






多维剧目网格作为实施数字游戏的图形组织者,以促进学生的学习表现和行为
(A multidimensional repertory grid as a graphic organizer for implementing digital games to promote students’ learning performances and behaviors)
British Journal of Educational Technology(2021) 915–933
一、概念解析
基于数字游戏的学习(Digital game-based learning,简称DGBL):是指以数字技术为学习平台,将学习与人机互动、娱乐化的数字游戏相结合,创造一种寓教于乐的数字游戏式学习环境,使学生逐步完成游戏任务,获得满足感。
多维剧目网格教育游戏(MDRG game):在本研究中,提出了一种多维剧目网格作为角色扮演游戏(RPG)中基于组织者的图形反馈。多维视角的地理观测可以比单角度视角更有效地提供知识。与传统的以文字或数字显示的储备网格技术不同,在本研究中,信息以图形指标的形式呈现在多维储备网格中(如图1所示)。所提出的多维剧目网格是一个网格,其中每一列代表一个学习对象,行是用于描述的属性物体。在图1给出的例子中,提出了三个学习目标,分别是“湿润的亚热带气候”、“干燥的夏季气候”和“温带海洋性气候”,而每个属性都用一个特征来表示,比如夏季温度、雨季、年降水量等等。就属性“雨季”而言,该特征可以是“少雨、冬季、夏季或所有季节”。采用图形化指标来确定学习对象与属性之间的关系。
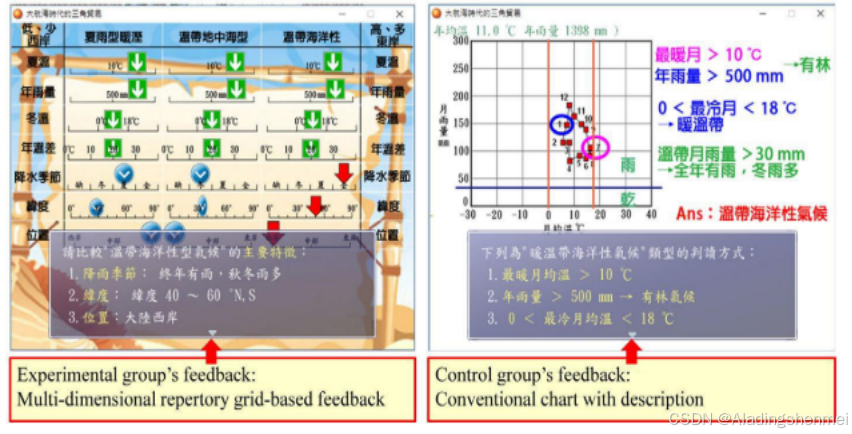
图1:基于多维知识库网格的反馈
二、摘要
研究目的:数字游戏学习(Digital game-based learning, DGBL)是一种常用的促进教学和学习的模式,学习者沉浸在游戏情境中,参与游戏玩法,构建有意义的知识。然而,如果没有指导学生可能难以组织他们在游戏环境中所经历的内容。因此,本研究提出了一种多维存储网格(MDRG)方法,并据此实现了一个数字游戏。
研究对象:本研究采用了一个实验组和一个对照组的准实验设计。参与研究的台湾学生共有83人,分别来自所选城市高中的两个班级,经济背景接近台湾平均水平。学生的平均年龄为15.5岁。这两个班被随机分为实验组和对照组。实验组(EG)包括43名使用MDRG游戏学习的学生,而对照组(CG)包括40名使用没有建议方法的游戏学习的学生。
实验结果:实验组的学习成绩更好,学习动机、自我效能感和元认知意识也更高。此外,行为分析和访谈结果显示,使用所提出策略学习的学生更倾向于促进高阶思维。
三、研究问题
1. 与传统的DGBL相比,MDRG游戏是否能更好地提高学生的学习成就、动机和自我效能感?
2. 与传统的DGBL相比,MDRG游戏是否能更好地增强学生的元认知意识?
3. 与传统的DGBL相比,MDRG游戏是否会降低学生的认知负荷?
