







模块二:招聘网站数据分析
目录
1.1 清理关键数据缺失的条目--v_data_clean_null
1.2 数据去重--v_clean_data_distinct
1.3 保留特定数据--v_data_clean_workplace
1.4 保留特定职位信息--v_data_clean_jobname
2.1 不同城市的市场需求量--v_data_market_demand
2.2 不同企业的需求量以及占总需求量的比例--v_data_companytype_degree
2.3 岗位薪资(5-8千/月——>5k 8k)--v_data_salary_unit
1 数据准备
1.1 清理关键数据缺失的条目--v_data_clean_null
CREATE VIEW v_data_clean_null AS SELECT
*
FROM
DATA
WHERE
/* 字段不为空也不为null */
job_href IS NOT NULL
AND job_href != ''
AND job_name IS NOT NULL
AND job_name != ''
AND company_href IS NOT NULL
AND company_href != ''
AND company_name IS NOT NULL
AND company_name != ''
AND providesalary_text IS NOT NULL
AND providesalary_text != ''
AND workarea IS NOT NULL
AND workarea != ''
AND workarea_text IS NOT NULL
AND workarea_text != ''
AND companytype_text IS NOT NULL
AND companytype_text != ''
AND degreefrom IS NOT NULL
AND degreefrom != ''
AND workyear IS NOT NULL
AND workyear != ''
AND updatedate IS NOT NULL
AND updatedate != ''
AND issuedate IS NOT NULL
AND issuedate != ''
AND parse2_job_detail IS NOT NULL
AND parse2_job_detail != '';
1.2 数据去重--v_clean_data_distinct
同一公司的同一职位可能会占据多个条目,因为这些职位的工作地点不同,而此时仅保留该职位的第一个条目。因为我们要比较的是不同职位的数据,即使是不同地点的职位,它们还是属于同一职位。
* 这里注意with as的用法
* 利用窗口函数进行排序
-- 1-2 对公司和职位进行去重,保留这个公司在这个职位上发布的最新招聘数据
/*
思路1:按公司、职位进行分组(窗口函数),按照日期进行降序排列(row_num 否则会并列)
*/
-- 分组排序
CREATE VIEW v_clean_data_distinct AS
WITH p AS
(
SELECT
*,
row_number ( ) over ( PARTITION BY company_name, job_name ORDER BY issuedate DESC ) AS row1
FROM
v_data_clean_null
)
SELECT
id,
job_href,
job_name,
company_href,
company_name,
providesalary_text,
workarea,
workarea_text,
updatedate,
companytype_text,
degreefrom,
workyear,
issuedate,
parse2_job_detail
FROM
p
WHERE
row1 =11.3 保留特定数据--v_data_clean_workplace
-- like 模糊查询
-- case when 条件分支
create view v_data_clean_workplace as
WITH p AS (
SELECT
*,
(
CASE
WHEN workarea_text LIKE '%北京%' THEN
'北京'
WHEN workarea_text LIKE '%上海%' THEN
'上海'
WHEN workarea_text LIKE '%广州%' THEN
'广州'
WHEN workarea_text LIKE '%深圳%' THEN
'深圳'
END
) AS workplace
FROM
v_clean_data_distinct
)
SELECT
*
FROM
p
WHERE
workplace IS NOT NULL
1.4 保留特定职位信息--v_data_clean_jobname
对关键词进行检验。通常我们不能一次性得到二次过滤所需要的关键词,那就需要多尝试一些关键词。
比如在这里v1涵盖的数据要比v2广,进一步检索那些数据在v1中,我们就知道这样设置条件是否合理。
-- 检验数据的检索关键词是否合理?
DROP VIEW
IF
EXISTS v1
CREATE VIEW v1 AS SELECT
*
FROM
v_data_clean_workplace
WHERE
job_name LIKE '%数据%'
OR ( job_name LIKE '%市场%' AND job_name LIKE '%分析%' )
CREATE VIEW v2 AS SELECT
*
FROM
v_data_clean_workplace
WHERE
job_name LIKE '%数据%'
-- 选出在v1但不在v2的数据
select * from v1
where v1.id not in (select id from v2)经过检验,最后实际采用代码
-- 实际采用代码
CREATE VIEW v_data_clean_jobname AS SELECT
*
FROM
v_data_clean_workplace
WHERE
job_name LIKE '%数据%';
-- 有多少条数据?
