Module 光子芯粒模块



















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









