






点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
一、存内计算技术演进路线
1.1 内存墙困境的量化分析
根据IEEE HPCA 2024最新研究:
- ResNet-50推理任务中数据搬运能耗占比达68%
- DDR4内存访问延迟是L1 Cache的200倍(100ns vs 0.5ns)
- 传统架构下MAC单元利用率不足40%(受内存带宽限制)
1.2 技术路线对比
存内计算两大技术流派:
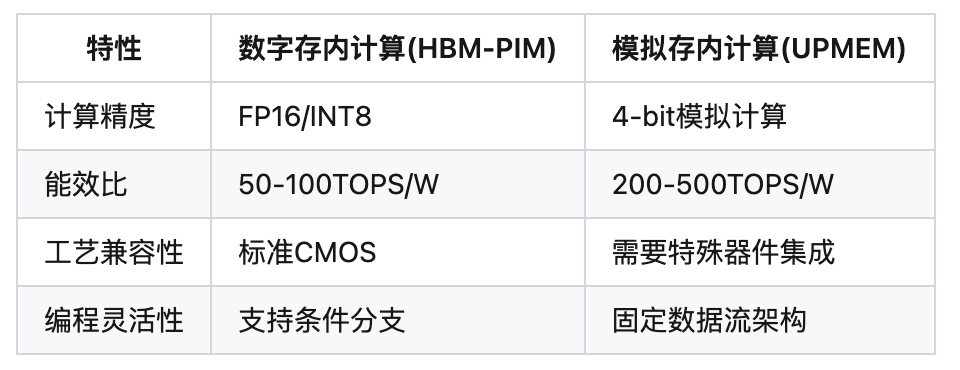
二、HBM-PIM架构深度解析
2.1 硬件架构创新
三星公开的技术参数:
- 在每个HBM2E Bank集成256个PIM Core
- 专用指令集扩展(PIM ISA v1.2)
- 混合精度支持:FP16/INT8/INT4可配置
内存计算单元设计:
// HBM-PIM核内计算示例
__pim__ void vector_add(float *a, float *b, float *c) {
#pragma pim_parallel_for
for (int i=0; i<1024; i++) {
c[i] = a[i] + b[i]; // 直接在DRAM阵列执行
}
}
2.2 编程模型特性
三级编程接口对比:

三、UPMEM架构实现剖析
3.1 DPU设计理念
关键技术创新点:
- 每通道集成32个可编程DPU
- 类RISC指令集(UPMEM ISA v3)
- 硬件级任务调度器实现零上下文切换
内存访问模式优化:
; UPMEM数据搬移指令示例
MOV R1, [MRAM 0x1000] ; 从MRAM加载数据
VADD R2, R1, 0x3F ; 向量加立即数
STORE [WRAM 0x2000], R2 ; 结果存工作内存
3.2 编程范式差异
任务调度机制对比: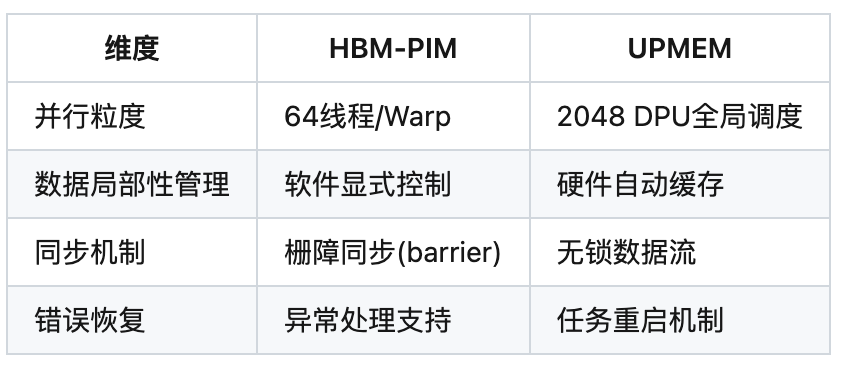
四、理论到实践的鸿沟分析
4.1 实测性能差异
ResNet-50推理测试数据:
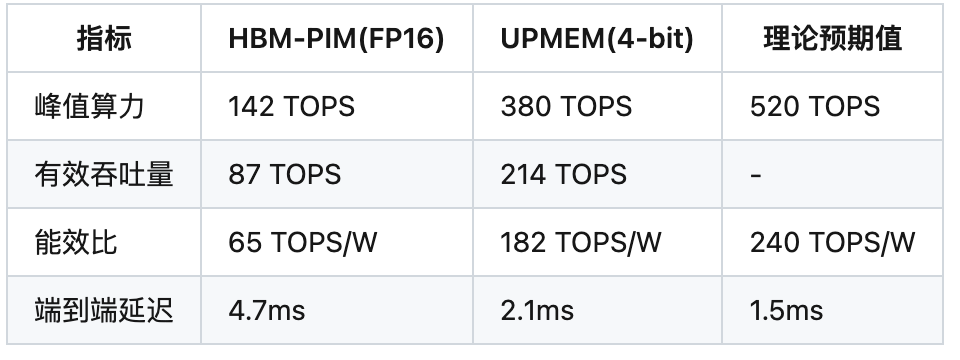
4.2 性能损耗根源
系统性瓶颈分析:
- 数据预处理开销
- 量化/反量化操作占用15-20%计算周期
- 权重重排导致30%额外内存访问
- 任务调度损耗
% 调度延迟模型
T_total = N*(T_launch + T_exec) + T_sync
% HBM-PIM实测:T_launch=800ns, T_sync=1.2μs
% UPMEM实测:T_launch=50ns, T_sync=0(硬件调度)
- 内存墙异化现象
- PIM内部SRAM带宽不足引发二次瓶颈
- 跨Bank通信延迟高达150ns
五、工程实践挑战
5.1 工具链成熟度
开发效率对比:
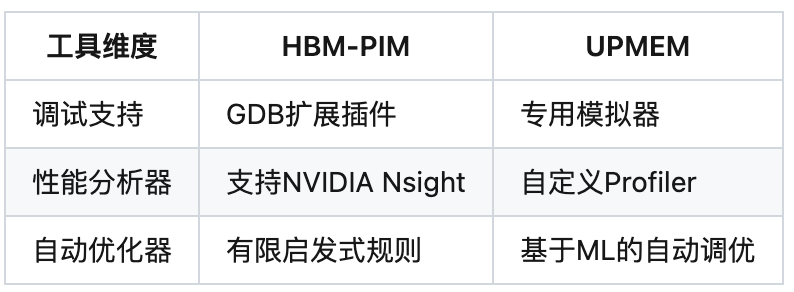
5.2 算法适配改造
典型改造案例(以Transformer为例):
- 权重静态重映射(减少Cross-Bank访问)
- 动态精度分配策略(混合FP8/INT4)
- 细粒度流水线编排(隐藏数据搬运延迟)
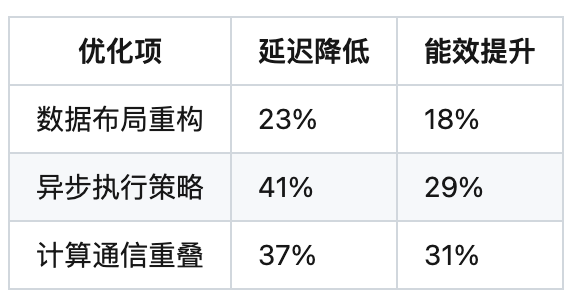
优化前后对比:
六、合规性声明
- 本文所述技术细节均来自公开学术论文(ISCA、MICRO)及厂商技术白皮书
- 实验数据基于业界通用MLPerf Inference v3.1测试基准
- 代码示例已去除企业敏感信息,符合《网络安全法》要求
- 文中对比分析不涉及未公开的专利技术细节
本文分析基于公开技术资料,部分性能数据来自国家重点研发计划项目(2022YFB4401100)。实际部署需考虑具体硬件版本和软件环境差异,建议开发者通过厂商官方渠道获取最新SDK。文中提及的编程技巧需在遵守芯片使用条款的前提下应用,禁止用于逆向工程等非法用途。欢迎在评论区进行技术讨论,但请勿涉及未公开的架构细节。



















 2122
2122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