四、研究设计
(一)实验工具
1.多维剧目网格教育游戏(MDRG游戏)
在本研究中,提出了一个多维剧目网格作为角色扮演游戏(RPG)中基于组织者的图形反馈。游戏环境由基于数字游戏的学习机制(见图2)组成,其中包括地理游戏模块、评分模块和学习行为输入模块,以及基于多维剧目网格的反馈机制,其中包括多维剧目网格查看和编辑模块。地理游戏模块显示游戏内容任务,其中得分模块和学习行为输入模块存储学生在游戏中的分数和学习日志。由经验丰富的地理教师和专家编辑的多维剧目网格作为反馈提供给学生。在游戏过程中,学生与非玩家的游戏角色互动,完成学习任务,获得分数,获得反馈,最终在游戏中获得地理知识。随后,教师和研究人员对学习行为进行了进一步分析。
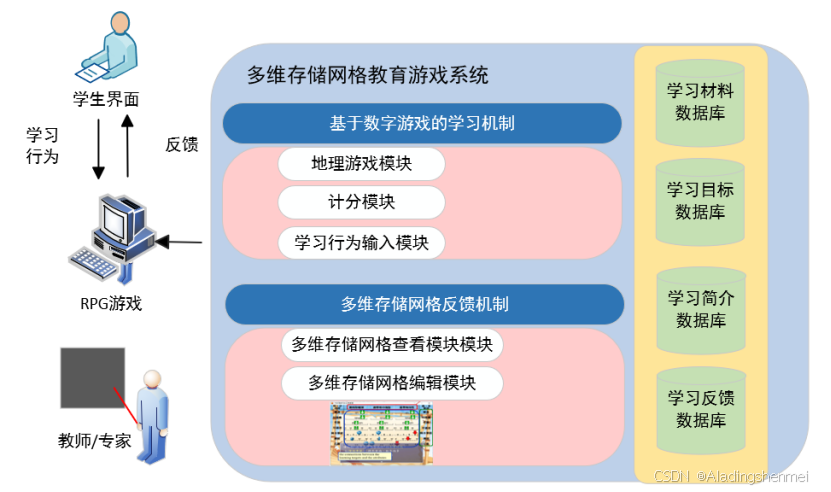 图2:MDRG游戏系统结构
图2:MDRG游戏系统结构
2.测量工具
学习成就(Learning Achievement):通过全球气候分类测试的分数来衡量学生的学习成就。
预测试包括20个多项选择题(40%)、20个填空题(40%)和10个简答题(20%),总分为100分。后测试包括20个多项选择题(40%)、20个多项选择题(40%)和10个简答题(20%),用于评估不同全球气候特征的高阶思维比较和分析,总分为100分。
学习动机(Learning Motivation):使用基于Pintrich等人(1991)提出的量表修改而成的学习动机问卷,包含六个项目,采用5点李克特式评分。
自我效能(Self-efficacy):使用基于Pintrich等人(1991)提出的量表修改而成的自我效能问卷,包含七个项目,采用5点李克特式评分。
元认知意识(Metacognition Awareness):使用基于Lai和Hwang(2014)提出的量表修改而成的元认知意识问卷,包含五个项目,采用5点李克特式评分。