select count(*) from v_data_clean_jobname1.5 将查询结果保存到新视图--v_data_clean
CREATE VIEW v_data_clean AS ( SELECT * FROM v_data_clean_jobname );2 具体数据查询
2.1 不同城市的市场需求量--v_data_market_demand
CREATE VIEW v_data_market_demand AS
SELECT
workplace AS '城市',
sum( degreefrom ) AS '招聘总数',# degreefrom 招聘岗位数
count( * ) AS '职位数目'
FROM
v_data_clean
GROUP BY
workplace;
SELECT
*
FROM
v_data_market_demand;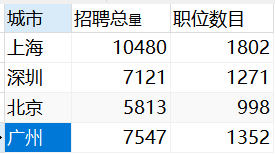
2.2 不同企业的需求量以及占总需求量的比例--v_data_companytype_degree
利用拼接函数显示百分数
-- f1 各个企业的招聘数 f2 一线城市的招聘总数
CREATE VIEW v_data_companytype_degree AS
SELECT
companytype_text AS '企业类型',
degreefrom AS '招聘量',
concat( cast( degreefrom / sum_degreefrom * 100 AS DECIMAL ( 4, 2 ) ), '%' ) AS '招聘量占比'
FROM
(
-- 不同企业所提供的的岗位数
SELECT
companytype_text, -- 企业类型
sum( degreefrom ) AS degreefrom -- degreefrom 各公司招聘岗位数
FROM
v_data_clean
GROUP BY
companytype_text
ORDER BY
degreefrom DESC
)f1,
(
-- 企业提供的岗位数之和
SELECT
sum( degreefrom ) AS sum_degreefrom -- 招聘总岗位数
FROM
v_data_clean
)f2
2.3 岗位薪资(5-8千/月——>5k 8k)--v_data_salary_unit
step1:根据不同的薪资的单位得到unit列,便于之后相乘
CREATE VIEW v_data_salary_unit AS
SELECT
*,
(
CASE
WHEN providesalary_text LIKE '%万/月' THEN
10000
WHEN providesalary_text LIKE '%千/月' THEN
1000
WHEN providesalary_text LIKE '%万/年' THEN
833 # 10000/12
END
) AS unit
FROM
v_data_clean
step2:得到工资区间最小值、最大值与均值--v_data_salary_min_max_mean
SUBSTRING_INDEX(str,delim,count)
str:待切分字符串
delim:按什么符号进行切分
count:1取切分后的第1个字符串 -1为最后一个
cast 字符串 as decimal(m,n)
m是数据位数
n是小数位数
5-8千/月——》5-8——》5 - 8
-- 试验分割条件
SELECT
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '千/月', 1 ), '-', 1 ) AS DECIMAL ( 6, 2 ) ) * unit AS salary_min, -- 最小薪资
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '千/月', 1 ), '-',- 1 ) AS DECIMAL ( 6, 2 ) ) * unit AS salary_max
FROM
v_data_salary_unit
LIMIT 1CREATE VIEW v_data_salary_min_max_mean AS
WITH p AS (
SELECT
*,
-- 对单位进行判断,然后按照同样的套路进行转换
(
CASE
WHEN unit = 1000 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '千/月', 1 ), '-', 1 ) AS DECIMAL ( 6, 2 ) ) * unit
WHEN unit = 10000 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '万/月', 1 ), '-', 1 ) AS DECIMAL ( 6, 2 ) ) * unit
WHEN unit = 833 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '万/年', 1 ), '-', 1 ) AS DECIMAL ( 6, 2 ) ) * unit
END
) AS salary_min,
(
CASE
WHEN unit = 1000 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '千/月', 1 ), '-', - 1 ) AS DECIMAL ( 6, 2 ) ) * unit
WHEN unit = 10000 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '万/月', 1 ), '-', - 1 ) AS DECIMAL ( 6, 2 ) ) * unit
WHEN unit = 833 THEN
cast( SUBSTRING_INDEX( SUBSTRING_INDEX( providesalary_text, '万/年', 1 ), '-', - 1 ) AS DECIMAL ( 6, 2 ) ) * unit
END
) AS salary_max
FROM
v_data_salary_unit
)
SELECT
*,
( salary_min + salary_max ) / 2 AS salary_mean
FROM
p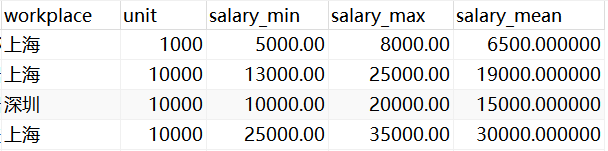
step3:按工作年限分组,求各组平均薪资--v_data_workyear_salary
CREATE VIEW v_data_workyear_salary AS
SELECT
workyear AS '工作年限',
avg( salary_mean ) AS '平均薪资'
FROM
v_data_salary_min_max_mean
GROUP BY
workyear
ORDER BY
length( workyear ),
workyear -- workyear 是字符串,直接排列的话10跟在1后面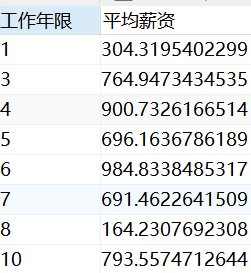
3 统计各个技能点需求度
3.1 显式内连接
SELECT
*
FROM
skill_table AS st
INNER JOIN v_data_clean AS v ON v.parse2_job_detail LIKE concat( '%', st.skill, '%' )
3.2 不同技能点涉及的岗位数
-- 3-2 统计行数
-- drop view if EXISTS v_data_companytype_salary
CREATE VIEW v_data_skill_quantity AS
SELECT
skill,
count( * ) AS quantity
FROM
skill_table AS st
INNER JOIN v_data_clean AS v ON v.parse2_job_detail LIKE concat( '%', st.skill, '%' )
GROUP BY
st.skill
ORDER BY
quantity DESC
LIMIT 30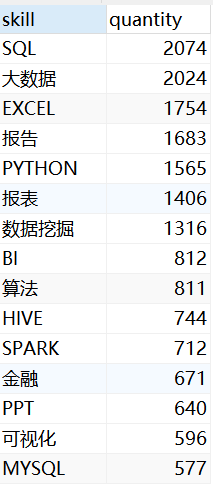
3.3 已知岗位数统计频率
-- 3-3 统计频率
SELECT
skill AS '技能点',
quantity AS '出现频数',
concat( cast( quantity / total_quantity * 100 AS DECIMAL ( 4, 2 ) ), '%' ) AS '出现频率'
FROM
v_data_skill_quantity AS f1,
( SELECT count( * ) AS total_quantity FROM v_data_clean ) f2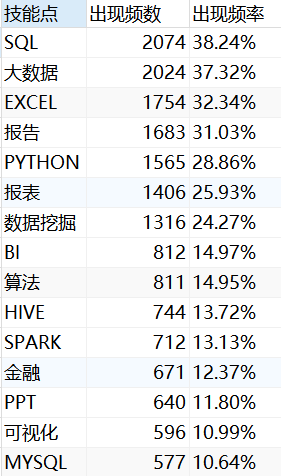















 5632
5632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