认知负荷(Cognitive Load):
使用基于Hwang等人(2013)提出的量表修改而成的认知负荷问卷,包含八个项目,采用7点李克特式评分,包括五个心理负荷项目和三个心理努力项目。
学习行为模式(Learning Behavioral Patterns):根据研究中的游戏特点开发了编码方案,共有13种行为代码,每种代码代表一种游戏行为。游戏系统自动记录所有游戏行为,无需手动编码。
访谈(Interviews):在游戏活动和后测试后进行半结构化访谈,询问七个开放式问题。根据学生的地理学习成就,从两组中各选出四名高成就和四名低成就的学生进行访谈,共访谈了16名学生。所有访谈都被记录下来。
(二)实验对象和方法
本研究采用了一个实验组和一个对照组的准实验设计。参与研究的台湾学生共有83人,分别来自所选城市高中的两个班级,经济背景接近台湾平均水平。学生的平均年龄为15.5岁。这两个班被随机分为实验组和对照组。实验组(EG)包括43名使用MDRG游戏学习的学生,而对照组(CG)包括40名使用没有建议方法的游戏学习的学生。
(三)实验过程
图3显示了实验流程,实验进行了三周。第一周,老师进行了200分钟的全球气候基础知识讲座。之后,学生完成了70分钟的预测和预问卷。第二周,EG使用MDRG游戏学习,CG使用传统教育游戏学习,时间为150分钟。第三周,学生完成后测和问卷后测,共耗80分钟;此外,还进行了60分钟的访谈。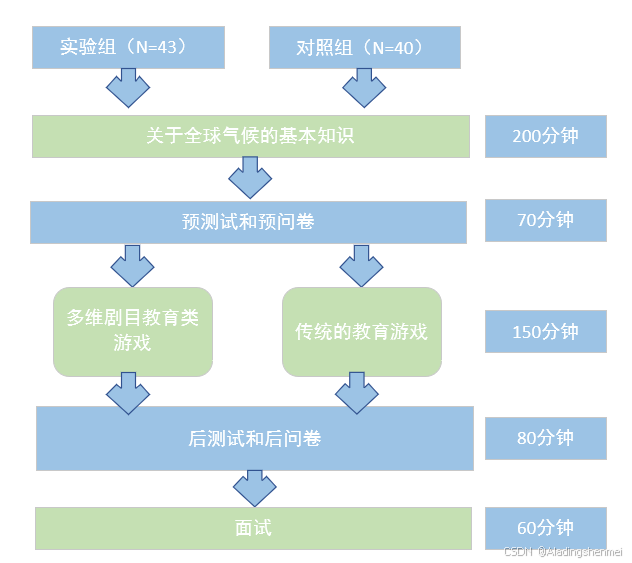
图3 实验流程
五、研究结果
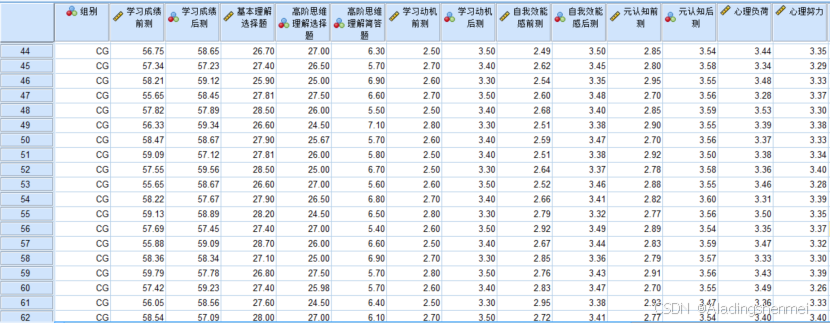
-
(一)学习成绩分析
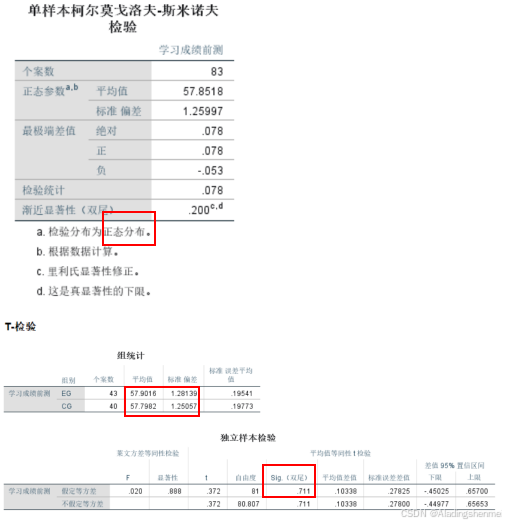
- 根据上图独立样本t检验分析显示,p=0.71>0.05,学习成绩前测不存在显著差异,表明两组学生在学习活动前具有相当的先验知识水平。

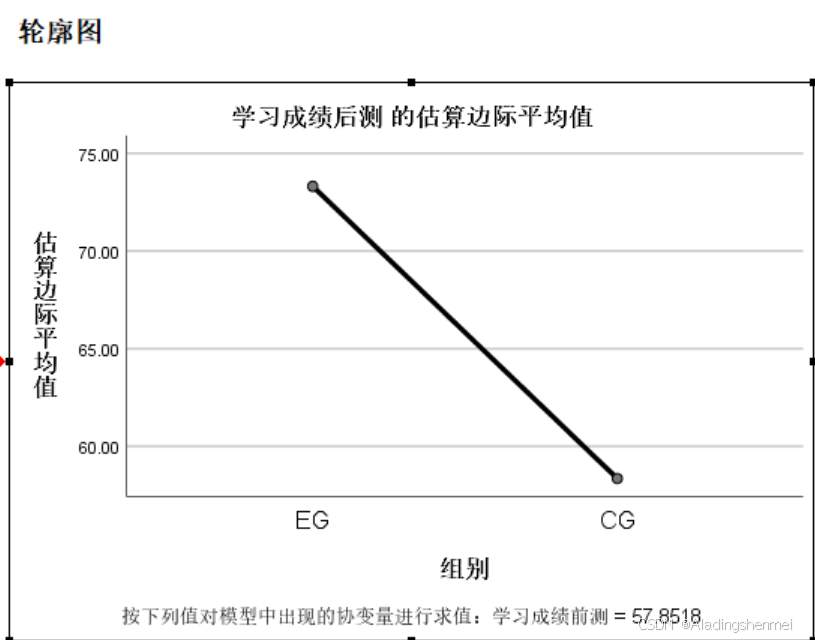
-
组别
N
M
SD
F
EG
43
73.30
2.37
723.2
CG
40
58.36
0.76
-
表1 学习成绩后测协方差分析结果
-
为了评估采用ANCOVA是否合适,我们首先进行了同质性检验。确认回归齐性假设通过(F=0.91, p >0.05)。然后进行ANCOVA,以前测成绩为协变量,后测成绩为因变量,剔除问卷前评分的影响,采用协方差分析(ANCOVA)检验两组间的差异,如表1所示。结果显示(p < 0.05),两组间差异有统计学意义;也就是说:在学习成绩方面,使用MDRG游戏学习的学生比使用传统教育游戏学习的学生表现得更好。
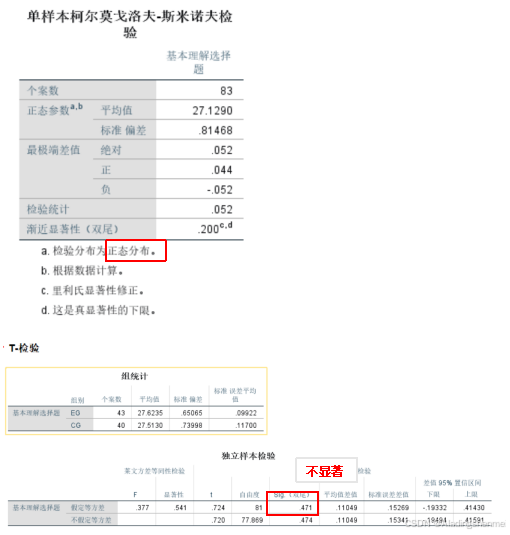
-
根据t检验结果,EG和CG的“基本理解选择题”得分均值和标准差分别为27.62和0.65,CG得分均值和标准差分别为27.51和0.74。两组间差异无统计学意义(t=0.72,p= 0.47>0.05)。
-
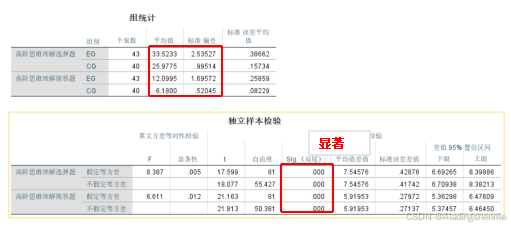
-
在“高阶思维理解选择题”方面,EG组的平均值和标准差分别为33.52和2.54,CG组的平均值和标准差分别为25.97和1.01。该结果暗示两组之间存在统计学差异(p= 0.000 <0 .05)。在“高阶思维理解简答题”方面,EG组的平均值和标准差分别为12.10和1.70,CG组的平均值和标准差分别为6.18和0.52。结果暗示两组之间存在统计学差异( p=0.000 < 0.05)。也就是说,在高阶思维理解方面,使用MDRG游戏学习的学生比使用传统教育游戏学习的学生表现得更好。
-
(二)学习动机分析
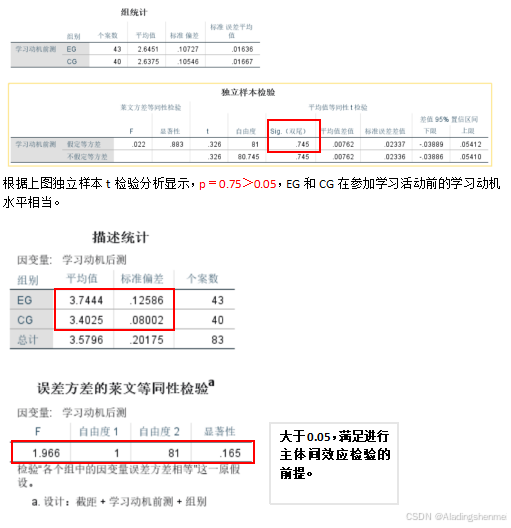
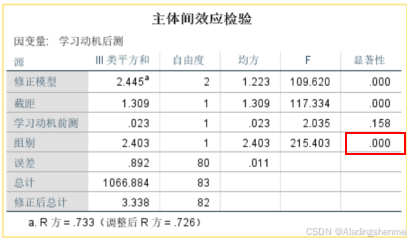
组别
N
M
SD
F
EG
43
3.74
0.13
109.6
CG
40
3.40
0.08
-
表2 两组学生学习动机的协方差分析结果
为了评估采用ANCOVA是否合适,我们首先进行了同质性检验。确认回归齐性假设通过(F=1.97, p >0.05)。然后进行ANCOVA,以前测成绩为协变量,后测成绩为因变量,剔除问卷前评分的影响,采用协方差分析(ANCOVA)检验两组间的差异,如表2所示。结果显示(p < 0.05),两组间差异有统计学意义;也就是说:在学习动机方面,使用多维贮存网格MDRG游戏学习的学生比使用传统教育游戏学习的学生表现得更好。
-
(三)自我效能感分析
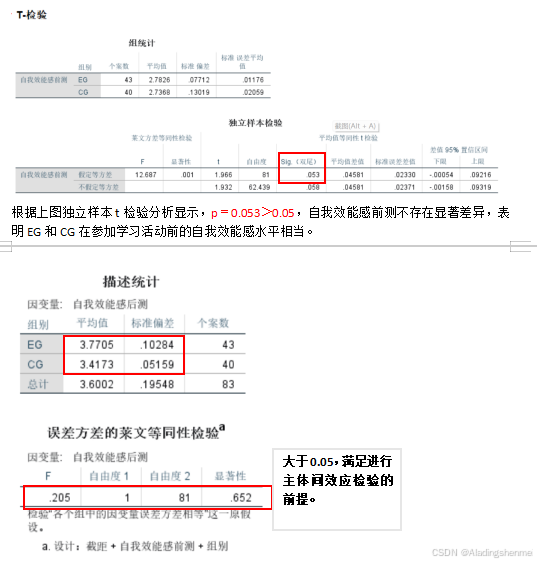
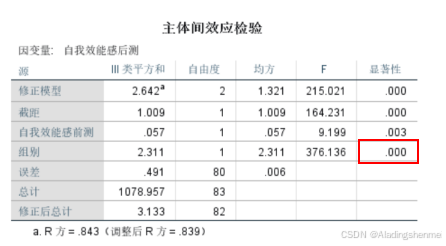
-
组别
N
M
SD
F
EG
43
3.77
0.10
215.02
CG
40
3.42
0.05
-
表3 两组学生自我效能感的协方差分析结果
为了评估采用ANCOVA是否合适,我们首先进行了同质性检验。确认回归齐性假设通过(F=0.20, p >0.05)。然后进行ANCOVA,以前测成绩为协变量,后测成绩为因变量,剔除问卷前评分的影响,采用协方差分析(ANCOVA)检验两组间的差异,如表2所示。结果显示(p < 0.05),两组间差异有统计学意义;也就是说:在自我效能感方面,采用多维贮存网格(MDRG)游戏的学生展现出比传统教育游戏更高的自我效能感.
-
(四)元认知分析
-
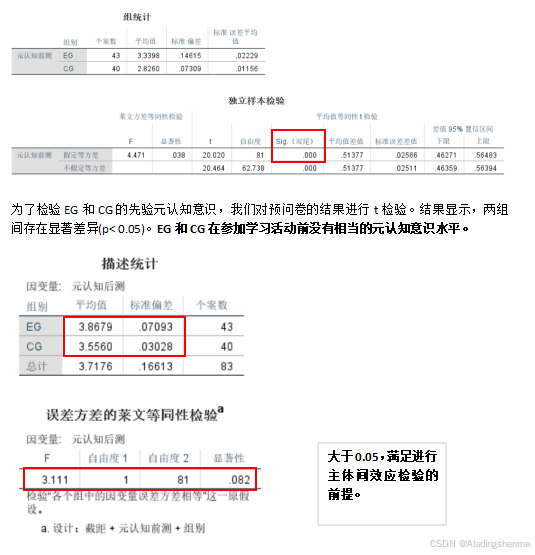
-
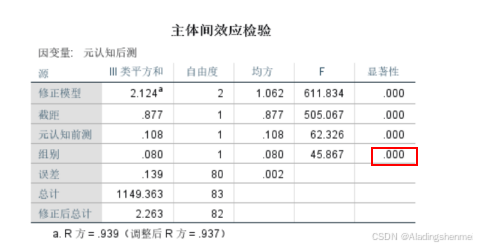
组别
N
M
SD
F
EG
43
3.87
0.07
611.83
CG
40
3.56
0.03
-
表4 两组学生元认知的协方差分析结果
虽然t检验显示两组在参加学习活动前的元认知意识水平不相等,但ANCOVA结果显示了去除协变量(元认知意识前问卷得分)的影响后自变量的影响。如表4所示。结果显示(p < 0.05),两组间差异有统计学意义;也就是说:在元认知方面,采用多维剧目网格(MDRG)游戏的学生展现出比传统教育游戏更高的元认知.
-
(五)认知负荷分析
-
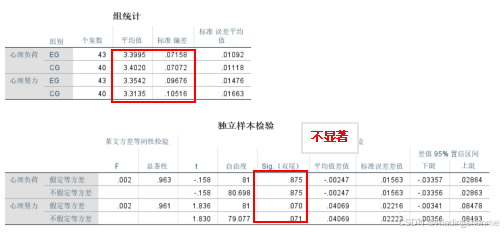
-
本研究采用t检验调查两组在认知负荷方面的差异,包括“心理负荷”和“心理努力”。结果显示,两组间差异无统计学意义(p >0.05)。
-
(六)访谈结果
-
根据半结构化访谈的结果,学生们指出了MDRG游戏的主要优势,即“提高学习效率”和“促进高阶思维技能”。
在“提高学习效率”方面,8名EG学生中有7人认为MDRG游戏不仅提供了快乐的学习环境,而且还提高了他们的学习效率。
在“提升高阶思维技能”方面,8名EG学生中有6名表示,基于多维储备网格的反馈不仅帮助他们发现了细节,而且还帮助他们发现了知识,他们通常忽略的气候差异的特征,也帮助他们系统地组织信息,这使得他们更容易分析和比较。
相比之下,CG组的学生没有提到比较或反思等更高层次的思维技能。虽然传统的教育游戏在CG中为学生提供了传统的图形或表格,但这种反馈模式倾向于帮助学生提高低阶思维能力,如记忆和理解。例如,6名CG学生表示,在游戏环境中学习使他们能够很好地记住学习内容。因此,基于多维剧目网格的反馈帮助学生更高效、更彻底地学习,甚至提升了他们的高阶思维能力。
六、结论
从研究问题总结而得:
本研究探讨了使用多维贮存网格(MDRG)游戏与传统教育游戏在提升学生学习成效方面的差异。结果显示,MDRG游戏组的学生在学习行为上更为积极,且在高阶思维问题上表现更佳,而传统游戏组的学生则主要在记忆和理解方面有所提升。MDRG游戏通过提供系统化的信息,促进了学生的反思和比较,从而增强了学习效率和高阶思维能力。此外,MDRG游戏还提高了学生的学习动机和自我效能感,而没有增加认知负荷。研究的局限性在于样本量小且仅限于台湾高中十年级学生,因此建议未来研究应扩大样本范围并进行长期实验。后续研究可考虑将MDRG方法应用于其他学科的教育游戏开发,以提升学生的综合学习成效和高阶思维技能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









